scrapy爬蟲框架中資料庫(mysql)的非同步寫入
阿新 • • 發佈:2018-12-09
####資料庫的非同步寫入
scrapy爬蟲框架裡資料庫的非同步寫入與同步寫入在程式碼上的區別也就在pipelines.py檔案和settings.py問價的區別,其他的都是一樣的。本文就介紹一下pipelines.py和settings.py檔案裡面是如何配置的。
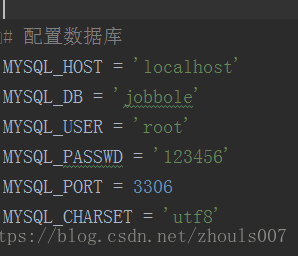
1、先到settings.py檔案裡面配置資料庫的相關欄位
2、先在pipelines.py檔案裡面匯入相關模組
import pymysql from scrapy.pipelines.images import ImagesPipeline # twisted: 用於非同步寫入(包含資料庫)的框架,cursor.execute()是同步寫入 from twisted.enterprise import adbapi
3、資料庫寫入部分程式碼如下:
要在from_settings這個類方法裡面寫上載入配置資料的程式碼
然後建立一個數據庫連線池物件,裡面可以包含多個connect連線物件
class MySQLTwistedPipeline(object): def __init__(self, pool): self.dbpool = pool @classmethod def from_settings(cls, settings): """ 這個函式名稱是固定的,當爬蟲啟動的時候,scrapy會自動呼叫這些函式,載入配置資料。 :param settings: :return: """ params = dict( host=settings['MYSQL_HOST'], port=settings['MYSQL_PORT'], db=settings['MYSQL_DB'], user=settings['MYSQL_USER'], passwd=settings['MYSQL_PASSWD'], charset=settings['MYSQL_CHARSET'], cursorclass=pymysql.cursors.DictCursor ) # 建立一個數據庫連線池物件,這個連線池中可以包含多個connect連線物件。 # 引數1:操作資料庫的包名 # 引數2:連結資料庫的引數 db_connect_pool = adbapi.ConnectionPool('pymysql', **params) # 初始化這個類的物件 obj = cls(db_connect_pool) return obj def process_item(self, item, spider): """ 在連線池中,開始執行資料的多執行緒寫入操作。 :param item: :param spider: :return: """ # 引數1:線上程中被執行的sql語句 # 引數2:要儲存的資料 result = self.dbpool.runInteraction(self.insert, item) # 給result繫結一個回撥函式,用於監聽錯誤資訊 result.addErrback(self.error) def error(self, reason): print('--------', reason) # 線面這兩步分別是資料庫的插入語句,以及執行插入語句。這裡把插入的資料和sql語句分開寫了,跟何在一起寫效果是一樣的 def insert(self, cursor, item): insert_sql = "INSERT INTO bole(bole_title, bole_date, bole_tag, bole_content, bole_dz, bole_sc, bole_pl, bole_img_src) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)" cursor.execute(insert_sql, (item['bole_title'], item['bole_date'], item['bole_tag'], item['bole_content'], item['bole_dz'], item['bole_sc'], item['bole_pl'], item['bole_img_path'])) # 不需要commit()
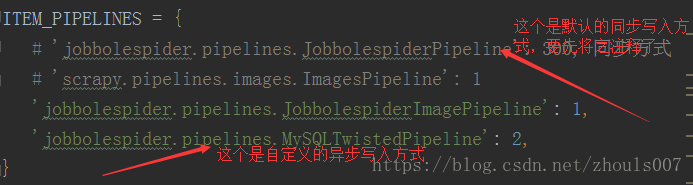
4、也就是最後一步了,在settings.py檔案裡面,先將系統預設的同步寫入的方式給註釋了,然後再寫入自己自定義的非同步寫入方式,不然pipeline.py檔案裡面寫的非同步寫入就執行不了了