
ML.NET 0.8特性簡介
本週.NET生態圈內的更新源源不斷,除了.NET Core 2.2,ASP.NET Core 2.2和Entity Framework Core 2.2之外,ML.NET 0.8也一併登上舞臺。
新的推薦場景
ML.NET使用基於矩陣分解(Matrix Factorization)和場感知分解機(Field-aware Factorization Machine)的方法來作推薦。一般而言,場感知分解機是矩陣分解更通用的例子,它允許傳入額外的元資料。
在ML.NET 0.8中新加了運用矩陣分解的推薦場景。
| 推薦場景 | 推薦方案 | 示例連結 |
|---|---|---|
| 基於產品Id,評價,使用者Id和諸如產品描述,使用者特徵(年齡,國家)的額外元資料的產品推薦 | 場感知分解機 | ML.NET 0.3 |
| 基於產品Id,評價,使用者Id的產品推薦 | 矩陣分解 | ML.NET 0.7 |
| 基於產品Id和與其一同購買的產品Id的產品推薦 | One Class矩陣分解 | ML.NET 0.8 |
在新的推薦場景中,即使沒有可用的評價,也可以通過歷史購買資料為使用者構建"經常一起購買的產品"(Frequently Bought Together)的列表。
通過預覽資料改進除錯功能
在多數例子裡,當開始執行你的機器學習管道(pipeline),且載入資料時,能看到已經載入的資料是很有用的功能。尤其是在某些中間轉換過程之後,需要確保資料如預期的一樣發生變化。
現在當你想要預覽DataView的資料模式(Schema)時,可以懸停滑鼠在IDataView物件上,展開它,觀察它的資料模式屬性。
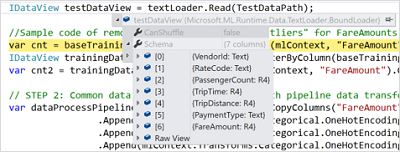
而要檢視DataView中已載入的實際資料,通過以下三步可以達成目標。
- 在除錯模式中開啟觀察視窗
- 輸入DataView物件的變數名,呼叫它的Preview方法
- 點開想看的某行,這樣就能顯示其中實際載入的資料
預設情況下,只會顯示100行的資料,但可以在Preview方法裡傳入引數,比如Preview(500),以獲得更多的資料。
模型可解釋性
為了讓模型更具可解釋性,ML.NET 0.8引入了新的API,用以幫助理解模型的特徵重要性(整體特徵重要度(Overall Feature Importance))以及建立能被其他人解釋的高效模型(廣義加性模型(Generalized Additive Models))。
整體特徵重要度用於評判在模型中哪些特性是整體上最重要的。它幫助理解哪些特徵是最有價值的,從而得到更好的預測結果。例如,當預測汽車價格時,一些特性比如里程數和生產商品牌是更重要的,而其它特性,如汽車顏色,則是影響甚小。
模型的整體特徵重要度可以通過"排列特徵重要度"(Permutation Feature Importance)(PFI)技術來獲得。PFI藉由"如果特徵值設為隨機數,會怎樣影響模型"這一問題以測量特徵重要度。
PFI方法的好處是其與模型無關,任何模型都可以用它作評估,並且它還可以使用任意資料。
使用PFI的方法如下例程式碼所示:
// Compute the feature importance using PFI
var permutationMetrics = mlContext.Regression.PermutationFeatureImportance(model, data);
// Get the feature names from the training set
var featureNames = data.Schema.GetColumns()
.Select(tuple => tuple.column.Name) // Get the column names
.Where(name => name != labelName) // Drop the Label
.ToArray();
// Write out the feature names and their importance to the model's R-squared value
for (int i = 0; i < featureNames.Length; i++)
Console.WriteLine($"{featureNames[i]}\t{permutationMetrics[i].rSquared:G4}");生成的結果包括了特徵名與它的重要度。
Console output:
Feature Model Weight Change in R - Squared
--------------------------------------------------------
RoomsPerDwelling 50.80 -0.3695
EmploymentDistance -17.79 -0.2238
TeacherRatio -19.83 -0.1228
TaxRate -8.60 -0.1042
NitricOxides -15.95 -0.1025
HighwayDistance 5.37 -0.09345
CrimesPerCapita -15.05 -0.05797
PercentPre40s -4.64 -0.0385
PercentResidental 3.98 -0.02184
CharlesRiver 3.38 -0.01487
PercentNonRetail -1.94 -0.007231廣義加性模型擁有很好的預測可解釋性。在便於理解上,它類似於線性模型,但更加靈活,並具有更佳的效能以及利於分析的視覺化能力。
更多的API增強
在DataView中過濾行
有時你會需要對資料集過濾一部分資料,比如那些離群值(outlier)。ML.NET 0.8中新加入了FilterByColumn()API可以幫助解決類似問題。
使用方法如下面的程式碼所示:
IDataView trainingDataView = mlContext.Data.FilterByColumn(baseTrainingDataView, "FareAmount", lowerBound: 1, upperBound: 150);快取功能的API
當對同一資料作多次迭代處理時,通過快取資料可以大幅減少訓練時間。
以下例子可以減少50%的訓練時間:
var dataProcessPipeline = mlContext.Transforms.Conversion.MapValueToKey("Area", "Label")
.Append(mlContext.Transforms.Text.FeaturizeText("Title", "TitleFeaturized"))
.Append(mlContext.Transforms.Text.FeaturizeText("Description", "DescriptionFeaturized"))
.Append(mlContext.Transforms.Concatenate("Features", "TitleFeaturized", "DescriptionFeaturized"))
//Example Caching the DataView
.AppendCacheCheckpoint(mlContext)
.Append(mlContext.BinaryClassification.Trainers.AveragedPerceptron(DefaultColumnNames.Label,
DefaultColumnNames.Features,
numIterations: 10));以IDataView二進位制格式儲存讀取資料
將經過轉換的資料儲存為IDataView二進位制格式相較普通的文字格式,可以極大地提升效率。同時,由於此格式保留了資料模式,所以可以方便讀取而不需要再指定列型別。
讀取與儲存的API如下所示,十分簡單:
mlContext.Data.ReadFromBinary("pathToFile");
mlContext.Data.SaveAsBinary("pathToFile");用於時間序列問題的狀態性預測引擎
ML.NET 0.7裡可以基於時間序列處理異常檢查問題。然而,其預測引擎是無狀態的,這意味著每次要指出最新的資料點是否是異常的,需要同時提供歷史資料。
新的引擎中可以保留時間序列的狀態,所以現在只要有最新的資料點,即可以進行預測。需要改動的地方是將CreatePredictionFunction()方法替換成CreateTimeSeriesPredictionFunction()。