
【K折交叉驗證】K值到底如何選擇?
引言
想必做機器學習的,都不同程度的用過交叉驗證(cross validation),通常使用交叉驗證評估一個機器學習模型的表現。交叉驗證有很長的歷史,但交叉驗證的研究有不少待解決的問題。就交叉驗證的K值選取來講,可能一部分人不加思考,只是泛泛的使用常規的10折,也可能一部分人思考過,但仍然會困惑。那麼K值取多少合適呢?
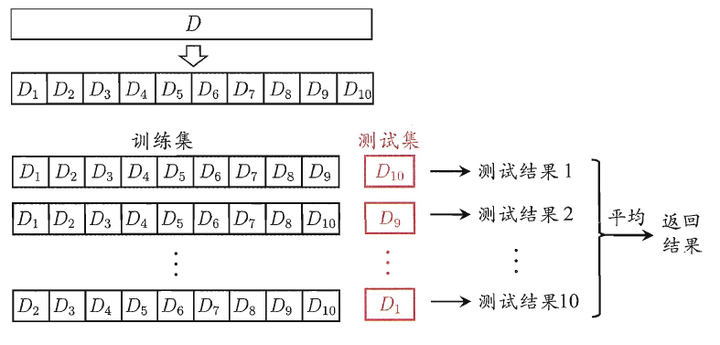
10折交叉驗證(圖片來源: 周志華, 機器學習, 清華大學出版社, 2016)
一、K折交叉驗證的實際目的
既然討論K值的選取,交叉驗證的概念就不再贅述,但必須清楚為什麼要用交叉驗證。
1、根本原因:資料有限,單一的把資料都用來訓練模型,容易導致過擬合。
(反過來,如果資料足夠多,完全可以不適用交叉驗證)
2、理論上:使用了交叉驗證,模型方差“應該”降低了。
在理想情況下,我們認為K折交叉驗證可以 的效率降低模型的方差,從而提高模型的泛化能力,通俗地說,我們期望模型在訓練集的多個子資料集上表現良好,要勝過單單在整個訓練資料集上表現良好。(但實際上,由於我們所得到K折資料之間並非獨立而存在相關性,K折交叉驗證到底能降低多少方差還不確定,同時帶來的偏差上升有多少也還存疑。)
3、從方差偏差分解的思路來看交叉驗證
讓我們思考交叉驗證的兩種極端情況:
- 完全不使用交叉驗證是一種極端情況,即K=1。在這個時候,所以資料都被用於訓練,模型很容易出現過擬合,因此容易是低偏差、高方差(low bias and high variance)。
- 留一法是K折的另一種極端情況,即K=n。隨著K值的不斷升高,單一模型評估時的方差逐漸加大而偏差減小。但從總體模型角度來看,反而是偏差升高了而方差降低了。
所以當K值在1到n之間的遊走,可以理解為一種方差和偏差妥協的結果。以K=10為例,在訓練時我們的訓練集數量僅為訓練資料的90%。對比不使用交叉驗證的情況,這會使得偏差上升,但對於結果的平均又會降低模型方差,最終結果是否變好取決於兩者之間的變化程度。(而這種直覺上的解釋,並不總是有效。如Hastie曾通過實驗證明 K折交叉驗證比留一法的方差更小,這和我們上面的結論不一樣。)


另一個值得一提的看法是,交叉驗證需要思考場景,而不是普適的。其中關係最大的就是評估模型的穩定性。在2015年的一項研究中,作者發現留一法有最好或者接近最好的結果[2],在他們的實驗中 K=10和K=5的效果都遠不如留一法或者K=20。
二. K到底該取多少?為什麼大部分人都要取10?
由於實際情況中,交叉的折數(fold)受很多因素的影響,所以K值取多少也沒能給出準確的答案。10作為做一種經驗值也就被無腦地延續使用。一般有兩種流行的取值:(i) K=10 (ii) K=n,n指的是訓練資料的總數,這種方法也叫做留一法(LOOCV)。
1、對於穩定模型來說,留一法的結果較為統一,值得信賴。對於不穩定模型,留一法往往比K折更為有效。
2、模型穩定性較低時,增大K的取值可以給出更好的結果,但是要考慮計算的開銷。
3、2017年的一項研究給出了另一種經驗式的選擇方法,作者建議 且保證
,n代表了資料量,d代表了特徵數。感興趣的朋友可以對照論文進一步瞭解。
總結
1、使用交叉驗證的根本原因是資料集太小,而較小的K值會導致可用於建模的資料量太小,所以小資料集的交叉驗證結果需要格外注意。建議選擇較大的K值。
1、這篇文章的目的不是為了說明K到底該取什麼值,而只是為了討論K值其實還是一種方差和偏差之間妥協。K=10或者5並不能給與我們絕對的保障,這還要結合所使用的模型來看。當模型穩定性較低時,增大K的取值可以給出更好的結果。
2、但從實驗角度來看,較大的K值也不一定就能給出更小的方差,一切都需要具體情況具體討論。相對而言,較大的K值的交叉驗證結果傾向於更好。但同時也要考慮較大K值的計算開銷。
所以總結來看,交叉驗證還是一個比較複雜的過程,與模型穩定性,資料集大小等都息息相關。K=10的10折交叉驗證不是萬靈藥,也不是萬無一失的真理,但不失為一個良好的嘗試。如果計算能力允許,增大K值或許更為保險。