
20189220 餘超《Linux核心原理與分析》第九周作業
理解程序排程時機跟蹤分析程序排程與程序切換的過程
本章的基礎知識總結
- 一般來說,程序排程分為三種類型:中斷處理過程(包括時鐘中斷、I/O 中斷、系統呼叫和異常)中,直接呼叫schedule,或者返回使用者態時根據 need_resched 標記呼叫 schedule;核心執行緒可以直接呼叫 schedule 進行程序切換,也可以在中斷處理過程中進行排程,也就是說核心執行緒作為一類的特殊的程序可以主動排程,也可以被動排程;使用者態程序無法實現主動排程,僅能通過陷入核心態後的某個時機點進行排程,即在中斷處理過程中進行排程。
- 為了控制程序的執行,核心必須有能力掛起正在 CPU 上執行的程序,並恢復以前掛起的某個程序的執行的過程,叫做程序切換、任務切換、上下文切換。掛起正在 CPU 上執行的程序,與中斷時儲存現場是有區別的,中斷前後是在同一個程序上下文中,只是由使用者態轉向核心態執行。也即是說中斷是在同一個程序中執行的,程序上下文是在不同的程序中執行的。
- 程序上下文資訊:使用者地址空間:包括程式程式碼,資料,使用者堆疊等;控制資訊:程序描述符,核心堆疊等;硬體上下文(注意中斷也要儲存硬體上下文只是儲存的方法不同);schedule 函式選擇一個新的程序來執行,並呼叫 context_switch 巨集進行上下文的切換,這個巨集又呼叫 switch_to 巨集來進行關鍵上下文切換;switch_to 巨集中定義了 prev 和 next 兩個引數:prev 指向當前程序,next 指向被排程的程序。
實驗流程
1.用gdb來進行除錯,並設定相應的斷點
2.schedule()函式斷點截圖,程序排程的主體

3.context_switch函式的斷點截圖,用於實現程序的切換

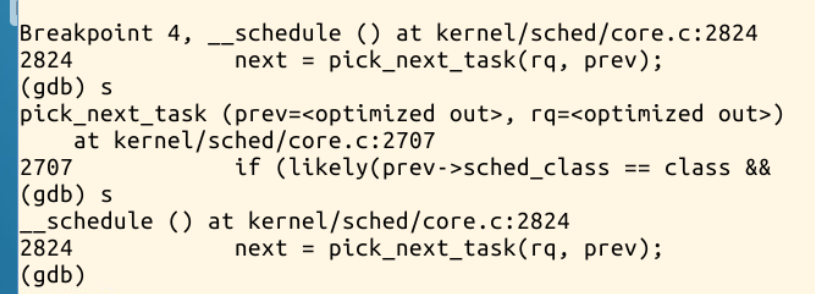
4.pick_next_task函式斷點截圖,使用某種排程策略選擇下一個程序來切換
程式碼分析
static void __sched __schedule(void) { struct task_struct *prev, *next; unsigned long *switch_count; struct rq *rq; int cpu; need_resched: preempt_disable(); cpu = smp_processor_id(); rq = cpu_rq(cpu); rcu_note_context_switch(cpu); prev = rq->curr; schedule_debug(prev); if (sched_feat(HRTICK)) hrtick_clear(rq); /* * Make sure that signal_pending_state()->signal_pending() below * can't be reordered with __set_current_state(TASK_INTERRUPTIBLE) * done by the caller to avoid the race with signal_wake_up(). */ smp_mb__before_spinlock(); raw_spin_lock_irq(&rq->lock); switch_count = &prev->nivcsw; if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) { if (unlikely(signal_pending_state(prev->state, prev))) { prev->state = TASK_RUNNING; } else { deactivate_task(rq, prev, DEQUEUE_SLEEP); prev->on_rq = 0; /* * If a worker went to sleep, notify and ask workqueue * whether it wants to wake up a task to maintain * concurrency. */ if (prev->flags & PF_WQ_WORKER) { struct task_struct *to_wakeup; to_wakeup = wq_worker_sleeping(prev, cpu); if (to_wakeup) try_to_wake_up_local(to_wakeup); } } switch_count = &prev->nvcsw; } if (task_on_rq_queued(prev) || rq->skip_clock_update < 0) update_rq_clock(rq); next = pick_next_task(rq, prev); clear_tsk_need_resched(prev); clear_preempt_need_resched(); rq->skip_clock_update = 0; if (likely(prev != next)) { rq->nr_switches++; rq->curr = next; ++*switch_count; context_switch(rq, prev, next); /* unlocks the rq */ /* * The context switch have flipped the stack from under us * and restored the local variables which were saved when * this task called schedule() in the past. prev == current * is still correct, but it can be moved to another cpu/rq. */ cpu = smp_processor_id(); rq = cpu_rq(cpu); } else raw_spin_unlock_irq(&rq->lock); post_schedule(rq); sched_preempt_enable_no_resched(); if (need_resched()) goto need_resched; }
schedule 函式主要做了這麼幾件事:針對搶佔的處理;檢查prev的狀態,並且重設state的狀態;next = pick_next_task(rq, prev); //程序排程;更新就緒佇列的時鐘;context_switch(rq, prev, next); //程序上下文切換
stwitch_to的程式碼
asm volatile("pushfl\n\t" /* save flags */ \
"pushl %%ebp\n\t" /* save EBP */ \
"movl %%esp,%[prev_sp]\n\t" /* save ESP */ \
"movl %[next_sp],%%esp\n\t" /* restore ESP */ \
"movl $1f,%[prev_ip]\n\t" /* save EIP */ \
"pushl %[next_ip]\n\t" /* restore EIP */ \
"jmp __switch_to\n" /* regparm call */ \
"1:\t" \
"popl %%ebp\n\t" /* restore EBP */ \
"popfl\n" /* restore flags */ \
\
/* output parameters */ \
: [prev_sp] "=m" (prev->thread.sp), \
/* =m 表示把變數放入記憶體,即把 [prev_sp] 儲存的變數放入記憶體,最後再寫入prev->thread.sp */\
[prev_ip] "=m" (prev->thread.ip), \
"=a" (last), \
/*=a 表示把變數 last 放入 ax, eax = last */ \
\
/* clobbered output registers: */ \
"=b" (ebx), "=c" (ecx), "=d" (edx), \
/* b 表示放入ebx, c 表示放入 ecx,d 表示放入 edx, S表示放入 si, D 表示放入 edi */\
"=S" (esi), "=D" (edi) \
\
/* input parameters: */ \
: [next_sp] "m" (next->thread.sp), \
/* next->thread.sp 放入記憶體中的 [next_sp] */\
[next_ip] "m" (next->thread.ip), \
\
/* regparm parameters for __switch_to (): */ \
[prev] "a" (prev), \
/*eax = prev edx = next*/\
[next] "d" (next) \
\
: /* reloaded segment registers */ \
"memory");switch_to從A程序切換到B程序的步驟如下:
1.複製兩個變數到暫存器: [prev]"a" (prev) [next]"d" (next)。這也就是eax <== prev_A或eax<==%p(%ebp_A) edx <== next_A 或edx<==%n(%ebp_A)
2.儲存程序A的ebp和eflags。注意,因為現在esp還在A的堆疊中,所以它們是被儲存到A程序的核心堆疊中。
3.儲存當前esp到A程序核心描述符中: 這也就是prev_A->thread.sp<== esp_A 在呼叫switch_to時,prev是指向A程序自己的程序描述符的。
4.從next(程序B)的描述符中取出之前從B切換出去時儲存的esp_B 注意,在A程序中的next是指向B的程序描述符的。從這個時候開始,CPU當前執行的程序已經是B程序了,因為esp已經指向B的核心堆疊。但是,現在的ebp仍然指向A程序的核心堆疊,所以所有區域性變數仍然是A中的區域性變數,比如next實質上是%n(%ebp_A),也就是next_A,即指向B的程序描述符。
5.把標號為1的指令地址儲存到A程序描述符的ip域:當A程序下次從switch_to回來時,會從這條指令開始執行。具體方法要看後面被切換回來的B的下一條指令。
6.將返回地址儲存到堆疊,然後呼叫switch_to()函式,switch_to()函式完成硬體上下文切換 注意,如果之前B也被switch_to出去過,那麼[next_ip]裡存的就是下面這個1f的標號,但如果程序B剛剛被建立,之前沒有被switch_to出去過,那麼[next_ip]裡存的將是ret_ftom_fork(參看copy_thread()函式)。
當這裡switch_to()返回時,將返回值prev_A又寫入了%eax,這就使得在switch_to巨集裡面eax暫存器始終儲存的是prev_A的內容,或者,更準確的說,是指向A程序描述符的“指標”。
7.從switch_to()返回後繼續從1:標號後面開始執行,修改ebp到B的核心堆疊,恢復B的eflags。
8.將eax寫入last,以在B的堆疊中儲存正確的prev資訊。所以,這裡面的last實質上就是prev,因此在switch_to巨集執行完之後,prev_B就是正確的A的程序描述符了。這裡,last的作用相當於把程序A堆疊中的A程序描述符地址複製到了程序B的堆疊中。
9.至此,switch_to已經執行完成,A停止執行,而開始執行B。此後,可能在某一次排程中,程序A得到排程,就會出現switch_to(C,A)這樣的呼叫,這時,A再次得到排程,得到排程後,A程序從context_switch()中switch_to後面的程式碼開始執行,這時候,它看到的prev_A將指向C的程序描述符。
本章總結
一般情形:
正在執行的使用者態程序 A 切換到執行使用者態程序 B 的過程:
1、正在執行的使用者態程序 A;
2、中斷——save cs:eip/esp/eflags(current) to kernel stack,and load cs:eip(entry of a specific ISR) and ss:esp(point to kernel stack);
3、SAVE_ALL //儲存現場;
4、中斷處理或中斷返回前呼叫 schedule,其中,switch_to 做了關鍵的程序上下文切換;
5、標號1之後開始執行使用者態程序 B;
6、restore_all //恢復現場;
7、iret——pop cs:eip/ss:esp/eflags from kernel stack;
8、繼續執行使用者態程序 B;
特殊情況:
1、通過中斷處理過程中的排程,使用者態程序與核心程序之間互相切換,與一般情形類似;
2、核心程序程主動呼叫 schedule 函式,只有程序上下文的切換,沒有中斷上下文切換;
3、建立子程序的系統呼叫在子程序中的執行起點及返回使用者態,如:fork;
4、載入一個新的可執行程式後返回到使用者態的情況,如:execve;