
TensorFlow載入VGG並可視化每層
阿新 • • 發佈:2018-12-09
一、簡介
VGG網路在2014年的 ILSVRC localization and classification 兩個問題上分別取得了第一名和第二名。VGG網路非常深,通常有16-19層,如果自己訓練網路模型的話很浪費時間和計算資源。因此這裡採用一種方法獲取VGG19模型的模型資料,從而能夠更快速的應用到自己的任務中來,
本文在載入模型資料的同時,還視覺化圖片在網路傳播過程中,每一層的輸出特徵圖。讓我們能夠更直接的觀察網路傳播的狀況。
執行環境為spyder,Python3.5,tensorflow1.2.1 模型名稱為: imagenet-vgg-verydeep-19.mat 大家可以在網上下載。
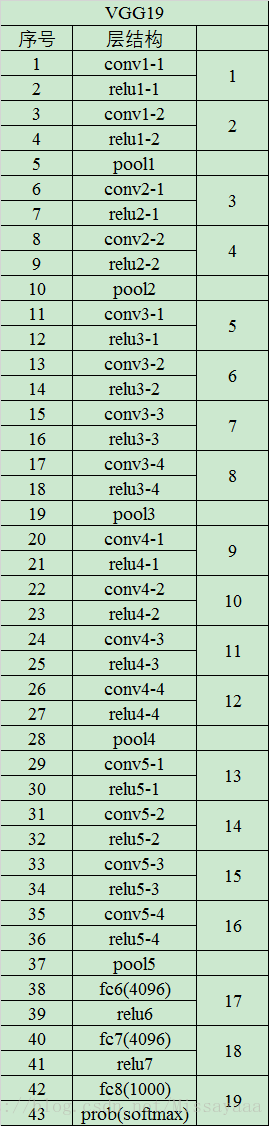
二、VGG19模型結構
模型的每一層結構如下圖所示:
三、程式碼
#載入VGG19模型並可視化一張圖片前向傳播的過程中每一層的輸出 #引入包 import tensorflow as tf import numpy as np import matplotlib.pyplot as plt import scipy.io import scipy.misc #定義一些函式 #卷積 def _conv_layer(input, weights, bias): conv = tf.nn.conv2d(input, tf.constant(weights), strides=(1, 1, 1, 1), padding='SAME') return tf.nn.bias_add(conv, bias) #池化 def _pool_layer(input): return tf.nn.max_pool(input, ksize=(1, 2, 2, 1), strides=(1, 2, 2, 1), padding='SAME') #減畫素均值操作 def preprocess(image, mean_pixel): return image - mean_pixel #加畫素均值操作 def unprocess(image, mean_pixel): return image + mean_pixel #讀 def imread(path): return scipy.misc.imread(path).astype(np.float) #儲存 def imsave(path, img): img = np.clip(img, 0, 255).astype(np.uint8) scipy.misc.imsave(path, img) print ("Functions for VGG ready") #定義VGG的網路結構,用來儲存網路的權重和偏置引數 def net(data_path, input_image): #拿到每一層對應的引數 layers = ( 'conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1', 'conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2', 'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2', 'conv3_3', 'relu3_3', 'conv3_4', 'relu3_4', 'pool3', 'conv4_1', 'relu4_1', 'conv4_2', 'relu4_2', 'conv4_3', 'relu4_3', 'conv4_4', 'relu4_4', 'pool4', 'conv5_1', 'relu5_1', 'conv5_2', 'relu5_2', 'conv5_3', 'relu5_3', 'conv5_4', 'relu5_4' ) data = scipy.io.loadmat(data_path) #原網路在訓練的過程中,對每張圖片三通道都執行了減均值的操作,這裡也要減去均值 mean = data['normalization'][0][0][0] mean_pixel = np.mean(mean, axis=(0, 1)) #print(mean_pixel) #取到權重引數W和b,這裡運氣好的話,可以查到VGG模型中每層的引數含義,查不到的 #話可以打印出weights,然後列印每一層的shape,推出其中每一層代表的含義 weights = data['layers'][0] #print(weights) net = {} current = input_image #取到w和b for i, name in enumerate(layers): #:4的含義是隻看每一層的前三個字母,從而進行判斷 kind = name[:4] if kind == 'conv': kernels, bias = weights[i][0][0][0][0] # matconvnet: weights are [width, height, in_channels, out_channels]\n", # tensorflow: weights are [height, width, in_channels, out_channels]\n", #這裡width和height是顛倒的,所以要做一次轉置運算 kernels = np.transpose(kernels, (1, 0, 2, 3)) #將bias轉換為一個維度 bias = bias.reshape(-1) current = _conv_layer(current, kernels, bias) elif kind == 'relu': current = tf.nn.relu(current) elif kind == 'pool': current = _pool_layer(current) net[name] = current assert len(net) == len(layers) return net, mean_pixel, layers print ("Network for VGG ready") #cwd = os.getcwd() #這裡用的是絕對路徑 VGG_PATH = "F:/mnist/imagenet-vgg-verydeep-19.mat" #需要視覺化的圖片路徑,這裡是一隻小貓 IMG_PATH = "D:/VS2015Program/cat.jpg" input_image = imread(IMG_PATH) #獲取影象shape shape = (1,input_image.shape[0],input_image.shape[1],input_image.shape[2]) #開始會話 with tf.Session() as sess: image = tf.placeholder('float', shape=shape) #呼叫net函式 nets, mean_pixel, all_layers = net(VGG_PATH, image) #減均值操作(由於VGG網路圖片傳入前都做了減均值操作,所以這裡也用相同的預處理 input_image_pre = np.array([preprocess(input_image, mean_pixel)]) layers = all_layers # For all layers \n", # layers = ('relu2_1', 'relu3_1', 'relu4_1')\n", for i, layer in enumerate(layers): print ("[%d/%d] %s" % (i+1, len(layers), layer)) features = nets[layer].eval(feed_dict={image: input_image_pre}) print (" Type of 'features' is ", type(features)) print (" Shape of 'features' is %s" % (features.shape,)) # Plot response \n", #畫出每一層 if 1: plt.figure(i+1, figsize=(10, 5)) plt.matshow(features[0, :, :, 0], cmap=plt.cm.gray, fignum=i+1) plt.title("" + layer) plt.colorbar() plt.show()
四、程式執行結果
1、print(weights)的結果:

2、程式執行最終結果: 
