
python之動態引數 *args,**kwargs和名稱空間
一、函式的動態引數 *args,**kwargs, 形參的順序
1、你的函式,為了拓展,對於傳入的實引數量應該是不固定,
所以就需要用到萬能引數,動態引數,*args, **kwargs
1,*args 將所有實參的位置引數聚合到一個元組,並將這個元組賦值給args
(起作用的是* 並不是args,但是約定俗成動態接收實參的所有位置引數就用args)
def sum1(*args): print(args) sum1(1,2,['hello']) #是一個元組(1, 2, ['hello'])
2,**kwargs 將所有實參的關鍵字引數
(起作用的是** 並不是kwargs,但是約定俗成動態接收實參的所有關鍵字引數就用kwargs)

def fun(*args,**kwargs): print(args) print(kwargs) fun(1,2,['a','b'],name='xiaobai',age=18) # 結果: # (1, 2, ['a', 'b']) #位置引數,元組 # {'name': 'xiaobai', 'age': 18} #關鍵字引數,字典
2、*的用法
在函式的定義時,*位置引數,**關鍵字引數--->聚合。
在函式的呼叫(執行)時,*位置引數,**關鍵字引數--->打散。
實參--->*位置引數--->把位置引數打散成最小的元素,然後一個個新增到args裡組成一個元組
l1 = [1,2,3] l2 = [111,22,33,'xiaobai'] #如果要將l1,l2通過函式整合到一起 # 方法一(實參不用*): def func1(*args): return args[0] + args[1] print(func1(l1,l2)) #[1, 2, 3, 111, 22, 33, 'xiaobai'] # 方法二(實參用*): def func1(*args): return args print(func1(*l1,*l2)) #(1, 2, 3, 111, 22, 33, 'xiaobai')
實參--->**關鍵字引數--->把關鍵字引數打散成最小的元素,然後一個個新增到kwargs裡組成一個字典
def func1(**kwargs): print(kwargs) #func1(name='xiaobai',age=18,job=None,hobby='girl') func1(**{'name':'xiaobai','age':18},**{'job':None,'hobby':'girl'}) # 結果: # {'name': 'xiaobai', 'age': 18, 'job': None, 'hobby': 'girl'}
3、形參的順序(a--->b,代表的順序是寫引數時,要先寫a再寫b)
位置引數--->預設引數
def func(a,b,sex='男'): print(sex) func(100,200)
位置引數--->*args--->預設引數
def func(a,b,*args,sex='男'): print(a,b) print(args) print(sex) func(100,200,1,2,34,5,'女',6) # 結果: # 100 200 #a,b # (1, 2, 34, 5,'女',6) #args # 男 #預設引數
位置引數--->*args--->預設引數--->**kwargs
def func(a,b,*args,sex='男',**kwargs): print(a,b) print(args) print(sex) print(kwargs) func(100,200,1,2,34,5,6,sex='女',name='xiaobai',age=1000) func(100,200,1,2,34,5,6,name='xiaobai',age=1000,sex='女') # 兩個的結果都是: # 100 200 #a,b # (1, 2, 34, 5, 6) #args # 女 #預設引數修改後的值 # {'name': 'xiaobai', 'age': 1000} #kwargs # 若是形參這樣寫: def func(a,b,*args,**kwargs,sex='男'): print(a,b) print(args) print(sex) print(kwargs) func(100,200,1,2,34,5,6,name='xiaobai',age=1000,sex='女') # 結果:會報錯,預設引數一定要寫在kwargs前面
二、名稱空間,臨時名稱空間,作用域,取值順序,載入順序等
'''
我們首先回憶一下Python程式碼執行的時候遇到函式是怎麼做的,從Python直譯器開始執行之後,就在記憶體中開闢裡一個空間,每當遇到一個變數的時候,
就把變數名和值之間對應的關係記錄下來,但是當遇到函式定義的時候,直譯器只是象徵性的將函式名讀入記憶體,表示知道這個函式存在了,至於函式內部的變數和邏輯,直譯器根本不關心。
等執行到函式呼叫的時候,Python直譯器會再開闢一塊記憶體來儲存這個函式裡面的內容,這個時候,才關注函式裡面有哪些變數,而函式中的變數會儲存在新開闢出來的記憶體中,
函式中的變數只能在函式內部使用,因為隨著函式執行完畢,這塊記憶體中的所有內容也會被清空。
我們給這個‘存放名字與值的關係’的空間起了一個名字-------名稱空間。
程式碼在執行開始,建立的儲存“變數名與值的關係”的空間叫做全域性名稱空間;
在函式的執行中開闢的臨時的空間叫做區域性名稱空間。
'''
1、python中,名稱空間分三種:
1,全域性名稱空間
2,區域性名稱空間(臨時)
3,內建名稱空間
*內建名稱空間中存放了python直譯器為我們提供的名字:input,print,str,list,tuple...它們都是我們熟悉的,拿過來就可以用的方法。
2、作用域:
1,全域性作用域:全域性名稱空間 內建名稱空間
2,區域性作用域:區域性名稱空間(臨時)
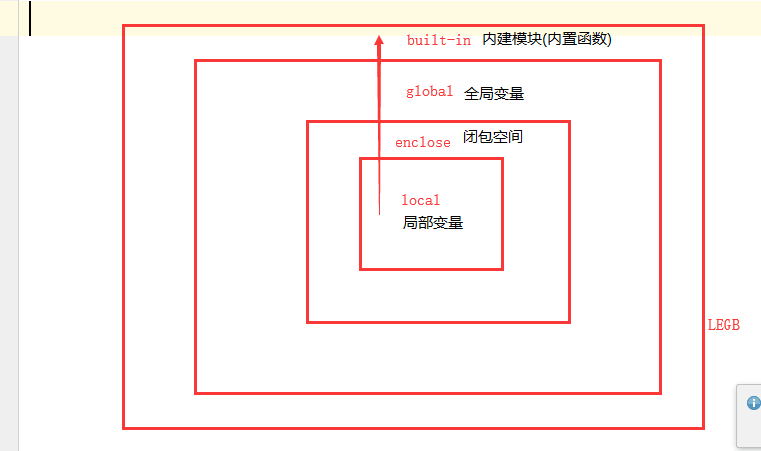
3、取值順序: 就近原則(LEGB)
區域性名稱空間 ----> 全域性名稱空間 ----->內建名稱空間 單向 從小到大範圍
也就是說:
在區域性呼叫時取值順序是:區域性名稱空間->全域性名稱空間->內建名稱空間
在全域性呼叫時取值順序是:全域性名稱空間->內建名稱空間
len = 6 #設定全域性變數 而且len也在內建名稱空間中
def func1():
len = 3 #設定區域性變數
return len
print(func1()) #返回的len值是區域性名稱空間的值:3
4、載入順序
內建名稱空間(程式執行前載入) ----> 全域性名稱空間(程式執行中:從上到下載入) --- > 區域性名稱空間(當函式呼叫的時候)
三、global,nonlocal
1、在區域性名稱空間 可以引用全域性名稱空間的變數,但是不能改變它的值。
count = 1
def func1():
print(count)
func1() #引用全域性名稱空間的變數,結果為:1
count = 1
def func1():
count += 1
print(count)
func1() #會報錯,因為在區域性名稱空間中不能直接修改全域性名稱空間的變數
#如果你在區域性名稱空間對一個變數進行修改,那麼直譯器會認為你的這個變數在區域性中已經定義了,
#但是對於上面的例題,區域性中沒有定義,所以就會報錯。
2、global:
1,在區域性名稱空間宣告一個全域性變數。
2,在區域性作用域想要對全域性作用域的全域性變數進行修改時,需要用到global(限於字串,數字)。
例子:
def fun(): global a #聲明瞭一個全域性變數a。 a = 3 fun() #呼叫函式後,就生成了全域性變數a,不會因為函式的結束而釋放掉。 print(a) # 3 count = 1 #全域性變數count def fun(): global count #在區域性作用域想要對全域性作用域的全域性變數進行修改時,用global宣告。 count += 1 fun() print(count) # 2
ps:對於在全域性名稱空間的可變資料型別(list,dict,set)可以直接引用並修改不用通過global。
但是函式內部(區域性名稱空間)的可變資料型別在沒有global的宣告下,全域性名稱空間也是不可以呼叫的。
li = [1, 2, 3] # 全域性名稱空間的可變資料型別 dic = {'name': 'sb'} def change(): li.append('hello') # 在區域性名稱空間直接引用並修改 dic['age'] = 18 change() print(li) # [1, 2, 3, 'hello'] print(dic) # {'name': 'sb', 'age': 18} def fun(): l1 = [1, 2, 3] # 區域性名稱空間的可變資料型別 fun() l1.append(4) print(l1) # 報錯,name 'l1' is not defined def fun(): global l1 # 區域性名稱空間用global宣告可變資料型別 l1 l1 = [1, 2, 3] fun() l1.append(4) print(l1) # [1, 2, 3, 4]
3、nonlocal
1,此變數宣告的變數不能是全域性變數,它不能修改全域性變數。
2,子函式對父函式的變數進行修改。(在區域性作用域中,對父級作用域(或者更外層作用域非全域性作用域)的變數進行引用和修改,並且引用的是哪一層,就從那一層及以下此變數全部發生改變。)
例子:
def func1(): count = 666 def inner(): print(count) def func2(): nonlocal count #這裡如果不宣告nonlocal,那麼可以引用父函式的conut值,但是不能修改否則就會報錯 count += 1 print('func2',count) func2() print('inner',count) inner() print('func1',count) func1() # 666 func2 667 inner 667 func1 667
四、函式的巢狀
1、函式的巢狀定義
def f1(): print("in f1") def f2(): print("in f2") f2() f1() #in f1 #in f2 def f1(): def f2(): def f3(): print("in f3") print("in f2") f3() print("in f1") f2() f1() #in f1 #in f2 #in f3
2、函式的巢狀呼叫
def max1(x,y): m = x if x>y else y return m def max2(a,b,c,d): res1 = max1(a,b) res2 = max1(res1,c) res3 = max1(res2,d) return res3 print(max2(23,-7,31,11)) # 31
一、函式的動態引數 *args,**kwargs, 形參的順序
1、你的函式,為了拓展,對於傳入的實引數量應該是不固定,
所以就需要用到萬能引數,動態引數,*args, **kwargs
1,*args 將所有實參的位置引數聚合到一個元組,並將這個元組賦值給args
(起作用的是* 並不是args,但是約定俗成動態接收實參的所有位置引數就用args)
def sum1(*args): print(args) sum1(1,2,['hello']) #是一個元組(1, 2, ['hello'])
2,**kwargs 將所有實參的關鍵字引數聚合到一個字典,並將這個字典賦值給kwargs
(起作用的是** 並不是kwargs,但是約定俗成動態接收實參的所有關鍵字引數就用kwargs)
def fun(*args,**kwargs): print(args) print(kwargs) fun(1,2,['a','b'],name='xiaobai',age=18) # 結果: # (1, 2, ['a', 'b']) #位置引數,元組 # {'name': 'xiaobai', 'age': 18} #關鍵字引數,字典
2、*的用法
在函式的定義時,*位置引數,**關鍵字引數--->聚合。
在函式的呼叫(執行)時,*位置引數,**關鍵字引數--->打散。
實參--->*位置引數--->把位置引數打散成最小的元素,然後一個個新增到args裡組成一個元組
l1 = [1,2,3] l2 = [111,22,33,'xiaobai'] #如果要將l1,l2通過函式整合到一起 # 方法一(實參不用*): def func1(*args): return args[0] + args[1] print(func1(l1,l2)) #[1, 2, 3, 111, 22, 33, 'xiaobai'] # 方法二(實參用*): def func1(*args): return args print(func1(*l1,*l2)) #(1, 2, 3, 111, 22, 33, 'xiaobai')
實參--->**關鍵字引數--->把關鍵字引數打散成最小的元素,然後一個個新增到kwargs裡組成一個字典
def func1(**kwargs): print(kwargs) #func1(name='xiaobai',age=18,job=None,hobby='girl') func1(**{'name':'xiaobai','age':18},**{'job':None,'hobby':'girl'}) # 結果: # {'name': 'xiaobai', 'age': 18, 'job': None, 'hobby': 'girl'}
3、形參的順序(a--->b,代表的順序是寫引數時,要先寫a再寫b)
位置引數--->預設引數
def func(a,b,sex='男'): print(sex) func(100,200)
位置引數--->*args--->預設引數
def func(a,b,*args,sex='男'): print(a,b) print(args) print(sex) func(100,200,1,2,34,5,'女',6) # 結果: # 100 200 #a,b # (1, 2, 34, 5,'女',6) #args # 男 #預設引數
位置引數--->*args--->預設引數--->**kwargs
def func(a,b,*args,sex='男',**kwargs): print(a,b) print(args) print(sex) print(kwargs) func(100,200,1,2,34,5,6,sex='女',name='xiaobai',age=1000) func(100,200,1,2,34,5,6,name='xiaobai',age=1000,sex='女') # 兩個的結果都是: # 100 200 #a,b # (1, 2, 34, 5, 6) #args # 女 #預設引數修改後的值 # {'name': 'xiaobai', 'age': 1000} #kwargs # 若是形參這樣寫: def func(a,b,*args,**kwargs,sex='男'): print(a,b) print(args) print(sex) print(kwargs) func(100,200,1,2,34,5,6,name='xiaobai',age=1000,sex='女') # 結果:會報錯,預設引數一定要寫在kwargs前面
二、名稱空間,臨時名稱空間,作用域,取值順序,載入順序等
'''
我們首先回憶一下Python程式碼執行的時候遇到函式是怎麼做的,從Python直譯器開始執行之後,就在記憶體中開闢裡一個空間,每當遇到一個變數的時候,
就把變數名和值之間對應的關係記錄下來,但是當遇到函式定義的時候,直譯器只是象徵性的將函式名讀入記憶體,表示知道這個函式存在了,至於函式內部的變數和邏輯,直譯器根本不關心。
等執行到函式呼叫的時候,Python直譯器會再開闢一塊記憶體來儲存這個函式裡面的內容,這個時候,才關注函式裡面有哪些變數,而函式中的變數會儲存在新開闢出來的記憶體中,
函式中的變數只能在函式內部使用,因為隨著函式執行完畢,這塊記憶體中的所有內容也會被清空。
我們給這個‘存放名字與值的關係’的空間起了一個名字-------名稱空間。
程式碼在執行開始,建立的儲存“變數名與值的關係”的空間叫做全域性名稱空間;
在函式的執行中開闢的臨時的空間叫做區域性名稱空間。
'''
1、python中,名稱空間分三種:
1,全域性名稱空間
2,區域性名稱空間(臨時)
3,內建名稱空間
*內建名稱空間中存放了python直譯器為我們提供的名字:input,print,str,list,tuple...它們都是我們熟悉的,拿過來就可以用的方法。
2、作用域:
1,全域性作用域:全域性名稱空間 內建名稱空間
2,區域性作用域:區域性名稱空間(臨時)
3、取值順序: 就近原則(LEGB)
區域性名稱空間 ----> 全域性名稱空間 ----->內建名稱空間 單向 從小到大範圍
也就是說:
在區域性呼叫時取值順序是:區域性名稱空間->全域性名稱空間->內建名稱空間
在全域性呼叫時取值順序是:全域性名稱空間->內建名稱空間
len = 6 #設定全域性變數 而且len也在內建名稱空間中
def func1():
len = 3 #設定區域性變數
return len
print(func1()) #返回的len值是區域性名稱空間的值:3
4、載入順序
內建名稱空間(程式執行前載入) ----> 全域性名稱空間(程式執行中:從上到下載入) --- > 區域性名稱空間(當函式呼叫的時候)
三、global,nonlocal
1、在區域性名稱空間 可以引用全域性名稱空間的變數,但是不能改變它的值。
count = 1
def func1():
print(count)
func1() #引用全域性名稱空間的變數,結果為:1
count = 1
def func1():
count += 1
print(count)
func1() #會報錯,因為在區域性名稱空間中不能直接修改全域性名稱空間的變數
#如果你在區域性名稱空間對一個變數進行修改,那麼直譯器會認為你的這個變數在區域性中已經定義了,
#但是對於上面的例題,區域性中沒有定義,所以就會報錯。
2、global:
1,在區域性名稱空間宣告一個全域性變數。
2,在區域性作用域想要對全域性作用域的全域性變數進行修改時,需要用到global(限於字串,數字)。
例子:
def fun(): global a #聲明瞭一個全域性變數a。 a = 3 fun() #呼叫函式後,就生成了全域性變數a,不會因為函式的結束而釋放掉。 print(a) # 3 count = 1 #全域性變數count def fun(): global count #在區域性作用域想要對全域性作用域的全域性變數進行修改時,用global宣告。 count += 1 fun() print(count) # 2
ps:對於在全域性名稱空間的可變資料型別(list,dict,set)可以直接引用並修改不用通過global。
但是函式內部(區域性名稱空間)的可變資料型別在沒有global的宣告下,全域性名稱空間也是不可以呼叫的。
li = [1, 2, 3] # 全域性名稱空間的可變資料型別 dic = {'name': 'sb'} def change(): li.append('hello') # 在區域性名稱空間直接引用並修改 dic['age'] = 18 change() print(li) # [1, 2, 3, 'hello'] print(dic) # {'name': 'sb', 'age': 18} def fun(): l1 = [1, 2, 3] # 區域性名稱空間的可變資料型別 fun() l1.append(4) print(l1) # 報錯,name 'l1' is not defined def fun(): global l1 # 區域性名稱空間用global宣告可變資料型別 l1 l1 = [1, 2, 3] fun() l1.append(4) print(l1) # [1, 2, 3, 4]
3、nonlocal
1,此變數宣告的變數不能是全域性變數,它不能修改全域性變數。
2,子函式對父函式的變數進行修改。(在區域性作用域中,對父級作用域(或者更外層作用域非全域性作用域)的變數進行引用和修改,並且引用的是哪一層,就從那一層及以下此變數全部發生改變。)
例子:
def func1(): count = 666 def inner(): print(count) def func2(): nonlocal count #這裡如果不宣告nonlocal,那麼可以引用父函式的conut值,但是不能修改否則就會報錯 count += 1 print('func2',count) func2() print('inner',count) inner() print('func1',count) func1() # 666 func2 667 inner 667 func1 667
四、函式的巢狀
1、函式的巢狀定義
def f1(): print("in f1") def f2(): print("in f2") f2() f1() #in f1 #in f2 def f1(): def f2(): def f3(): print("in f3") print("in f2") f3() print("in f1") f2() f1() #in f1 #in f2 #in f3
2、函式的巢狀呼叫
def max1(x,y): m = x if x>y else y return m def max2(a,b,c,d): res1 = max1(a,b) res2 = max1(res1,c) res3 = max1(res2,d) return res3 print(max2(23,-7,31,11)) # 31