
Deep Neural Networks for Object Detection
zhuanzii
採用的是AlexNet,不過稍作修改。
原AlexNet網路:
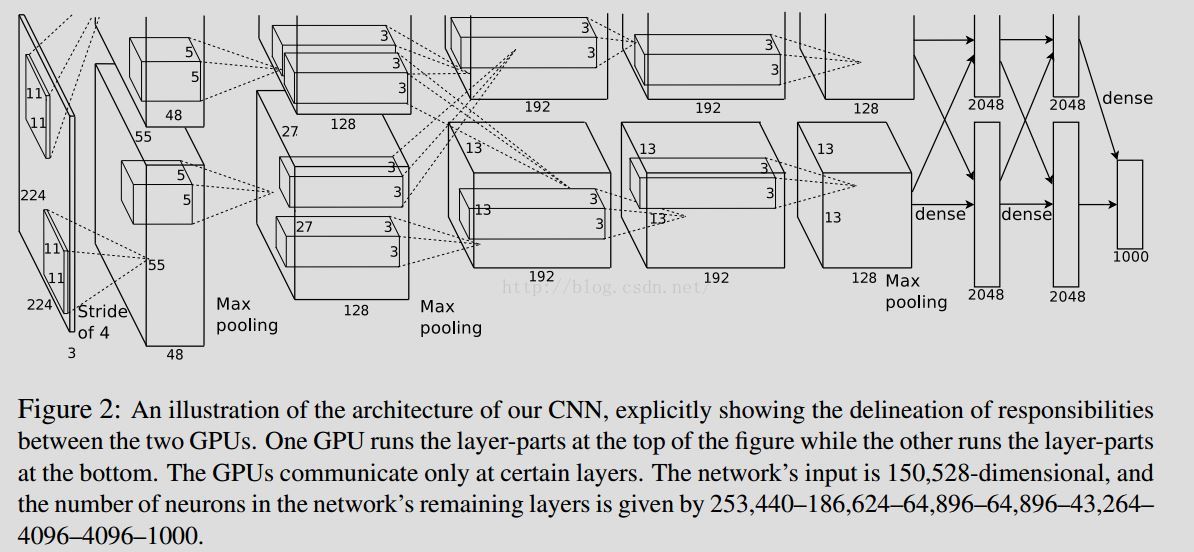
具體改進:
1. 把最後一個層softmax改成a regession layer.
predict a mask of a fixed size. 1代表this pixel lies withon the bounding box. 0 沒有。
訓練階段,優化目標函式:m屬於[0,1]^N
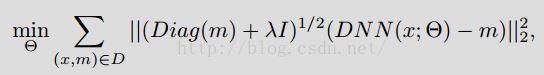
一般的L2只有上式的後半段,我猜前半段是正則化。
m=d*d。論文中d選取24.
5 Precise Object Localization via DNN-generated Masks //DNN 深度神經網路的意思。。
some challenge:
1. a single object mask not be sufficient to disambiguate objects which are placed next to each other. //當兩個目標挨著,輸出mask也是挨著,不能分辨,會被當成一個目標mask輸出。
2. 由於輸出的size的限制,we generate masks that are much smaller than the size of the original image.例如:輸入400*400,輸出24*24,each output would correspond to a cell of size 16*16, 不足以precisely localize an object,尤其當目標很小的時候。(不能精確定位)
3. 因為我們input the full image, 小目標will affect very few input neurons and thus will be hard to recognize.
5.1 Multiple Masks for Robust Localization
為了解決第一個問題,我們generate several masks, 每個代表the full object or part of it.
我們用一個網路來預測the object box mask, 額外的4個網路去預測 four halves of the box: bottom,top,left and right halves.五個predictions are over-complete 但可以幫助減少不確定並能有效處理某些預測錯誤的情況。
在訓練階段,我們需要convert the object box to these five masks。因為masks 比原影象小,我們需要對the ground truth mask 下采樣到output size.
5.2 Object Localizeation from DNN Output
5.3 Multi-scale Refinement of DNN Localizer
6 DNN Training
本網路的優點之一是簡單,然而需要大量的訓練樣本: objects of different sizes need to occur at almost every location.
we generate several thousand samples from each image divided into 60% negative and 40% positive samples。
因為定位比分類難,it is important to start with the weights of a model with high quality low-level filters. To achieve this, 我們先訓練一個分類網路,然後用訓練出的權重去定位,並對網路進行微調。
the networks were trained by stochastic gradient using ADAGRAD to estimate the learning rate of the layers automatically.
結果:voc2007是一個檢測並分類的任務/資料集。

On a 12-core machine, our implementation took about 5-6 secs per image for each class. 這個時間也太慢了吧。。