
hadoop namenode HA 高可用概念及配置說明
可以看到之前配置的完全分散式中只有一個nn節點,不能高可用。 在1x版本中存在這些問題: hdfs:nn單點故障,壓力過大,記憶體受限,擴充套件受阻。 MapReduce(MR):jboTracker訪問壓力大,擴充套件受阻;難以支援MR以外的計算框架,如spark,storm等。
1.HA 高可用
hdfs ha :主備切換方式解決單點故障 hdfs Federation聯邦:解決鴨梨過大。支援水平擴充套件,每個nn分管一部分目錄,所有nn共享dn資源。
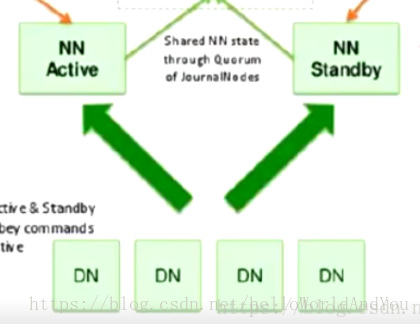
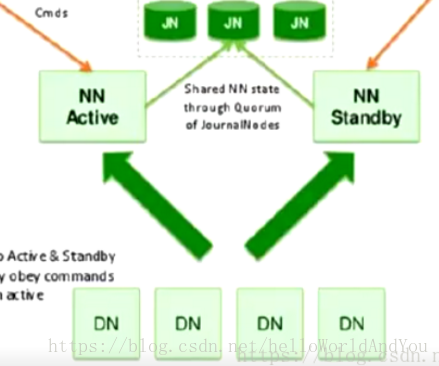
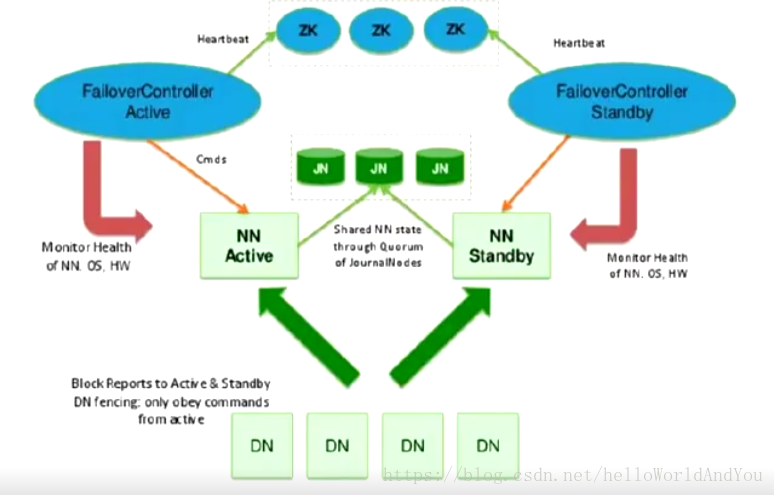
2. hdfs Federation 聯邦
通過多個namenode/namespace把元資料的儲存和管理分散到多個節點,以使能通過增加伺服器進行水平擴充套件。 將單個nn的負載分散到多個節點中,保證了對大規模資料的處理能力。通過多個namespace隔離不同型別的應用,將不同型別應用的hdfs元資料的儲存和管理分派到不同的namenode中。
HA with QJM搭建
Configuration details
配置的先後順序不重要,但其中某些配置之間存在依耐。例如: dfs.ha.namenodes.[nameservice ID] 依耐 dfs.nameservices 即如果dfs.nameservices配置value為a那麼dfs.ha.namenodes.[nameservice ID]則寫成dfs.ha.namenodes.a
hdfs-site.xml
- dfs.nameservices hdfs-site.xml名稱可自定義,建議取個合理的名字。該配置影響到其它配置,也會影響到hdfs檔案系統儲存的絕對路徑。 如果您還在使用HDFS Federation,則此配置設定還應包括其他名稱服務列表,HA或其他,用逗號作為分隔列表。
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>- dfs.ha.namenodes.[nameservice ID] 讓dn確定叢集中有多少個nn。nn至少兩個,推薦3個,不建議超過5個。
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2, nn3</value>
</property>- dfs.namenode.rpc-address.[nameservice ID].[name node ID] 偵聽的每個NameNode的完全限定的RPC地址。
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>machine1.example.com:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>machine2.example.com:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn3</name>
<value>machine3.example.com:8020</value>
</property>- dfs.namenode.http-address.[nameservice ID].[name node ID] 偵聽的每個NameNode的完全限定HTTP地址。 注意:如果啟用了Hadoop的安全功能,則還應為每個NameNode設定https-address。
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>machine1.example.com:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>machine2.example.com:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn3</name>
<value>machine3.example.com:9870</value>
</property>- dfs.namenode.shared.edits.dir 配置JournalNodes (jn)地址。如果是管理指令碼,則會根據改地址啟動jn,如果是active nn,則會通過該地址傳輸名稱空間變更資訊。備用的nn則會通過該配置地址拉取變更資料。配置值最後的/mycluster作為儲存的根路徑,多個HA可公用伺服器進行資料儲存,節約伺服器成本。因此每個HA服務的根路徑不能一樣,便於區分。
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1.example.com:8485;node2.example.com:8485;node3.example.com:8485/mycluster</value>
</property>- dfs.client.failover.proxy.provider.[nameservice ID] 便於客戶端確定哪個nn是主節點。對於第一次呼叫,它同時呼叫所有名稱節點以確定活動的名稱節點,之後便直接呼叫主節點(active nn ) ConfiguredFailoverProxyProvider 和RequestHedgingProxyProvider 選其一即可。
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>- dfs.ha.fencing.methods 當發生故障轉移時,以前的Active NameNode仍可能向客戶端提供讀取請求,這可能已過期,直到NameNode在嘗試寫入JournalNode時關閉。因此,即使使用Quorum Journal Manager,仍然需要配置一些防護方法。但是,為了在防護機制失敗的情況下提高系統的可用性,建議配置防護方法,能確保不會發生此類情況。請注意,如果您選擇不使用實際的防護方法,則仍必須為此設定配置某些內容,例如“shell(/ bin / true)”。 故障轉移期間使用的防護方法配置為回車分隔列表,將按順序嘗試,直到指示防護成功為止。 Hadoop有兩種方法:shell和sshfence。有關實現自定義防護方法的資訊,請參閱org.apache.hadoop.ha.NodeFencer類。 0.1) sshfence sshfence選項通過SSH連線到目標節點,並使用fuser來終止偵聽服務TCP埠的程序。為了使此防護選項起作用,它必須能夠在不提供密碼的情況下SSH到目標節點。因此,還必須配置dfs.ha.fencing.ssh.private-key-files選項,該選項是以逗號分隔的SSH私鑰檔案列表。 如果使用ssh免密的方式,那麼兩個nn需要互相免密登陸,因為涉及到zkfc需要登陸另一臺nn將其降序的操作。
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/exampleuser/.ssh/id_rsa</value>
</property>可選項,可以配置非標準使用者名稱或埠以執行SSH。也可以為SSH配置超時(以毫秒為單位),之後將認為此防護方法已失敗。
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence([[username][:port]])</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>0.2) shell
通過指令碼終止active nn
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/path/to/my/script.sh arg1 arg2 ...)</value>
</property>core-site.xml
- fs.defaultFS 配置和nameservice ID值一樣。將通過mycluster結合hdfs配置中的dfs.nameservices和dfs.ha.namenodes.mycluster找到該服務下的所有nn,確認主節點。
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>- dfs.journalnode.edits.dir 這是JournalNode本地儲存絕對路徑。
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/path/to/journal/node/local/data</value>
</property>