
C++禿頭之旅:簡單變數
程式通常都需要儲存資訊,為把資訊儲存在計算機中,程式必須經歷3個基本屬性:
- 資訊將儲存在哪裡?
- 要儲存什麼值?
- 儲存何種型別的資訊?
宣告中是使用的型別描述了資訊的型別和通過符號來表示其值的變數名,例如下面程式碼所示:
int braincount; braincount = 5;
這些語句告訴程式,他正在儲存整數,並使用名稱 braincount 來表示該整數的值(這裡為5)。實際上程式將找到一塊能夠儲存整數的記憶體,將該記憶體標記為 braincount ,並將5複製到該記憶體單元中;然後你可在程式中使用 braincount來訪問該記憶體單元
變數名:
-
C
++提倡使用一定含義的變數名。必須遵循幾種簡單的C++命名規則:
- 在名稱中只能使用字母字元、數字和下劃線(_)
- 名稱中的第一個字元不能是數字
- 區分大寫字元與小寫字元
- 不能將C++關鍵字用作名稱
-
以兩個下劃線或下劃線和大寫字母打頭的名稱被保留該實現(編譯器及其使用的資源)使用;以一個下劃線開頭的名稱被保留給實現,用作全域性識別符號
- 這點與前幾點有所不同,因為使用像 _time_stop 或 _Donut 這樣的名稱不會導致編譯器錯誤,而會導致行為的不確定性;換句話說,不知道結果將會是什麼。
- 不出現編譯器錯誤的原因是,這樣的名稱不是非法的,但要留給實現使用。
- 全域性名稱指的是名稱被宣告的位置。
- 這點與前幾點有所不同,因為使用像 _time_stop 或 _Donut 這樣的名稱不會導致編譯器錯誤,而會導致行為的不確定性;換句話說,不知道結果將會是什麼。
- C++對於名稱的長度沒有限制,名稱中所有的字元都有意義,但有些平臺有長度限制
- 如果想用或兩個更多的單片語成一個名稱,通常的做法是用下劃線字元將單詞分開,如 my_onions ;或者從第二個單詞開始講兩個單詞的第一個字母大寫,如 myEyeTooth。(推薦使用下劃線風格)
-
可在變數名中加入描述變數型別或內容字首,例如:
- 可以將整形變數 myWeight 命名為 nMyWeight,其中字首n用來表示整形值
- 長以這種方式使用的其他字首有:str 或 sz (表示以空字元結束的字元)、b(表示布林值)、p(表示指標)、和 c (表示單個字元)
- 可以將整形變數 myWeight 命名為 nMyWeight
整形:
- 整數就是沒有小數部分的數字。
- 整數有很多,如果將無限大的整數看做很大,則不可能用有限的計算機記憶體來表示所有整數,因此語言只能表示所有整數的一個子集
- 不同C++整形所有的不同的記憶體量來儲存整數。使用的記憶體量越大,可以表示的整數整數值範圍也就越大。另外有的型別(符號型別)可表示正值和負值,而有的型別(無符號型別)不能表示負值。
- 術語寬度用於描述儲存整數時使用的記憶體量。使用的記憶體越多,則越寬。
-
C++的基本整形(按寬度遞增的順序排列)分別是 char 、short 、int 、long 、和C++新增的long long,其中每種型別都有符號版本和無符號版本,因此總共有10中型別可供選擇。
- 實際上,short是short int 的簡稱,而 long 是 long int 的簡稱
-
這
4中型別都是符號整形(short 、int 、long、long long)都是符號整形,這意味著每種型別的取值範圍中,負值和正值幾乎相同。
- 例如:16位的 int 的取值範圍為-32768~+32768
- 由於 char 型別有一些特殊性,所以它最常用來表示字元,而不是數字
整形 short、int 、long、和 long long:
- 計算機記憶體由一些叫做位(bit)的單元組成。
- C++的short,Int,long和long long型別通過使用不同數目的位來儲存值,最多能夠表示4種不同的整數寬度。如果在所有的系統中,每種型別的寬度都相同,則使用起來將非常方便。例如,如果short總是16位,int 總是32位,這將非常方便。
-
C
++提供了一種靈活的標準,它確保了最小長度(從C
語言借鑑而來),如下所示:
- short 至少16位
- int 至少與 short 一樣長
- long 至少 32位,且至少與 int一樣長
- long long至少64位,且至少與 long 一樣長
-
位與位元組
- 計算機記憶體的基本單元是位(bit)。可以將位看作電子開關,可以開,也可以關。關表示值0,開表示值1。
- 8位的記憶體塊可以設定出256種不同的組合,因為每一位都可以有兩種設定,所以8位的總組合數為2x2x2x2x2x2x2x2,即256。因此,8位單元可以表示0~255或者-128~127。每增加一位,組合數便加倍。這意味著可以把16位單元設定成65536個不同的值,把32位單元設定成4294672296個不同的值,把64位單元設定為44674073709551616個不同的值。作為比較,unsignedlong存不了地球上當前的人數和銀河系的星星數,而long long能夠。
- 位元組(byte)通常指的是8位的記憶體單元。從這個意義上說,位元組指的就是描述計算機記憶體量的度量單位,IKB等於1024位元組,IMB等於1024KB。然而,C++對位元組的定義與此不同。C++位元組由至少能夠容納實現的基本字符集的相鄰位組成,也就是說,可能取值的數目必須等於或超過字元目。在美國,基本字符集通常是ASCII和EBCDIC字符集。它們都可以用8位來容納,所以在使用這兩種字符集的系統中,C++位元組通常包含8位。有些人使用術語8位組表示8位位元組。
-
sizeof
運算子返回型別或變數的長度,單位為(位元組);標頭檔案 climits 包含了關於整數限制的資訊,定義了表示各種符號名稱
-
程式示例:
// 一些整數限制 #include <iostream> #include <climits> using namespace std; int main() { int n_int = INT_MAX; short n_short = SHRT_MAX; long n_long = LONG_MAX; long long n_llong = LLONG_MAX; cout << "int is " << sizeof(int) << " bytes." << endl; cout << "short is " << sizeof n_short << " bytes." << endl; cout << "long is " << sizeof n_long << " bytes." << endl; cout << "long long is " << sizeof n_llong << " bytes." << endl; cout << endl; cout << "Maximum values:" << endl; cout << "int:" << n_int << endl; cout << "short:" << n_short << endl; cout << "long:" << n_long << endl; cout << "long long:" << n_llong << endl << endl; cout << "Minimum int value = " << INT_MIN << endl; cout << "Bits per byte = " << CHAR_BIT << endl; cin.get(); return 0; }
程式輸出:
int is 4 bytes.
short is 2 bytes.
long is 4 bytes.
long long is 8 bytes.
Maximum values:
int:2147483647
short:32767
long:2147483647
long long:9223372036854775807
Minimum int value = -2147483648
Bits per byte = 8
-
運算子sizofe 和標頭檔案 limits
-
sizeof
運算子指出,在使用8
位位元組的系統中,int長度為4個位元組。可對型別名或變數名使用sizeof運算子。
-
對型別名(如int
)使用sizeof
運算子時,應將名稱放在括號中;但對變數名使用該運算子時,括號是可選的:
cout << "int is " << sizeof(int) << " bytes." << endl; cout << "short is " << sizeof n_short << " bytes." << endl;
-
對型別名(如int
)使用sizeof
運算子時,應將名稱放在括號中;但對變數名使用該運算子時,括號是可選的:
-
標頭檔案climits定義了符號常量來表示型別的限制。例如:
- INT_MAX表示型別int能夠儲存的最大值
- 編譯廠商提供了climits 檔案,該檔案指出了其編譯的值,如下表格對該檔案中定義的符號常量進行了總結:
-
sizeof
運算子指出,在使用8
位位元組的系統中,int長度為4個位元組。可對型別名或變數名使用sizeof運算子。
-
程式示例:
| 符號常量 |
表示 |
| CHAR_BIT |
char 的位數 |
| CHAR_MAX |
char 的最大值 |
| CHAR_MIN |
char 的最小值 |
| SCHAR_MAX |
signed char 的最大值 |
| SCHAR_MIN |
signed char 的最小值 |
| UCHAR_MAX |
unsigned char 的最大值 |
| SHRT_MAX |
short 的最大值 |
| SHRT_MIN |
short 的最小值 |
| USHRT_MAX |
unsigned short 的最大值 |
| INT_MAX |
int 的最大值 |
| INT_MIN |
int 的最小值 |
| UNIT_MAX |
unsigned int 的最大值 |
| LONG_MAX |
long 的最大值 |
| LONG_MIN |
long 的最小值 |
| ULONG_MAX |
unsigned long 的最大值 |
| LLONG_MAX |
long long 的最大值 |
| LLONG_MIN |
long long 的最小值 |
| ULLONG_MAX |
unsigned long long 的最大值 |
-
符號常量——預處理方式
-
climits
檔案中包含與下面類似的語句行:
#define INT_MAX 32767在C++編譯過程中,首先將原始碼傳遞給前處理器。在這裡,#define和#include一樣,也是一個前處理器編譯指令。
該編譯指令指令高速前處理器:在程式中查詢INT_MAX,並將所有的INT_MAX都替換為32767。
但C++有一種更好建立符號常量的方法:使用關鍵字const。
-
climits
檔案中包含與下面類似的語句行:
-
初始化
-
初始化將賦值與宣告合併在一起,例如,下面的語句聲明瞭變數n_int
,並將int
的最大取值賦給它:
int n_int = INT_MAX;
也可以使用字面常量來初始化。可以將變數初始化另一個變數,條件是後者已經定義過。甚至可以使用表示式來初始化變數,條件是所有值都是已知的
int uncles = 5; int aunts = uncles; int chairs = aunts + uncles + 4;
前面的初始化來自C語言,C++還有另一種C語言沒有的初始化語法:
int owls = 101; int wrens(432); //C++獨有的變數初始化語法
- 注意:如果不對函式內部定義的變數進行初始化,該變數的值將是不確定的。這意味著該變數的值將是他被建立之前,相應記憶體單元儲存的值
-
初始化將賦值與宣告合併在一起,例如,下面的語句聲明瞭變數n_int
,並將int
的最大取值賦給它:
-
C++11初始化方式
-
還有另一種初始化方式,這種方式用於資料和結構,但在C
++98中,也可用於單值變數:
int hamburgers = (24);
將大括號初始化器用於單值變數的情形還不多,但C++11標準使得這種情形更多了。首先,採用這種方式時,可以使用等號(=),也可以不使用:
int emus{7}; int rheas = {12};
其次,大括號內可以不包含任何東西。在這種情況下,變數將被初始化為0:
int rocs {}; int psychics{}; //將被初始化為0
-
注意:這種方法助於更好地防範型別轉換錯誤
-
注意:這種方法助於更好地防範型別轉換錯誤
-
還有另一種初始化方式,這種方式用於資料和結構,但在C
++98中,也可用於單值變數:
無符號型別:
-
前面介紹的4
種整形都有一種不能儲存負數值的無符號變體,其優點是可以增大變數能夠儲存的最大值,
例如:
- short表示範圍為-32768~+32768,則無符號版本表示範圍為0~65536
-
要建立無符號版本的基本整形,只需使用關鍵字unsigned
來修改宣告即可:
unsigned short change; unsigned int rovert; unsigned quarterback; //也是 unsigned int unsigned long gone; unsigned long long lange_lange
- 注意:unsigned 本身是unsigned int 的縮寫
-
程式示例:
//超過一些整數限制 #include <iostream> #include <climits> //標頭檔案climits定義了符號常量來表示型別的限制 #define ZERO 0 //將0符號設定為ZERO符號 using namespace std; int main() { short sam = SHRT_MAX; // 檢視 short 的最大值 unsigned short sue = sam; //將 short 的最大值賦值給無符號的 short cout << "Sam has " << sam << " dollars and Sue has " << sue; cout << " dollars deposited." << endl << "Add $1 to each account." << endl << "Now";
sam = sam + 1; sue = sue + 1;
cout << " Sam has " << sam << " dollsrs and Sue has " << sue; cout << " dollars deposited.\npoor Sam!" << endl;
sam = ZERO; sue = ZERO;
cout << "Sam has " << sam << " dollsrs and Sue has " << sue; cout << " dollars deposited." << endl << "Take $1 to each account." << endl << "Now";
sam = sam - 1; sue = sue - 1;
cout << " Sam has " << sam << " dollsrs and Sue has " << sue; cout << " dollars deposited." << endl << "lucky Sue!" << endl; cin.get(); return 0; }程式輸出:
Sam has 32767 dollars and Sue has 32767 dollars deposited.
Add $1 to each account.
Now Sam has -32768 dollsrs and Sue has 32768 dollars deposited.
poor Sam!
Sam has 0 dollsrs and Sue has 0 dollars deposited.
Take $1 to each account.
Now Sam has -1 dollsrs and Sue has 65535 dollars deposited.
lucky Sue!
-
該程式將一個short變數(sam)和一個unsigned short 變數(sue)分別設定為最大的short值;然後將這些變數的值+1。
-
從結果可以看出,這些整形變數的行為就行里程錶,如果超過了限制,其值將為範圍另一端的取值。
C++確定保了無符號型別的這種行為;但C++並不保證符號整形超過限制(上溢和下溢)是不出錯,而正是當前實現中最為常見的行為。
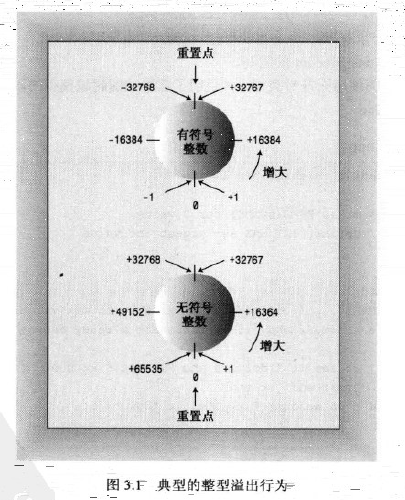
-
從結果可以看出,這些整形變數的行為就行里程錶,如果超過了限制,其值將為範圍另一端的取值。
C++確定保了無符號型別的這種行為;但C++並不保證符號整形超過限制(上溢和下溢)是不出錯,而正是當前實現中最為常見的行為。
選擇整型型別:
-
自然長度指的是計算機處理起來效率最高的長度,如果沒有非常有說服力的理由來選擇其他型別,則應使用int
。
- 通常,int被設定為對目標計算機而言,最為自然的長度。
- 如果變量表示的值不可能為負數,則可以使用無符號型別,這樣變數可以表示更大的值
-
如果知道變數可能表示的整數值大於16
位整數的最大可能值,則使用long。即使系統上Int為32位,也應這樣做。
- 這樣將系統移植到16位系統時,就不會突然無法正常工作
- 如果儲存的值超過20億,可使用long long
-
如果short
比int
小,則使用
short可以節省記憶體
- 通常,僅當有大型整型陣列時,才有必要使用short。
- 如果只需要一個位元組,可使用char
整型字面值:
-
整型字面值(常量)是顯示地書寫的常量,與C
相同,C
++能夠以3種不同的計數方式來書寫整數
- 10進位制
- 8進位制
- 16進位制
-
表示法:
-
C
++使用前一(兩)位來標識數字常量的進位制:
- 如果第一位為 1~9,則為10進位制——因此93是10進位制
- 如果第一位是 0,第二位為1~7,則為8進位制——因此042是8進位制
- 如果前兩位為 0x 或 0X,則為16進位制——因此0x42為16進位制
-
C
++使用前一(兩)位來標識數字常量的進位制:
-
程式示例:
//顯示16進位制和8進位制文字 #include <iostream> using namespace std; int main() { int chest = 42; int waist = 0x42; int inseam = 042;
cout << "Monsieur cuts a striking figure!\n"; cout << "chest = " << chest << " (42 in decimal)\n"; cout << "waist = " << waist << " (0x42 in hex)\n"; cout << "inseam = " << inseam << " (042 in octal)\n"; cin.get(); return 0; }程式輸出:
Monsieur cuts a striking figure!
chest = 42 (42 in decimal)
waist = 66 (0x42 in hex)
inseam = 34 (042 in octal)
- 注意:在預設情況下,ocut 以十進位制格式顯示整數,而不管這些整數在程式中是如何書寫的
- 這些表示方法僅僅是為了表達上的方便。但是不管把值書寫為10、012還是0xA,都將以相同的方式儲存在計算機中——被儲存為2進位制數
-
如果要以16
進位制或8
進位制方式顯示值,則可使用cout
的一些特殊性:
-
可使用標頭檔案iostream提供的控制符:
-
dec
- 十進位制
-
hex
- 十六進位制
-
oct
- 八進位制
-
dec
-
程式示例:
//以16進位制和8進位制顯示值 #include <iostream> using namespace std; int main() { int chest = 42; int waist = 42; int inseam = 42;
cout << "Monsieur cuts a striking figure!" << endl; cout << "chest = " << chest << " (decimal for 42)" << endl; cout << hex << "waist = " << waist << " (hexadecimal for 42)" << endl; cout << oct << "inseam = " << inseam << " (octal for 42)" << endl; cin.get(); return 0; }程式輸出:
Monsieur cuts a striking figure!
chest = 42 (decimal for 42)
waist = 2a (hexadecimal for 42)
inseam = 52 (octal for 42)
- cout << hex;等程式碼修改了cout顯示整數的方式
- 注意:由於識別符號hex位於名稱空間std中,而程式使用了該名稱空間,因此不能將hex用作變數名。然而,省略編譯指令using,而是用std::hex,則可以使用hex做變數名
-
可使用標頭檔案iostream提供的控制符:
C++如何確定常量的型別
-
假設在程式中使用常量表示一個數字
cout << "Year = " << 1492 << endl;
- 在C++中,除非有理由儲存為其他型別,否則C++將整型儲存為int型別
-
字尾
-
字尾是放在數字常量後面的字母,用於表示型別。
- 整數後面的l或L字尾表示該整數為long常量
- u或U字尾表示unsignedint常量
- ul(可以採用任何一種順序,大寫小寫均可)表示unsigned long 常量(由於小寫 l 看上去像1,因此應使用大寫L作字尾)
-
例如:
- 數字22022被儲存為int,佔16位
- 數字22022L被儲存為long, 佔32位
- 22022LU和22022UL都被儲存為unsigned long
- C++11提供了用於表示型別long long 的字尾 ll 和 LL
- 用於表示型別 unsigned long long 的字尾ull、Ull、uLL和ULL
-
字尾是放在數字常量後面的字母,用於表示型別。
-
長度
- 十六進位制數0x9c40 (4000) 將被表示為unsigned int。這是因為十六進位制常用來表示記憶體地址,而記憶體地址是沒有符號的,因此 usigned int比 long更適合用來表示16位的地址
char 型別:字元和小整數
- char型別是專為儲存字元(如字母和數字)而設計的。
- char型別是另一種整型。它足夠長,能夠表示目標計算機系統中的所有基本符號——所有的字母、數字、標點符號等。
- 雖然char最常被用來處理字元,但也可以將它用作比short更小的型別
-
程式示例:
// char型別 #include <iostream> using namespace std; int main() { char ch; cout << "Enter a character: " << endl; cin >> ch; cin.get(); cout << "Thank you for the " << ch << " character." << endl; cin.get(); return 0; }
程式輸出:
Enter a character:
A
Thank you for the A character.
- 注意:輸入時,cin將鍵盤輸入的A轉換為65,輸出時,cout將值65轉換為所顯示的字元A
-
下面程式引入了cout的一項特性——cout.put()函式,該函式顯示一個字元。
//對比char型別和int型別 #include <iostream> using namespace std; int main() { char ch = 'M'; int i = ch; cout << "The ASCII code for " << ch << " is " << i << endl; cout << "Add one to the character code:" << endl; ch = ch + 1; i = ch; cout << "The ASCII code for " << ch << " is " << i << endl;
//使用cout.put()成員函式顯示char cout << "Displaying char ch using cout.put(ch): "; cout.put(ch); //使用count.put()函式來顯示char常量 cout.put('!'); cout << endl << "Done" << endl;
cin.get(); return 0; }程式輸出:
The ASCII code for M is 77
Add one to the character code:
The ASCII code for N is 78
Displaying char ch using cout.put(ch): N!
Done
-
程式說明:
- 在程式中,'M'表示字元M的數值編碼,因此將char變數ch初始化'M',將把 i 變數這隻為77。
- 值的型別將引導cout選擇如何顯示值——這是智慧物件的另一個例子
-
即使通過鍵盤輸入的數字也被視為字元
char ch; cin >> ch;
-
如果輸入5並按回車,上述程式碼將讀取字元'5',並將其對應的ASCII碼儲存到變數ch中
int n; cin >> n;
- 如果輸入5並按回車,上述程式碼將讀取字元'5',將其轉換為相應的數字值5,並存儲到變數n中
-
如果輸入5並按回車,上述程式碼將讀取字元'5',並將其對應的ASCII碼儲存到變數ch中
-
成員函式
- 函式cout.put()是一個重要的C++OOP概念——成員函式
-
成員函式歸類所有,描述了操縱類資料的方法。要通過物件(如cout)來使用成員函式,必須用句點將物件名和函式名稱put()連線起來。意思是:
- 通過類物件cout來使用函式put()
- 句點被稱為成員運算子。
-
char字面值
- 在C++中,對於常規字元(如字母、標點符號和數字),最簡單的方法是將字元用單引號括起,這種表示方法代表的是字元的數值編碼
- C++還提供了一種特殊的表示方法——轉移序列
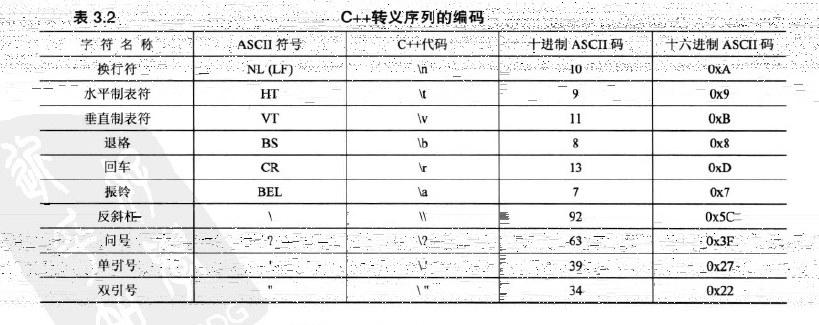
-
換行符可替代endl
,用於在輸出中重起一行。下面3
行程式碼都將游標移到下一行開頭:
cout << endl; cout << '\n'; cout << "\n";
-
可以將換行符嵌入到字串中,這通常比使用endl
方便
cout << endl <<endl << "然後呢?" << endl << "沒然後了" << endl; cout << "\n\n然後呢?\n沒然後了\n";
-
顯示數字時,使用endl
比輸入"\
n"
或'\n'
更容易些,但顯示字串時,在字串末尾新增一個換行符所需的輸入量更少些
cout << x << endl; cout << "我是一個字串\n";
-
可以基於字元的8
進位制和16
進位制編碼來使用轉義序列
-
例如字母M
的ASCII
碼為77
,對應的8
進位制數為115
,16
進位制數為0
x4d,可以用下面的轉義字元來表示該字元:\0115或\x4d。將這些編碼用單引號或雙引號括起。可以得到相應的字元常量
- 注意:在可以使用數字轉義序列或符號轉義序列(如\0x8 和 \b)時,應使用符號序列。數字表示方式與特定的SACII碼相關,而符號表示適用於任何編碼方式,其可讀性強
-
例如字母M
的ASCII
碼為77
,對應的8
進位制數為115
,16
進位制數為0
x4d,可以用下面的轉義字元來表示該字元:\0115或\x4d。將這些編碼用單引號或雙引號括起。可以得到相應的字元常量
-
程式清單3.7
- 該程式使用振鈴字元(\a)來提醒注意,使用退格字元(\b)來使游標向左退一格
-
程式示例:
//使用轉義序列 #include <iostream> using namespace std; int main() { cout << "\aOperation \"HyperHype\" is now activated!\n"; cout << "Enter your agent code:________\b\b\b\b\b\b\b\b"; long code; cin >> code; cin.get(); cout << "\aYou entered " << code << "...\n"; cout << "\aCode verified! Proceed with pian 23:\n"; cin.get(); return 0; }
程式輸出:
Operation "HyperHype" is now activated!
Enter your agent code:1234567_
You entered 1234567...
Code verified! Proceed with pian 23:
-
通用字元名
- C++實現支援一個基本的源字符集,即可用來編寫原始碼的字符集;還有一個基本的執行字符集,它包括在程式執行期間可處理的字元
-
C
++有一種表示這種特殊字元的機制,他獨立於任何特定的鍵盤,使用的是通用字元名;例如:
int k\u00F6repr; cout << "Let them eat g\u00E2teau.\n";
- 這些表示的是字元的ISO 10646碼點(由Unicode提供)
-
signed char 和 unsigned char
- 與int不同的是,char在預設的情況下既不是沒有符號,也不是有符號,是否有符號由C++實現決定
- unsigned char的表示範圍為0~255,而signed char 的表示範圍為-128~127
-
wcha_t
- wcha_t(寬字元型別)
- 可以表示擴充套件字符集
- 它是一種整數型別
- 它有足夠的空間
- 可以表示系統顯使用的最大擴充套件字符集
-
cin 和 cout 將輸入和輸出看做是char流,因此不適用於用來處理wcha_t型別;但標頭檔案iostream最新版本提供了作用相似的工具:
- win 和 wcout ——可用於處理wcha_t流
-
可以通過加上字首L來指示寬字元常量和寬字串,例如:
wchar_t bob = L'p'; wcout << L"tall" << endl;
- 上述程式碼將字母p的wcha_t版本儲存到變數bob中,並顯示tall的wcha_t版本
-
C++11新增的型別:char16_t 和 char32_t
-
char16_t
- 無符號,長16位
- 使用字首(小寫)u表示字元常量和字串常量,如:u'C' 和 u"be good"
-
char32_t
- 無符號,長32位
- 使用字首(大寫)U表示字元常量和字串常量,如:U'C' 和 U"be good"
- 與wchat_t一樣,char16_t 和 char32_t 也都有底層型別——一種內建的整型
-
char16_t
-
bool型別
-
布林變數的值可以是 true 或 false,例如:
bool is_ready = true;
-
字面值true和false都可以通過提升轉換為int型別,true被轉換為1,而false被轉換為0:
int ans = true; int promise = false;
-
任何數字值都可以被隱式轉換,即不用顯示強制轉換為bool值,任何非0值都被轉換為true,而0被轉換為false:
bool start = -100; boo stop = 0;
-
布林變數的值可以是 true 或 false,例如:
-
程式說明: