Google Protocol Buffer 的使用和原理
簡介
Google Protocol Buffer( 簡稱 Protobuf) 是 Google 公司內部的混合語言資料標準。Protobuf是一種輕便高效的結構化資料儲存格式,可以用於結構化資料序列化,或者說序列化。它很適合做資料儲存或 RPC 資料交換格式。可用於通訊協議、資料儲存等領域的語言無關、平臺無關、可擴充套件的序列化結構資料格式。目前提供了 C++、Java、Python、JS、Ruby等多種語言的 API。
安裝
安裝步驟如下所示:
tar -xzf protobuf-2.1.0.tar.gz cd protobuf-2.1.0 ./configure --prefix=$INSTALL_DIR make make check make install
清單1.Proto檔案
package lm;
message helloworld
{
required int32 id = 1; // ID
required string str = 2; // str
optional int32 opt = 3; //optional field
}編譯proto檔案
protoc -I=./ --cpp_out=$./ lm.hello.proto
(用法:protoc -I=$SRC_DIR --cpp_out=$DST_DIR $SRC_DIR/*.proto)命令將生成兩個檔案:
lm.helloworld.pb.h
lm.helloworld.pb.cc , C++ 類的實現檔案
在生成的標頭檔案中,定義了一個 C++ 類 helloworld,後面的 Writer 和 Reader 將使用這個類來對訊息進行操作。諸如對訊息的成員進行賦值,將訊息序列化等等都有相應的方法。
清單 2. Writer 的主要程式碼
#include "lm.helloworld.pb.h" int main(void) { lm::helloworld msg1; msg1.set_id(10080); msg1.set_str(“hellow”); // Write the new address book back to disk. fstream output("./log", ios::out | ios::trunc | ios::binary); //附加寫二進位制檔案,存在先刪除 if (!msg1.SerializeToOstream(&output)) { cerr << "Failed to write msg." << endl; return -1; } return 0; }
清單 3. Reader
#include "lm.helloworld.pb.h"
void ListMsg(const lm::helloworld & msg) {
cout << msg.id() << endl;
cout << msg.str() << endl;
}
int main(int argc, char* argv[]) {
lm::helloworld msg1;
fstream input("./log", ios::in | ios::binary);
if (!msg1.ParseFromIstream(&input)) {
cerr << "Failed to parse address book." << endl;
return -1;
}
ListMsg(msg1);
return 0;
}編譯:
g++ test.cc lm.helloworld.pb.cc -I./ -L/usr/local/lib -o test.out –lprotobuf
執行:
0000000: e008 124e 6806 6c65 6f6c 0077 / /hexdump 注意大小端
0000000: 08e0 4e12 0668 656c 6c6f 77 ..N..hellow //Vim開啟已經自動調整大小端了
我們生成如下的一個訊息 Test1:
Test1.id = 10086;
Test1.str = “hellow”;
Key 的定義如下:
field_number << 3 | wire_type
|
08 |
(1 << 3) | 0 (id欄位,欄位號為1,型別varint) |
|
e0 4e |
(原始資料:11100000 01001110 去掉標誌位並按照小端序交換: 1001110 1100000(二進位制) = 10080(十進位制) ) |
|
12 |
(2 << 3) | 2 (str欄位,欄位號為2,型別str) |
|
06 |
字串長度為6個位元組 |
|
68 65 6c 6c 6f 77 |
(“hellow”字串ASCII編碼) |
FAQ:
protobuf與json,xml比優點在哪裡?
- 二進位制訊息,效能好/效率高(空間和時間效率都很不錯,佔用空間json 1/10,xml 1/20)
- proto檔案生成目的碼,簡單易用
- 序列化反序列化直接對應程式中的資料類,不需要解析後在進行對映(XML,JSON都是這種方式)
- 支援向前相容(新加欄位採用預設值)和向後相容(忽略新加欄位),簡化升級
使用protobuf出錯:protoc: error while loading shared libraries: libprotoc.so.9: cannot open shared object file:No such...
解決方法:linux 敲擊命令:export LD_LIBRARY_PATH=/usr/local/lib
附錄:
Wire Type 可能的型別如下表所示:
|
Type |
Meaning |
Used For |
|
0 |
Varint |
int32, int64, uint32, uint64, sint32, sint64, bool, enum |
|
1 |
64-bit |
fixed64, sfixed64, double |
|
2 |
Length-delimi |
string, bytes, embedded messages, packed repeated fields |
|
3 |
Start group |
Groups (deprecated) |
|
4 |
End group |
Groups (deprecated) |
|
5 |
32-bit |
fixed32, sfixed32, float |
Varint編碼
Varint 是一種緊湊的表示數字的方法。它用一個或多個位元組來表示一個數字,值越小的數字使用越少的位元組數。這能減少用來表示數字的位元組數。
比如對於 int32 型別的數字,一般需要 4 個 byte 來表示。但是採用 Varint,對於很小的 int32 型別的數字,則可以用 1 個 byte 來表示。當然凡事都有好的也有不好的一面,採用 Varint 表示法,大的數字則需要 5 個 byte 來表示。從統計的角度來說,一般不會所有的訊息中的數字都是大數,因此大多數情況下,採用 Varint 後,可以用更少的位元組數來表示數字資訊。下面就詳細介紹一下 Varint。
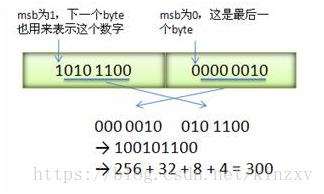
Varint 中的每個 byte 的最高位 bit 有特殊的含義,如果該位為 1,表示後續的 byte 也是該數字的一部分,如果該位為 0,則結束。其他的 7 個 bit 都用來表示數字。因此小於 128 的數字都可以用一個 byte 表示。大於 128 的數字,比如 300,會用兩個位元組來表示:1010 1100 0000 0010
下圖演示了 Google Protocol Buffer 如何解析兩個 bytes。注意到最終計算前將兩個 byte 的位置相互交換過一次,這是因為 Google Protocol Buffer 位元組序採用 little-endian 的方式。
圖 6. Varint 編碼