
正則表示式在python中的應用
-
正則表示式簡介
正則表示式為高階的文字模式匹配、抽取、或者文字形式的搜尋與替換提供了基礎。正則表示式(regex)是由字元和特殊符號組成的字串,它們描述了模式的重複或者表述多個字元(就是描述了一個可以識別各種字串的模式),於是正則表示式能夠按照某種模式匹配一系列有相似特徵的字串。
Python通過呼叫標準庫中的re模組來使用正則表示式。(載入模組此文閉口不談,預設自己會)
1.1 特殊符號和字元
常見的特殊符號和字元,這些就是正則表示式的根基。
| 表示法 | 描述 |
| 符號 | |
| str | 匹配字串的字面值 |
| re1 | re2 | 匹配正則表示式re1或者re2 |
| . | 匹配任何字元(除了換行符\n之外) |
| ^ | 匹配字串的起始部分 |
| $ | 匹配字串的終止部分 |
| * | 匹配0次或者多次前面出現的正則表示式 |
| + | 匹配1次或者多次前面出現的正則表示式 |
| ? | 匹配0次或者1次前面出現的正則表示式 |
| {N} | 匹配N次前面出現的正則表示式 |
| {M,N} | 匹配M-N次前面出現的正則表示式 |
| {M,} | 匹配至少M次前面出現的正則表示式 |
| [...] | 匹配來自字符集的任意單一字元 |
| [x-y] | 匹配x-y範圍中的任意單一字元(數字也可使用此方法[0-9]) |
| [^...] | 不匹配此字符集中出現的任何一個字元,包括某一範圍的字元 |
| (...) | 匹配封閉的正則表示式(實際使用中就是可以滿足你匹配一個詞語、成語或者單詞的需要),然後另存為子組 |
| .+?或者.*? | 非貪婪模式匹配(後面將會提到) |
| 特殊字元 | |
| \d | 匹配任何十進位制數字,與[0-9]效果一樣。\D與之相反 |
| \w | 匹配任何字母數字字元,與[A-Za-z0-9]相同, \W與之相反。 |
| \s | 匹配任何空格字元,與[\n\t\r\v\f]相同 (防止不懂,\n\r表示換行,\t為製表符,\v為垂直製表符,\f為換頁符。) |
| \b | 匹配任何單詞邊界(\B與之相反) |
| \N | 匹配已儲存的子組 |
| \c | 匹配特殊字元(去掉特殊字元的特殊含義) |
| 擴充套件表示法 | |
| (?iLmsux) | 在正則表示式中嵌入一個或者多個特殊“標記”引數 |
| (?:...) | 一個匹配不用儲存的分組 |
| (?P<name>...) | 像一個僅由name標識而不是數字ID標識的正則分組匹配 |
| (?P=name) | 在同一字串中匹配由(?P<name>分組的之前文字) |
| (?#...) | 表示註釋 |
| (?=...) | 匹配條件是如果。。出現在之後的位置,而不使用輸入字串,稱作正向前視斷言 |
| (?!...) | 匹配條件是如果。。不出現在之後的位置,而不使用輸入字串,稱作負向前視斷言 |
| (?<=....) | 匹配條件是如果。。出現在之前的位置,而不使用輸入字串,稱作正向後視斷言 |
| (?<!...) | 匹配條件是如果。。不出現在之前的位置,而不使用輸入字串,稱作負向後視斷言 |
| (?(\d/name)Y\N) | 如果分組所提供的id或者name(名稱)存在,就返回正則表示式的條件匹配Y,如果不存在,就返回N |
1.2 正則表示式模組下函式
re模組函式
re.complie(pattern,flags=0) 使用任何可選的標記來編譯正則表示式的模式,然後返回一個正則表示式物件。
re模組函式和正則表示式物件的方法
re.match(pattern,string,flags = 0) 嘗試使用帶有可選的標記的正則表示式的模式是來匹配字串(從字串的起始部分 開始匹配)。如果匹配成功,就返回匹配物件;如果失敗,就返回None。
re.search(pattern,string,flags= 0) 使用可選標記搜尋字串中第一次出現的正則表示式模式。如果匹配成功,則返回匹 配 物件;如果失敗就返回None。
re.findall(pattern,string) 查詢字串中所有(非重複)出現的正則表示式模式,並返回一個匹配列表。
re.finditer(pattern,string) 與findall()函式相同,返回的是一個迭代器。對於每一次匹配,迭代器都返回一個匹配物件。
re.split(pattern,string,max=0) 根據正則表示式的模式分隔符,spilt函式將字串分割成列表,然後返回成功匹配的 列表,分割最多操作max次。
re模組函式和正則表示式物件方法
re.sub(pattern,replace,string,count = 0) 使用replace替換所有正則表示式的模式在字串中出現的位置,除非定義 count,否則就將替換掉所有出現的位置。
常用的匹配物件方法
group(num=0) 返回整個匹配物件,或者編號為num的特定子組 groups(deault = None) 返回一個包含所有匹配子組的元組(如果匹配不成功,則返回空元組) groupdict(deault=None) 返回一個包含所有匹配的命名子組的字典,所有子組名稱作為字典的鍵(如果匹配失敗,返回空字典) 常用的模組屬性 re.I、re.IGNORECASE 不區分大小寫的匹配 re,L、re.LOCALE 根據所使用的本地語言環境通過\w、\W、\B、\b、\S、\s實現匹配。 re.M、re.MULTILINE ^和$分別匹配目標字串中行的起始和結尾,而不是嚴格匹配整個字串本身的起始和結尾.
re.S 點號能夠匹配所有字元 re.X 通過反斜線轉義 1.3 疑點
1、匹配單詞邊界:\b(匹配的是位置,不是字元)
注意:邊界位置指的是匹配的那一側單詞與緊接著的是非字母數字之間的位置。
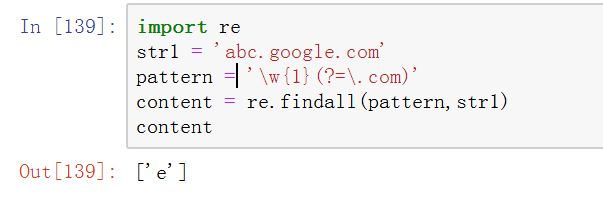
2、擴充套件表示法中(?=.)(正向前視斷言)。匹配的是位置,並不是字元。然後以匹配到的位置進行前向斷言。
下圖所示中,正則表示式模式表示若某個字串後面跟著.'.com' 則匹配前面的字元。結果很顯然,匹配到.com位置處(圖中黑線處)然後向前匹配。
tips:需要注意的是,匹配是從位置處向前按順序匹配的。
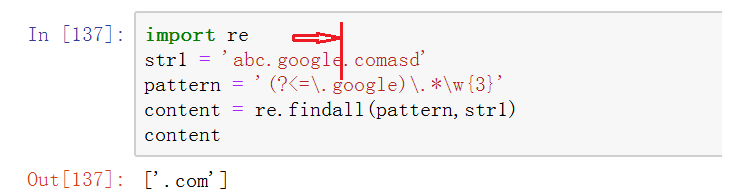
2、 擴充套件表示法中(?<=.)(正向後視斷言)
圖中正則表示式模式表示:如果一個字串前面跟著字串.google 那麼則進行匹配之後的字元。
正向前視和正向後視斷言:前視與後視字面意思就是向前看與向後看。在條件滿足時在位置處向前看與向後看。


3、字符集[ ]的使用
正則表示式能夠匹配字符集中包含的任何字元。
'x[abc]' #該正則表示式模式表示:匹配兩個字元的字串,第一個字母為x,後面跟著a或b或c。('xa','xb','xc'是所有可能匹配到的情況) '[ab][cd]' ##該正則表示式模式表示:匹配兩個字元的字串.第一個字串為a或者b,第二個字元為c或者d。4、貪婪匹配:
+? ?? *? 這三種模式可以避免貪婪匹配。5、閉包操作符
星號或者星號操作符(*)將匹配其左邊的正則表示式出現零次或者多次的情況(在計算機程式語言和編譯原理中,該操作稱為 Kleene 閉包)。加號(+)操作符將匹配一次或者多次出現的正則表示式(也叫做正閉包操作符)