
【MySQL】InnoDB 記憶體管理機制 --- Buffer Pool
InnoDB Buffer Pool
- 是一塊連續的記憶體,用來儲存訪問過的資料頁面
- innodb_buffer_pool_size 引數用來定義 innodb 的 buffer pool 的大小
- 是 MySQL 中擁有最大的記憶體的模組
- Innodb 中,資料的訪問是按照頁/塊(預設為16KB)的方式從資料檔案中讀取到 buffer pool中,然後在記憶體中用同樣大小的記憶體空間做一個對映
為了提高訪問速度(也就是儘可能多地把資料檔案中的頁/塊放到 buffer pool 中),MySQL 預先就分配/準備了許多這樣的空間,為的就是與MySQL資料檔案中的頁做交換,來把資料檔案中的頁放到事先準備好的記憶體中。
buffer pool 按照最少使用演算法(LRU),來管理 buffer pool ,去搜了一下這個演算法:
[ LRU(Least recently used),快取淘汰演算法。比較簡單的一個演算法,就是根據“近期”的資料訪問記錄來對buffer中的資料進行淘汰。核心思想:“如果某個資料最近被訪問過,則將來被訪問的概率更高”。
最常見的是使用連結串列儲存快取資料,這也是 innodb buffer pool 的管理方式。因此,最常訪問的放在連結串列頭,最不常訪問的放在連結串列尾。
【命中率】
當存在熱點資料的時候,LRU的效果很好;但是偶然性或者週期性的訪問會導致LRU的命中率急劇下降。]
當 buffer pool 滿了的時候,就用新的資料代替 buffer pool 末尾的資料。
[email protected]][(none)][02:40:28]> show engine innodb status\
![]()

InnoDB為緩衝區和控制結構保留了額外的記憶體,因此總分配的空間大約比指定的緩衝池大小大10%。
![]()

Buffer Pool 有兩個區域,一個是 sublist_of_new_block 區域(熱資料),一個是 sublist_of_old_clocks 區域(不經常訪問的)。當訪問的時候,如果沒有相應資料則從磁碟中先讀入資料到 sublist of old blocks 區域,然後移動到 sublist of new blocks 區域(實際上所謂的 熱資料區域和 old 資料區域都是在 LRU list 裡面,只是 sublist 0f new blocks 在連結串列的前面,sublist of old blocks 在連結串列的尾部)。
PS:
Pages made young:從 old 區移動到 new 區有多少個頁
Pages made not young:因為 innodb_old_blocks_time 的設定而導致頁沒有從 old 部分啟動到 new 部分的操作。
Buffer pool hit rate:表示緩衝池的命中率,通常這個值不應該小於95%,如果小於95%,則應該看看是不是由於全表掃描而導致 LRU 列表有汙染。
同時,show engine innodb status 顯示的不是當前的實時狀態。
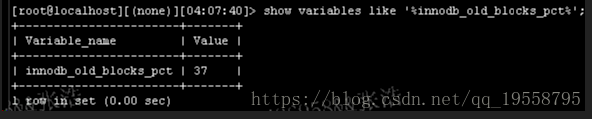
為了避免某些全表掃描的資料進入 sublist of new blocks 區域,從5.5.x 開始,innodb_old_blocks_pct 引數可以控制進入 sublist of old blocks 區域的百分比,預設是37%(即 sublist of old blocks 佔整個 LRU list 的百分比,如上圖所示:189598/514065=36.88%,接近37%)。---當全表掃描或者 dump 時,可以將 innodb_old_blocks_pct 設定的小些。
![]()
這個過程還會設計 innodb_old_blocks_time 引數,比如 sublist of old blocks 中的某個資料塊被訪問到了,他就會等待 innodb_old_blocks_time (毫秒),然後再移動到 sublist of new blocks 中。一般不會去動這個引數
![]()

在5.7.4 之前,如果想要更改 innodb_buffer_pool_size 的大小,只能 kill 掉程序才行,但是5.7.5開始,不需要停止程序就可以動態更改 innodb_buffer_pool_size 的大小。
同時,如果 innodb_buffer_pool_size 的大小超過1G,則需要通過調整 innodb_buffer_pool_instances=N(即開啟多個記憶體緩衝池,每個緩衝池的大小相同,把需要緩衝的資料 hash 到不同的緩衝池中,這樣就可以進行並行的記憶體讀寫),把 buffer pool 分成若干個 instance 可以提高 MySQL 處理請求的併發能力,因為 buffer pool 通過連結串列管理頁,同時為了保護頁,需要在存取的時候對連結串列加鎖,因此多執行緒下,併發去讀寫 buffer pool 需要鎖的競爭和等待。
因此,修改為多個 instance ,每個 instance 管理自己的記憶體和連結串列,可以提升請求的併發能力。
Buffer Pool 實現原理
server啟動後也會啟動所有的內嵌引擎,Innodb 啟動後會通過 buf_pool_init 初始化所有的子系統(從命名來看貌似只是初始化buffer pool的,不確定是否裡面有呼叫其他的函式來初始化其他的系統)。
InnoDB用一塊記憶體區做 IO 快取池,該快取池不僅用來快取 InnoDB 的索引塊,而且也能用來快取 InnoDB 的資料塊,這於 MyISAM 不同。
Buffer Pool 邏輯上由 freelist、flush list 和 LRU list 組成。free list 是空閒快取塊列表,由下面說的 - FREE連結串列 來管理;flush list 是需要重新整理到磁碟的快取塊列表,由下面所說的 flush_list連結串列 來管理;LRU list 是 InnoDB 正在使用的快取塊,也是 Bffer Pool的核心。
在程式碼中,Buffer Pool 用 buf_pool_t 結構體來描述,也是管理 buffer_pool 的核心工具,包含四個部分:
- FREE連結串列:儲存這個例項中所有空閒的頁面
- flush_list連結串列:儲存所有被修改過且需要刷到檔案中的頁面
- mutex:保護例項,因為同一時刻,只能被一個執行緒訪問
- chunks:儲存第一個頁面的實體地址(因為 buffer_pool 中的頁面都是放在一塊連續的記憶體中,即順序儲存,所以知道了第一個頁面的地址指標,就可以通過這個指標訪問所有的其他頁面)
上面說的 FREE連結串列 和 lush_list連結串列 又是用來管理的 buf_page_t 結構體的,而 buf_page_t 結構體又被 buf_block_t 所管理。buf_page_t 和 buf_block_t 是一一對應的,都對應 Buffer Pool 中的一個 Page ,只是 buf_page_t 是邏輯的,而 buf_block_t 包含一部分物理的概念,比如這個頁面的首地址指標 frame等。
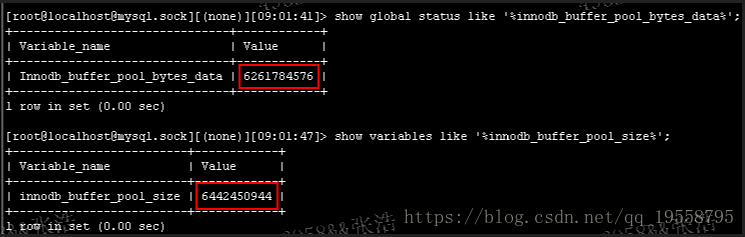
初始化一個 Buffer Pool 的例項空間的函式是 buf_chunk_init。一個 Buffer Pool 例項空間按資料結構來看分為兩部分:buf_block_t(buffer pool中頁面控制頭結構資訊,每一個控制頭資訊管理一物理頁面,這些控制頭資訊的儲存佔用了部分空間,所以 innodb_buffer_pool_size 總是比 innodb_buffer_pool_bytes_data 大。);另外一部分就是儲存 page 的,由 buf_page_t 來管理。
![]()
Buffer Pool 初始化過程:Buffer Pool 頁面(buf_page_t)在這個例項池中從後向前分配 page,每次分配一個頁面,同時控制結構(buf_block_t)從前向後分配來和剛剛分配的頁面一一對應(也就是上文說的 buf_block_t 與 buf_page_t 一一對應)。這樣前後同時分配也會導致一個問題:因為 block 和 page 是成對的,所以很大可能也很正常地就會“剩下”一些空間(不足以再分配一對 block 與 page)。
buf_pool_t 結構體用來管理整個 buffer pool 例項,而 buf_block_t 用來管理頁(buf_page_t),buf_block_t 主要包括一下四個部分:
其對應的頁面的 frame
其所對應的 buf_page_t 的資訊(所屬表空間的ID號、頁面號等)
保護這個頁面的互斥量mutex()
訪問頁面時對這個頁面上的 lock(read/write)等
以上,初始化頁面完成後,這些頁面的狀態還是未使用(buf_block_not_used),因此將頁面加入到 -FREE連結串列 中,以供使用。至此,緩衝池的一個例項就初始化完成了,其餘例項初始化過程相同。
對於整個 Buffer Pool 而言,各個例項之間是完全獨立的,相互之間沒有任何關係,單獨申請、單獨管理、單獨刷盤。
在具體使用中,針對同的頁面,當一條 SQL 從客戶端發往服務端時,會通過一個 HASH 演算法,來對映到一個具體的例項中。
以上,就是整個 Buffer Pool 多例項的管理機制,通過多例項,可以減少系統執行過程中不同頁面之間一些操作的相互影響,從而很好地解決了由於頁面之間的資源爭搶導致的效能低下問題。