
Redis簡介(二)------為什麼Redis快取速度這麼快
首先介紹下硬碟資料庫和Redis的工作模式
一、硬碟資料庫的工作模式:
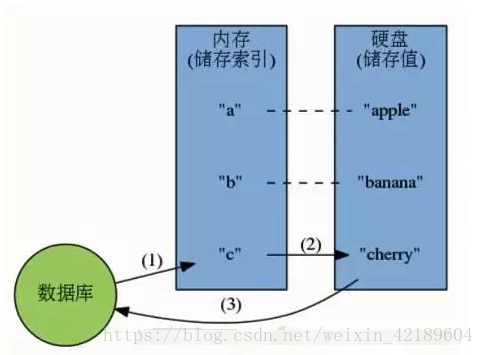
需要先從資料讀取資料到記憶體,記憶體中的資料儲存到硬碟,我們更改硬碟的資料後在儲存到資料庫。這裡的步驟較多,而且還佔用我們的硬碟容量。
二、記憶體資料庫的工作模式:

這種方式相比硬碟資料庫的方式少了記憶體到硬碟這一步,速度回快很多,而且不佔用我們的硬碟容量。我們用的Redis就是基於這種方式的,看完Redis簡介(一)和上面的描述,我們對於Redis有了一定的瞭解。下面我們再介紹Redis作為快取為什麼速度這麼快。
三、Redis到底有多快
Redis採用的是基於記憶體的採用的是單程序單執行緒模型的 KV 資料庫,由C語言編寫,官方提供的資料是可以達到100000+的QPS(每秒內查詢次數)。這個資料不比採用單程序多執行緒的同樣基於記憶體的 KV 資料庫 Memcached 差!有興趣的可以參考官方的基準程式測試:https://redis.io/topics/benchmarks
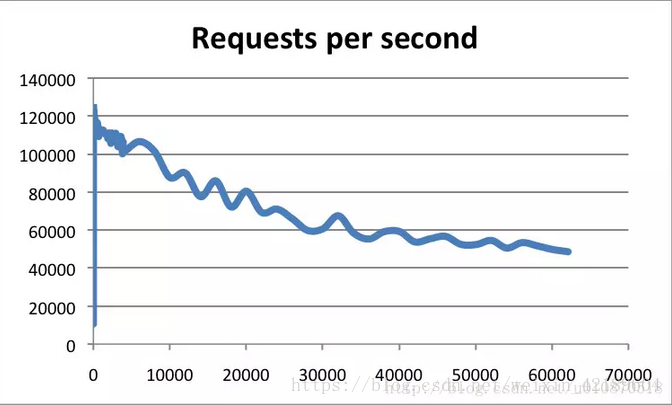
橫軸是連線數,縱軸是QPS。此時,這張圖反映了一個數量級,希望大家在面試的時候可以正確的描述出來,不要問你的時候,你回答的數量級相差甚遠!
四、Redis為什麼這麼快
1、完全基於記憶體,絕大部分請求是純粹的記憶體操作,非常快速。資料存在記憶體中,類似於HashMap,HashMap的優勢就是查詢和操作的時間複雜度都是O(1);
2、資料結構簡單,對資料操作也簡單,Redis中的資料結構是專門進行設計的;
3、採用單執行緒,避免了不必要的上下文切換和競爭條件,也不存在多程序或者多執行緒導致的切換而消耗 CPU,不用去考慮各種鎖的問題,不存在加鎖釋放鎖操作,沒有因為可能出現死鎖而導致的效能消耗;
4、使用多路I/O複用模型,非阻塞IO;
5、使用底層模型不同,它們之間底層實現方式以及與客戶端之間通訊的應用協議不一樣,Redis直接自己構建了VM 機制 ,因為一般的系統呼叫系統函式的話,會浪費一定的時間去移動和請求;
以上幾點都比較好理解,下邊我們針對多路 I/O 複用模型進行簡單的探討:
(1)多路 I/O 複用模型
多路I/O複用模型是利用 select、poll、epoll 可以同時監察多個流的 I/O 事件的能力,在空閒的時候,會把當前執行緒阻塞掉,當有一個或多個流有 I/O 事件時,就從阻塞態中喚醒,於是程式就會輪詢一遍所有的流(epoll 是隻輪詢那些真正發出了事件的流),並且只依次順序的處理就緒的流,這種做法就避免了大量的無用操作。
這裡“多路”指的是多個網路連線,“複用”指的是複用同一個執行緒。採用多路 I/O 複用技術可以讓單個執行緒高效的處理多個連線請求(儘量減少網路 IO 的時間消耗),且 Redis 在記憶體中操作資料的速度非常快,也就是說記憶體內的操作不會成為影響Redis效能的瓶頸,主要由以上幾點造就了 Redis 具有很高的吞吐量。