深入理解hadoop值MapReduce
一、與HDFS一樣,Hadoop MapReduce也是採用了Master/Slave(M/S)架構。主要元件有Client、JobTracker、TaskTracker和Task。鞋面分別對幾個元件介紹

(1).Client:使用者編寫的MapReduce程式通過Client提交到JobTracker端;同時,使用者可以銅鼓Client端提供的介面檢視作業執行狀態。在Hadoop內部用Job表示MapReduce程式。一個MapReduce程式可對應若干個作業,而且每個作業會被分解為若干個Map/Reduce任務
(2)Job Tracker:主要負責資源監控和作業的排程。JobTracker監控所有TaskTracker與作業的健康狀況,一旦發現失敗情況後,就會將相應的任務轉移到其他節點上去,同時JobTracker會跟蹤任務的執行進度、資源使用量等資訊,並將這些資訊告訴任務排程器,任務排程器會在資源出現空閒的時候,選擇合適的任務使用這些資源。任務排程器是一個可以插拔的資源,使用者可以根據自己需要的需要設計相應的資源排程器
(3)TaskTracker:週期性的通過Heartbeat將本節點的資源使用情況和任務執行進度傳送給JobTracker,同時會接收JobTracker傳送來的命令並執行相應的操作。TaskTracker使用slot等量劃分本節點的資源量。slot代表計算資源。一個Task獲取一個slot後才有機會執行,而Hadoop排程器的作用是將多個TaskTracker上的空閒slot分配給Task使用,slot分為Map slot和Reduce slot兩種,分別提供Map Task和Reduce Task使用。TaskTracker通過slot數目限定Task的併發度
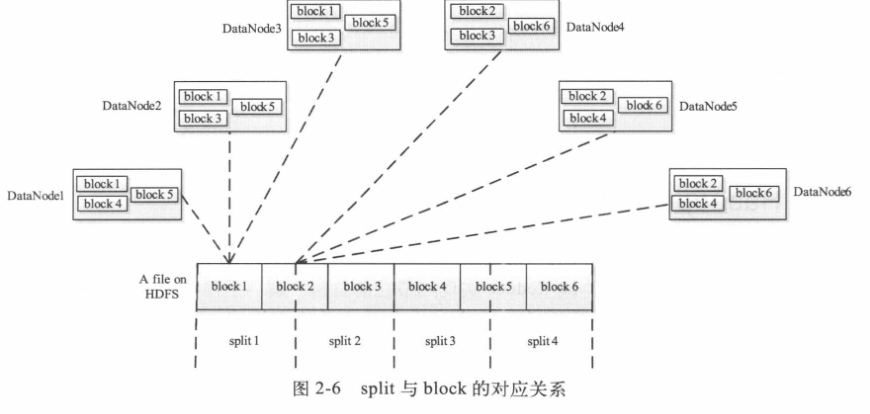
(4)Task:分為Map Task和Reduce Task兩種,均由Task Tracker啟動。因為HDFS以固定大小的block為基本單位進行儲存資料,對於MapReduce而言,其處理單位是split。split與block關係對應為下圖,split是一個邏輯概念,他只包含一些元資料資訊,比如資料起始位置、資料長度、資料所在的節點等資訊。劃分方法由使用者自己決定,但是需要注意的是:split的多少決定了Map Task的數目,因為每個split會交給一個Map Task進行執行
(5)Map Task執行的過程如下圖所示。Map Task先對split進行迭代解析成一個個key/value對,依次呼叫使用者自定義的map()函式進行處理,最終將臨時結果存放到磁碟上,其中臨時資料被劃分成一個個partition,每個partition將被一個Reduce Task處理。

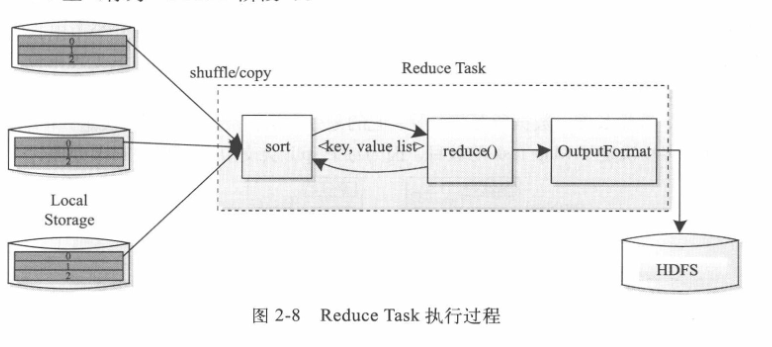
Reduce Task執行的過程如下圖所示。也分為三個階段:(1)從遠端節點讀取Map Task中間結果(稱之為shuffle階段)
(2)按照key對key/value對進行排序(稱之為Sort階段)
(3)依次讀取<key,value list>,呼叫使用者自定義的reduce()函式,將最終結果存放到HDFS上。