
關於Elasticsearch裡面聚合group的坑
我們都知道Elasticsearch是一個分散式的搜尋引擎,每個索引都可以有多個分片,用來將一份大索引的資料切分成多個小的物理索引,解決單個索引資料量過大導致的效能問題,另外每個shard還可以配置多個副本,來保證高可靠以及更好的抗併發的能力。
將一個索引切分成多個shard,大多數時候是沒有問題的,但是在es裡面如果索引被切分成多個shard,在使用group進行聚合時,可能會出現問題,這個在官網文件裡,描述也非常清楚
下面就針對官網的例子,描述下,group count如果有多個shard可能會出現的問題
假設我們現在,我們有一份商品的索引資料,它有3個shard,每個shard的資料如下所示:
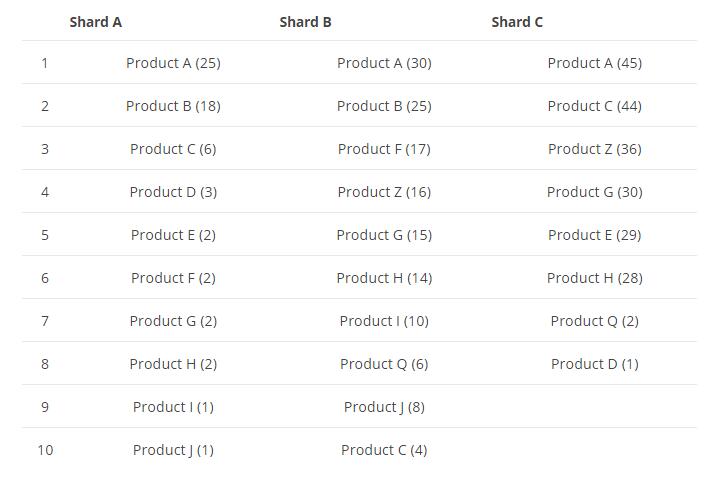
現在我們的需求是,按商品分組求top5的商品,es收到這個請求後,會去搜索這三個shard,然後子每個shard上面取top5,資料如下圖所示:
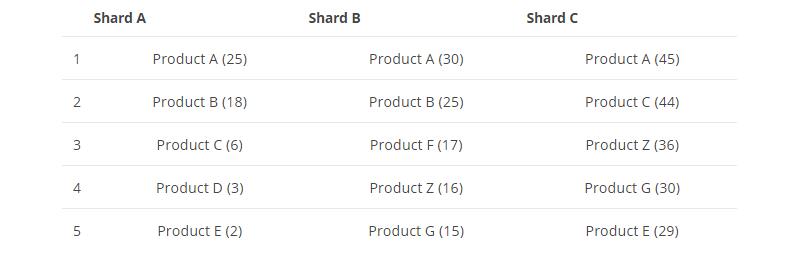
最後,將三個shard的top5的資料,最後做一下匯聚然後最終排序取top5結果如下圖:
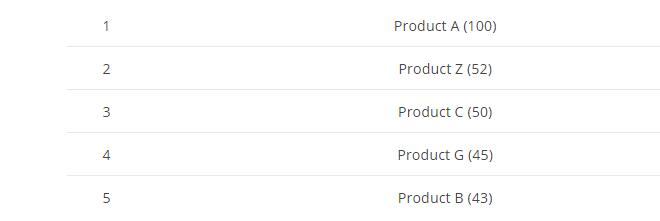
最後我們發現這個top5的結果,並不是100%精確的,只是一個近似精確的結果值:
Product A在所有top5的shard資料裡面都存在,所以它的結果是精確的, Product C僅僅返回了 shard A 和 C裡面的top5的資料,所以這裡顯示50是不精確的, Product C在shard B裡面也存在,但是它在 top5裡面沒有出現,所以group後的結果實際上是有誤差的,再來看下 Product Z僅僅返回了2個shards的資料 因為第三個裡面不存在,所以它的結果是準確的,最後我們注意下 Product H實際上它的總數是44,橫跨三個shard 但是它在每個shard的top5裡面並沒有出現,所以最終的top5裡面也沒有這條資料,這樣看來最終的top5的值並不是100% 準確的,這一點在設計和使用es的時候需要特別注意。
雖然我們可以調大返回size的個數來提高精確度,但是size個數的提升,也意味著有更多的資料會被返回,從而會導致檢索效能的下降,這一點是需要找到平衡點的。
那麼有沒有方法避免這種不精確的統計的呢?
答案是有的,es官網文件裡面也提到,總共有2種:
第一種:
聚合操作在單個shard時是精確的,也就是說我們索引的資料全部插入到一個shard的時候 它的聚合統計結果是準確的。
第二種:
在索引資料的時候,使用route路由欄位,將所有聚合的資料分佈到同一個shard即可,這樣再聚合時也是精確的。
上面的兩種辦法都是可以解決的,第一種適合資料量不大的場景下,我們直接把資料放在一份索引裡面,第二種辦法適合資料量比較大的場景下,我們通過業務欄位將相同屬性的資料路由在同一個shard裡面即可,具體使用哪個需要和具體的業務場景相結合。
總結:
es雖然很強大,但是在一些場景下也是有侷限的,比如上面提到的聚合分組的這個情況,或者聚合分組+分頁的情況,此外min,max,sum這些函式在多個shard中聚合結果是準確的,count是近似準確的,但是es能保證top 前幾的資料是精確的,這也是為什麼搜尋引擎一般都返回top n資料作為最終的返回結果,當然上面提到那個例子,如果聚合的key本來就很少,那麼它的聚合結果也是準確的,比如按性別,月份聚合,因為這些返回的key,都是有限的,所以結果沒問題,但是一旦對分組的個數沒法確定,這種情況下出現問題的機率就比較大,跨表或者跨分片聚合其實在任何db系統裡面都會存在這種問題,所以我們應該儘量在設計業務時就考慮到這種特殊情況,然後最終做特殊處理。