
Perl正則表示式超詳細教程
前言
想必學習perl的人,對基礎正則表示式都已經熟悉,所以學習perl正則會很輕鬆。這裡我不打算解釋基礎正則的內容,而是直接介紹基礎正則中不具備的但perl支援的功能。關於基礎正則表示式的內容,可參閱基礎正則表示式。
我第一個要說明的是,perl如何使用正則。還記得當初把《精通正則表示式》的書看了一遍,把perl正則也學了個七七八八,但是學完後卻不知道怎麼去使用perl正則,雖然裡面也介紹了一點如何使用perl語言,grep的"-P"選項使用的也是perl正則,ack工具支援的也完全是perl正則,但都沒有完整地體現perl正則的功能,總感覺缺點啥。最大的無奈莫過於此了,學了知識,卻不知道怎麼完整地應用。所以,我把如何使用perl正則來匹配資料放在最開頭介紹,包括匹配指定字串、匹配變數、匹配標準輸入(如管道傳遞的資料)以及匹配檔案中的每一行資料,而且後文我假設各位和我當初一樣,完全沒有perl語言基礎,所以我會介紹一些perl語言和後文相關的語法,確保全文學習過程沒有任何阻塞。
另外,本系列只介紹匹配操作,關於內容替換,因為和學習使用perl正則並無多大關係,所以替換相關的將在下一篇文章單獨解釋。
這裡推薦一個學正則非常好的資料:stackflow上關於各種語言(perl/python/.net/java/ruby等等)的正則的解釋、示例,這裡收集的都是對問題解釋的非常清晰且非常經典的回答。在我學習perl正則的時候,對有些功能實在理解不了(想必你也一定會),就會從這裡找答案,而它,也從來沒讓我失望:https://stackoverflow.com/questions/22937618/reference-what-does-this-regex-mean/22944075#22944075
以下是perl正則的man文件:
- perl正則快速入門:man perlrequick
- perl正則教程:man perlretut
- perl正則完整文件:man perlre
學perl正則必備的一點基本語法
新建一個檔案作為perl指令碼檔案,在其首行寫上#!/usr/bin/perl,它表示用perl作為本檔案的直譯器。寫入一些perl程式後,再賦予執行許可權就可以執行了,或者直接使用perl命令去呼叫這個指令碼檔案,前面的兩個過程都可以省略,這和shell指令碼的方式是完全一樣的,無非是將bash替換為了perl,想必各位都理解。
1.print用來輸出資訊,相當於shell中的echo命令,但需要手動輸入換行符"\n"進行換行。
例如:
#!/usr/bin/perl
print "hello world\n"; # 注意每一句後面都使用分號結尾儲存後,執行它(假設指令碼檔名為test.pl):
$ chmod +x test.pl
$ perl test.pl2.變數賦值
perl中的變數可以不用事先宣告,可以直接賦值甚至直接引用。注意變數名前面總是需要加上$符號,無論是賦值的時候還是引用的時候,這和其它語言不太一樣。
#!/usr/bin/perl
$name="longshuai";
$age=18;
print "$name $age \n";3.if語句用來判斷,語法格式為:
if(condition){
body
}else{
body
}例如:
$age = 18;
if($age <= 20){
print "age less than 20\n";
} else {
print "age greate than 20\n";
}4.預設引數變數
在perl中,對於需要引數的函式或表示式,但卻沒有給引數,這是將會使用perl的預設引數變數$_。
例如,下面的print本來是需要引數的,但是因為沒有給引數,print將輸出預設的引數變數$_,也就是輸出"abcde"。
$_="abcde";
print ;perl中使用$_的地方非常多,後文還會出現,不過用到的時候我會解釋。
5.讀取標準輸入
perl中使用一對尖括號格式的<STDIN>來讀取來自非檔案的標準輸入,例如來自管道的資料,來自輸入重定向的資料或者來自鍵盤的輸入。需要注意的是,<STDIN>讀取的輸入會自帶換行符,所以print輸出的時候不要加上額外的換行符。
例如,在test.pl檔案中寫入如下內容:
#!/usr/bin/perl
$data=<STDIN>;
print "$data";然後用管道傳遞一行資料給perl程式:
echo "abcdefg" | perl test.pl只是需要注意,將<STDIN>賦值給變數時,將只能讀取一行(遇到換行符就結束讀取)。例如下面的perl將讀取不了"hijklmn"。
echo -e "abcdefg\nhijklmn" | perl test.pl如果想要讀取多行標準輸入,就不能將其賦值給變數,而是使用foreach來遍歷各行(此處不介紹其它方式):
foreach $line (<STDIN>){
print "$line";
}以上就是foreach的語法:
- 圓括號中的內容是待遍歷物件,通常是一個列表,比如上面用
<STDIN>讀取的多行資料就是一個列表,每一行都是列表中的一個元素; - $line稱為控制變數,foreach在每次迭代過程中都會選中一個列表中的元素賦值給$line,例如將讀取的每一行都賦值給$line。
可以省略$line,這時就採用預設的引數變數$_,所以以下兩個表示式是等價的:
foreach (<STDIN>){
print "$_";
}
foreach $_ (<STDIN>){
print "$_";
}6.讀取檔案中的資料
正則強大的用處就是處理文字資料,所以必須要說明perl如何讀取檔案資料來做正則匹配。
我們可以將檔案作為perl命令列的引數,perl會使用<>去讀取這些檔案中的內容。
foreach (<>){
print "$_";
}執行的時候,只要把檔案作為perl命令或指令碼檔案的引數即可:
perl test.pl /etc/passwd7.去掉行尾分隔符
由於<>和<STDIN>讀取檔案、讀取標準輸入的時候總是自帶換行符,很多時候這個自帶的換行符都會帶來格式問題。所以,有必要在每次讀取資料時將行尾的換行符去掉,使用chomp即可。
例如:
foreach $line (<STDIN>) {
chomp $line;
print "$line read\n";
}以下是執行結果:
[[email protected] ~]# echo -e "malongshuai gaoxiaofang" | perl 26.plx
malongshuai gaoxiaofang read如果上面的例子中不加上chomp,那麼執行結果將像下面一樣:
[[email protected] perlapp]# echo -e "malongshuai gaoxiaofang" | perl 26.plx
malongshuai gaoxiaofang
read顯然,輸出格式和print語句中期待的輸出格式不一樣。
前面說過,可以省略$line,讓其使用預設的引數變數$_,所以可以這樣讀取來自perl命令列引數檔案的資料:
foreach (<>) {
chomp;
print "$_ read\n";
}8.命令列的操作模式
其實就是一行式。perl命令列加上"-e"選項,就能在perl命令列中直接寫perl表示式,例如:
echo "malongshuai" | perl -e '$name=<STDIN>;print $name;'因為perl最為人所知的就是它應用了各種符號的組合,讓人看著怪異無比,而這些符號放在命令列中很可能會被shell先解析,所以強烈建議"-e"後表示式使用單引號包圍,而不是雙引號。
更建議,如果可以,不要使用perl命令列的方式,除錯起來容易混亂。
perl如何使用正則進行匹配
使用=~符號表示要用右邊的正則表示式對左邊的資料進行匹配。正則表示式的書寫方式為m//。關於m//,其中斜線可以替換為其它符號,規則如下:
- 雙斜線可以替換為任意其它對應符號,例如對稱的括號類,
m(),m{},相同的標點類,m!!,m%%等等 - 只有當m模式採用雙斜線的時候,可以省略m字母,即
//等價於m// - 如果正則表示式中出現了和分隔符相同的字元,可以轉義表示式中的符號,但更建議換分隔符,例如
/http:\/\//轉換成m%http://%
所以要匹配內容,有以下兩種方式:
- 方式一:使用
data =~ m/reg/,可以明確指定要對data對應的內容進行正則匹配 - 方式二:直接
/reg/,因為省略了引數,所以使用預設引數變數,它等價於$_ =~ m/reg/,也就是對$_儲存的內容進行正則匹配
perl中匹配操作返回的是匹配成功與否,成功則返回真,匹配不成功則返回假。當然,perl提供了特殊變數允許訪問匹配到的內容,甚至匹配內容之前的資料、匹配內容之後的資料都提供了相關變數以便訪問。見下面的示例。
例如:
1.匹配給定字串內容
$name = "hello gaoxiaofang";
if ($name =~ m/gao/){
print "matched\n";
}或者,直接將字串拿來匹配:
"hello gaoxiaofang" =~ m/gao/;2.匹配來自管道的每一行內容,匹配成功的行則輸出
foreach (<STDIN>){
chomp;
if (/gao/){
print "$_ was matched 'gao'\n";
}
}上面使用了預設的引數變數$_,它表示foreach迭代的每一行資料;上面還簡寫的正則匹配方式/gao/,它等價於$_ =~ m/gao/。
以下是執行結果:
[[email protected] perlapp]# echo -e "malongshuai gaoxiaofang" | perl 26.plx
malongshuai gaoxiaofang was matched 'gao'3.匹配檔案中每行資料
foreach (<>){
chomp;
if(/gao/){
print "$_ was matched 'gao'\n";
}
}4.如果想要輸出匹配到的內容,可以使用特殊變數$&來引用匹配到的內容,還可以使用$`引用匹配前面部分的內容,$'引用匹配後面部分的內容
例如:
aAbBcC =~ /bB/由於匹配的內容是bB,匹配內容之前的部分是aA,匹配之後的部分是cC,於是可以看作下面對應關係:
(aA)(bB)(cC)
| | |
$` $& $'以下是使用這三個特殊變數的示例:
$name="aAbBcC";
if(/bB/){
print "pre match: $` \n";
print "match: $& \n";
print "post match: $' \n";
}需要注意的是,正則中一般都提供全域性匹配的功能,perl中使用修飾符/g開啟。當開啟了全域性匹配功能,這3個變數儲存的值需要使用迴圈語句去遍歷,否則將只儲存第一次匹配的內容。例如:
$name="aAbBcCbB";
if(/bB/g){ # 匹配完第一個bB就結束
print "pre match: $` \n";
print "match: $& \n";
print "post match: $' \n";
}
while(/bB/g){ # 將迭代兩次
print "pre match: $` \n";
print "match: $& \n";
print "post match: $' \n";
}perl支援的正則
從這裡開始,正式介紹perl支援的正則。
出於方便,我全部都直接在perl程式內部定義待匹配的內容,如果想要匹配管道傳遞的輸入,或者匹配檔案資料,請看上文獲取操作方法。
為了完整性,每一節中我都是先把一大堆的內容列出來做個簡單介紹,然後再用示例解釋每個(或某幾個)。但perl正則的內容太多,而且很多功能前後關聯,所以如果列出來的內容沒有在同一小節內介紹,那麼就是在後面需要的地方介紹。當然,也有些沒什麼用或者用的很少的功能(比如unicode相關的),通篇都不會介紹。
模式匹配修飾符
指定模式匹配的修飾符,可以改變正則表示式的匹配行為。例如,下面的i就是一種修飾符,它讓前面的正則REG匹配時忽略大小寫。
m/REG/iperl總共支援以下幾種修飾符:msixpodualngc
i:匹配時忽略大小寫g:全域性匹配,預設情況下,正則表示式"abc"匹配"abcdabc"字串的時候,將之匹配左邊的abc,使用g將匹配兩個"abc"c:在開啟g的情況下,如果匹配失敗,將不重置搜尋位置m:多行匹配模式s:讓.可以匹配換行符"\n",也就是說該修飾符讓.真的可以匹配任意字元x:允許正則表示式使用空白符號,免得讓整個表示式難讀難懂,但這樣會讓原本的空白符號失去意義,這是可以使用\s來表示空白o:只編譯一次正則表示式n:非捕獲模式p:儲存匹配的字串到${^PREMATCH}、${^MATCH}、${^POSTMATCH}中,它們在結果上對應$`、$&和$',但效能上要更好a和u和l:分別表示用ASCII、Unicode和Locale的方式來解釋正則表示式,一般不用考慮這幾個修飾符d:使用unicode或原生字符集,就像5.12和之前那樣,也不用考慮這個修飾符
這些修飾符可以連用,連用時順序可隨意。例如下面兩行是等價的行為:全域性忽略大小寫的匹配行為。
m/REG/ig
m/REG/gi上面的修飾符,本節介紹igcmsxpo這幾個修飾符,n修飾符在後面分組捕獲的地方解釋,auld修飾符和字符集相關,不打算解釋。
i修飾符:忽略大小寫
該修飾符使得正則匹配的時候,忽略大小寫。
$name="aAbBcC";
if($name =~ m/ab/i){
print "pre match: $` \n"; # 輸出a
print "match: $& \n"; # 輸出Ab
print "post match: $' \n"; # 輸出BcC
}g和c修飾符以及\G
g修飾符(global)使得正則匹配的時候,對字串做全域性匹配,也就是說,即使前面匹配成功了,還會繼續向後匹配,看是否還能匹配成功。
例如,字串"abcabc",正則表示式"ab",在預設情況下(不是全域性匹配)該正則在匹配到第一個ab後就結束了,如果使用了g修飾符,匹配完第一個ab,還會繼續向後匹配,而且正好還能匹配到第二個ab,所以最終有兩個ab被匹配成功。
要驗證多次匹配,需要使用迴圈遍歷的方式,而不能用if語句:
$name="aAbBcCaBc";
while($name =~ m/ab/gi){
print "pre match: $` \n";
print "match: $& \n";
print "post match: $' \n";
}執行它,將輸出如下內容:
pre match: a
match: Ab
post match: BcCabd
pre match: aAbBcC
match: ab
post match: d以下內容,如果僅僅只是為了學perl正則,那麼可以跳過,因為很難,如果是學perl語言,那麼可以繼續看下去。
實際上,在開啟了g全域性匹配後,perl每次在成功匹配的時候都會記下匹配的字元位移,以便在下次匹配該內容時候,可以從指定位移處繼續向後匹配。每次匹配成功後的位移值(pos的位移從0開始算,0位移代表的是第一個字元左邊的位置),都可以通過pos()函式獲取。如果本次匹配導致位移指標重置,pos將返回undef。
$name="123ab456";
$name =~ m/\d\d/g; # 第一次匹配,匹配成功後記下位移
print "matched string: $&, position: ",pos $name,"\n";
$name =~ m/\d\d/g; # 第二次匹配,匹配成功後記下位移
print "matched string: $&, position: ",pos $name,"\n";執行它,將輸出如下內容:
matched string: 12, position: 2
matched string: 45, position: 7由於匹配失敗的時候,正則匹配操作會返回假,所以可以作為if或while等的條件語句。例如,改為while迴圈多次匹配:
$name="123ab456";
while($name =~ m/\d\d/g){
print "matched string: $&, position: ",pos $name,"\n";
}預設全域性匹配情況下,當本次匹配失敗,位移指標將重置到起始位置0處,也就是說,下次匹配將從頭開始匹配。例如:
$txt="1234a56";
$txt =~ /\d\d/g; # 匹配成功:12,位移向後移兩位
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d\d/g; # 匹配成功:34,位移向後移兩位
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d\d\d/g; # 匹配失敗,位移指標回到0處,pos()返回undef
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d/g; # 匹配成功:1,位移向後移1位
print "matched $&: ",pos $txt,"\n";執行上述程式,將輸出:
matched 12: 2
matched 34: 4
matched 34:
matched 1: 1如果"g"修飾符下同時使用"c"修飾符,也就是"gc",它表示全域性匹配失敗的時候不重置位移指標。也就是說,本次匹配失敗後,位移指標會向後移一位,下次匹配將從後移的這個位置處開始匹配。當位移移到了結尾,將無法再移動,此時位移指標將一直指向最後一個位置。
$txt="1234a56";
$txt =~ /\d\d/g;
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d\d/g;
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d\d\d/gc; # 匹配失敗,位移向後移1位,$&和pos()保留上一次匹配成功的內容
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d/g; # 匹配成功:5,位移向後移1位
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d/g; # 匹配成功:6,位移向後移1位
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d/gc; # 匹配失敗:位移無法再後移,將一直指向最後一個位置
print "matched $&: ",pos $txt,"\n";執行上述程式,將輸出:
matched 12: 2
matched 34: 4
matched 34: 4
matched 5: 6
matched 6: 7
matched 6: 7繼續上面的問題,如果第三個匹配語句不是\d\d\d,而是"\d",它匹配字母a的時候也失敗,不用c修飾符的時候會重置位移嗎?顯然是不會。因為它會繼續向後匹配。所以該\G登場了。
預設全域性匹配情況下,匹配時是可以跳過匹配失敗的字元繼續匹配的:當某個字元匹配失敗,它會後移一位繼續去匹配,直到匹配成功或匹配結束。
$txt="1234ab56";
$txt =~ /\d\d/g;
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d\d/g;
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d/g; # 字母a匹配失敗,後移一位,字母b匹配失敗,後移一位,數值5匹配成功
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d/g; # 數值6匹配成功
print "matched $&: ",pos $txt,"\n";執行上述程式,將輸出:
matched 12: 2
matched 34: 4
matched 5: 7
matched 6: 8可以指定\G,使得本次匹配強制從位移處進行匹配,不允許跳過任何匹配失敗的字元。
- 如果本次
\G全域性匹配成功,位移指標自然會後移 - 如果本次
\G全域性匹配失敗,且沒有加上c修飾符,那麼位移指標將重置 - 如果本次
\G全域性匹配失敗,且加上了c修飾符,那麼位移指標將卡在那不動
例如:
$txt="1234ab56";
$txt =~ /\d\d/g;
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d\d/g;
print "matched $&: ",pos $txt,"\n";
$txt =~ /\G\d/g; # 強制從位移4開始匹配,無法匹配字母a,但又不允許跳過
# 所以本次\G全域性匹配失敗,由於沒有修飾符c,指標重置
print "matched $&: ",pos $txt,"\n";
$txt =~ /\G\d/g; # 指標回到0,強制從0處開始匹配,數值1能匹配成功
print "matched $&: ",pos $txt,"\n";以下是輸出內容:
matched 12: 2
matched 34: 4
matched 34:
matched 1: 1如果將上面第三個匹配語句加上修飾符c,甚至後面的語句也都加上\G和c修飾符,那麼位移指標將卡在那個位置:
$txt="1234ab56";
$txt =~ /\d\d/g;
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d\d/g;
print "matched $&: ",pos $txt,"\n";
$txt =~ /\G\d/gc; # 匹配失敗,指標卡在原地
print "matched $&: ",pos $txt,"\n";
$txt =~ /\G\d/gc; # 匹配失敗,指標繼續卡在原地
print "matched $&: ",pos $txt,"\n";
$txt =~ /\G\d/gc; # 匹配失敗,指標繼續卡在原地
print "matched $&: ",pos $txt,"\n";以下是輸出結果:
matched 12: 2
matched 34: 4
matched 34: 4
matched 34: 4
matched 34: 4一般來說,全域性匹配都會用迴圈去多次迭代,和上面一次一次列出匹配表示式不一樣。所以,下面使用while迴圈的例子來對\G和c修飾符稍作解釋,其實理解了上面的內容,在迴圈中使用\G和c修飾符也一樣很容易理解。
$txt="1234ab56";
while($txt =~ m/\G\d\d/gc){
print "matched: $&, ",pos $txt,"\n";
}執行結果:
matched: 12, 2
matched: 34, 4當第三輪迴圈匹配到a字母的時候,由於使用了\G,導致匹配失敗,結束迴圈。
上面使用c與否是無關緊要的,但如果這個while迴圈的後面後還有對$txt的匹配,那麼使用c修飾符與否就有關係了。例如下面兩段程式,返回結果不一樣:
$txt="1234ab56";
while($txt =~ m/\G\d\d/gc){ # 使用c修飾符
print "matched: $&, ",pos $txt,"\n";
}
$txt =~ m/\G\d\d/gc;
print "matched: $&, ",pos $txt,"\n";和
$txt="1234ab56";
while($txt =~ m/\G\d\d/g){ # 不使用c修飾符
print "matched: $&, ",pos $txt,"\n";
}
$txt =~ m/\G\d\d/gc;
print "matched: $&, ",pos $txt,"\n";m修飾符:多行匹配模式
正則表示式一般都只用來匹配單行資料,但有時候卻需要一次性匹配多行。比如匹配跨行單詞、匹配跨行片語,匹配跨行的對稱分隔符(如一對括號)。
使用m修飾符可以開啟多行匹配模式。
例如:
$txt="ab\ncd";
$txt =~ /a.*\nc/m;
print "===match start===\n$&\n===match end===\n";執行,將輸出:
===match start===
ab
c
===match end===關於多行匹配,需要注意的是元字元.預設情況下無法匹配換行符。可以使用[\d\D]代替點,也可以開啟s修飾符使得.能匹配換行符。
例如,下面兩個匹配輸出的結果和上面是一致的。
$txt="ab\ncd";
$txt =~ /a.*c/ms;
print "===match start===\n$&\n===match end===\n";
$txt="ab\ncd";
$txt =~ /a[\d\D]*c/m;
print "===match start===\n$&\n===match end===\n";s修飾符
預設情況下,.元字元是不能匹配換行符\n的,開啟了s修飾符功能後,可以讓.匹配換行符。正如剛才的那個例子:
$txt="ab\ncd";
$txt =~ /a.*c/m; # 匹配失敗
print "===match start===\n$&\n===match end===\n";
$txt="ab\ncd";
$txt =~ /a.*c/ms; # 匹配成功
print "===match start===\n$&\n===match end===\n";x修飾符
正則表示式最為人所抱怨的就是它的可讀性極差,無論你的正則能力有多強,看著一大堆亂七八糟的符號組合在一起,都得一個符號一個符號地從左向右讀。
萬幸,perl正則支援表示式的分隔,甚至支援註釋,只需加上x修飾符即可。這時候正則表示式中出現的所有空白符號都不會當作正則的匹配物件,而是直接被忽略。如果想要匹配空白符號,可以使用\s表示,或者將空格使用\Q...\E包圍。
例如,以下4個匹配操作是完全等價的。
$ans="cat sheep tiger";
$ans =~ /(\w) *(\w) *(\w)/; # 正常情況下的匹配表示式
$ans =~ /(\w)\s* (\w)\s* (\w)/x;
$ans = ~ /
(\w)\s* # 可以加上本行註釋:匹配第一個單詞
(\w)\s* # 可以加上本行註釋:匹配第二個單詞
(\w) # 可以加上本行註釋:匹配第三個單詞
/x;
$ans =~ /
(\w)\Q \E # \Q \E強制將中間的空格當作字面符號被匹配
(\w)\Q \E
(\w)
/x;對於稍微複雜一些的正則表示式,常常都會使用x修飾符來增強其可讀性,最重要的是加上註釋。這一點真的非常人性化。
p修飾符
前面說過,通過3個特殊變數$`、$&和$'可以儲存匹配內容之前的內容,匹配內容以及匹配內容之後的內容。但是,只要使用了這3個變數中的任何一個,後面的所有分組效率都會降低。perl提供了一個p修飾符,能實現完全相同的功能:
${^PREMATCH} <=> $`
${^MATCH} <=> $&
${^POSTMATCH} <=> $'一個例子即可描述:
$ans="cat sheep tiger";
$ans =~ /sheep/p;
print "${^PREMATCH}\n"; # 輸出"cat "
print "${^MATCH}\n"; # 輸出"sheep"
print "${^POSTMATCH}\n"; # 輸出" tiger"o修飾符
在較老的perl版本中,如果使用同一個正則表示式做多次匹配,正則引擎將只多次編譯正則表示式。很多時候正則表示式並不會改變,比如迴圈匹配檔案中的行,這樣的多次編譯導致效能下降很明顯,於是可以使用o修飾符讓正則引擎對同一個正則表示式不重複編譯。
在perl5.6中,預設情況下對同一正則表示式只編譯一次,但同樣可以指定o修飾符,使得即使正則表示式變化了也不要重新編譯。
一般情況下,可以無視這個修飾符。
範圍模式匹配修飾符(?imsx-imsx:pattern)
前文介紹的修飾符adluoimsxpngc都是放在m//{FLAG}的flag處的,放在這個位置會對整個正則表示式產生影響,所以它的作用範圍有點廣。
例如m/pattern1 pattern2/i的i修飾符會影響pattern1和pattern2。
perl允許我們定義只在一定範圍內生效的修飾符,方式是(?imsx:pattern)或(?-imsx:pattern)或(?imsx-imsx:pattern),其中加上-表示去除這個修飾符的影響。這裡只列出了imsx,因為這幾個最常用,其他的修飾符也一樣有效。
例如,對於待匹配字串"Hello world gaoxiaofang",使用以下幾種模式去匹配的話:
/(?i:hello) world/
表示匹配hello時,可忽略大小寫,但匹配world時仍然區分大小寫。所以匹配成功
/(?ims:hello.)world/
表示可以跨行匹配helloworld,也可以匹配單行的hellosworld,且hello部分忽略大小寫。所以匹配成功
/(?i:hello (?-i:world) gaoxiaoFANG)/
表示在第二個括號之前,可用忽略大小寫進行匹配,但因為第二個括號裡指明瞭去除i的影響,所以對world的匹配會區分大小寫,但是對gaoxiaofang部分的匹配又不區分大小寫。所以匹配成功
/(?i:hello (?-i:world) gaoxiao)FANG/
和前面的類似,但是將"FANG"放到了括號外,意味著這部分要區分大小寫。所以匹配失敗
perl支援的反斜線序列
1.錨定類的反斜線序列
所謂錨定,是指它匹配的是位置,而非字元,比如錨定行首的意思是匹配第一個字母前的空字元。也就是很多人說的"零寬斷言(zero-width assertions)"。
\b:匹配單詞邊界處的空字元\B:匹配非單詞邊界處的空字元\<:匹配單詞開頭處的空字元\>:匹配單詞結尾處的空字\A:匹配絕對行首,換句話說,就是輸入內容的開頭\z:匹配絕對行尾,換句話說,就是輸入內容的絕對尾部\Z:匹配絕對行尾或絕對行尾換行符前的位置,換句話說,就是輸入內容的尾部\G:強制從位移指標處進行匹配,詳細內容見g和c修飾符以及\G
主要解釋下\A \z \Z,其它的屬於基礎正則的內容,不多做解釋了。
\A \z \Z和^ $的區別主要體現在多行模式下。在多行模式下:
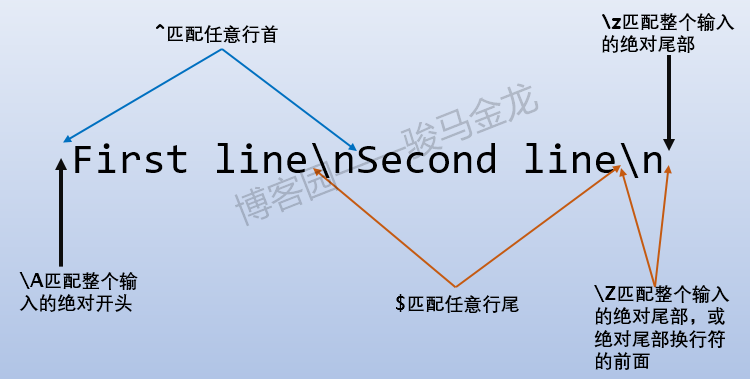
$txt = "abcd\nABCD\n";
$txt1 = "abcd\nABCD";
$txt =~ /^ABC*/; # 無法匹配
$txt =~ /^ABC*/m; # 匹配
$txt =~ /\Aabc/; # 匹配
$txt =~ /\Aabc/m; # 匹配
$txt =~ /\AABC/m; # 無法匹配
$txt =~ /cd\n$/m; # 不匹配
$txt =~ /cd$\n/m; # 不匹配
$txt =~ /cd$/m; # 匹配
$txt =~ /CD\Z\n/m # 匹配
$txt =~ /CD\Z\n\Z/m; # 匹配
$txt =~ /CD\n\z/m; # 匹配
$txt1 =~ /CD\Z/m; # 匹配
$txt1 =~ /CD\z/m; # 匹配從上面的$匹配示例可知,$代表的行尾,其實它在有換行符的時候匹配"\n",而不是"\n"的前、後,在沒有換行符的時候,匹配行尾。
2.字元匹配反斜線序列
當然,除了以下這幾種,還有\v \V \h \H \R \p \c \X,這些基本不會用上,所以都不會在本文解釋。
\w:匹配單詞構成部分,等價於[_[:alnum:]]\W:匹配非單詞構成部分,等價於[^_[:alnum:]]\s:匹配空白字元,等價於[[:space:]]\S:匹配非空白字元,等價於[^[:space:]]\d:匹配數字,等價於[0-9]\D:匹配非數字,等價於[^0-9]\N:不匹配換行符,等價於[^\n]。但\N{NAME}有特殊意義,表示匹配已命名(名為NAME)的unicode字元序列,本文不介紹該特殊用法
由於元字元.預設無法匹配換行符,所以需要匹配換行符的時候,可以使用特殊組合[\d\D]或者(\n|\N)來替換.,換句話說,如果想匹配任意長度的任意字元,可以換成[\d\D]*或者(\n|\N)*,當然,前提是必須支援這3個反斜線序列。
之所以不用[\n\N]替代元字元.,是因為\N有特殊意義,不能隨意接符號和字母。
3.分組引用的反斜線序列
\1:反向引用,其中1可以替換為任意一個正整數,即使超出9,例如\111表示匹配第111個分組\g1或\g{1}:也是反向引用,只不過這種寫法可以避免歧義,例如\g{1}11表示匹配第一個分組內容後兩個數字1\g{-1}:還可以使用負數,表示距離\g左邊的分組號,也就是相對距離。例如(abc)([a-z])\g{-1}中的\g引用的是[a-z],如果-1換成-2,則引用的abc\g{name}:引用已命名的分組(命名捕獲),其中name為分組的名稱\k<name>:同上,引用已命名的分組(命名捕獲),其中name為分組的名稱\K:不要將\K左邊的內容放進$&。換句話說,\K左邊的內容即使匹配成功了,也會重置匹配的位置
\1表示引用第一個分組,\11表示引用第11個分組,在基礎正則中,是不支援引用超出9個分組的,但顯然perl會將\11的第二個1解析為引用,以便能引用更多分組。
同理\g1和\g11,只是使用\g引用的方式可以加上大括號使引用變得更安全,更易讀,且\g可以使用負數來表示從右向左相對引用。這樣在\g{-2}的左邊新增新的分組括號時,無須修改引用表示式。
此處暫時還沒介紹到命名分組,所以\g{name}和\k<name>留在後面再介紹。
\K表示強制中斷前面已完成的匹配。例如"abc22ABC" =~ /abc\K2.*/;,雖然abc三個字母也被匹配,如果沒有\K,這3個字母將放進$&中,但是\K使得匹配完abc後立即切斷前面的匹配,也就是從c字母后面開始重新匹配,所以這裡匹配的結果是22ABC。
再例如,"abc123abcfoo"=~ /(abc)123\K\g1foo/;,它匹配到123後被切斷,但是分組引用還可以繼續引用,所以匹配的結果是"abcfoo"。
貪婪匹配、非貪婪匹配、佔有優先匹配
在基礎正則中,那些能匹配多次的量詞都會匹配最長內容。這種儘量多匹配的行為稱為"貪婪匹配"(greedy match)。
例如字串"aa1122ccbb",用正則表示式a.*c去匹配這個字串,其中的.*將直接從第二個字母a開始匹配到最結尾的b,因為從第二個字母a開始到最後一個字母b都符合.*的匹配模式。再然後,去匹配字母c,但因為已經把所有字母匹配完了,只能回退一個字母一個字母地釋放,每釋放一個就匹配一次字母c,發現回退釋放到倒數第三個字母就能滿足匹配要求,於是這裡的.*最終匹配的內容是"a1122c"。
上面涉及到回溯的概念,也就是將那些已經被量詞匹配的內容回退釋放。
上面描述的是貪婪匹配行為,還有非貪婪匹配、佔有優先匹配,以下簡單描述下他們的意義:
- 非貪婪匹配:(lazy match,reluctant)儘可能少地匹配,也叫做懶惰匹配
- 佔有優先匹配:(possessive)佔有優先和固化分組是相同的,只要佔有了就不再交換,不允許進行回溯。相關內容見後文"固化分組"
有必要搞清楚這幾種匹配模式在匹配機制上的區別:
- 貪婪匹配:對於那些量詞,將一次性從左到右匹配到最大長度,然後再往回回溯釋放
- 非貪婪匹配:對於那些量詞,將從左向右逐字元匹配最短長度,然後直接結束這次的量詞匹配行為
- 佔有優先匹配:按照貪婪模式匹配,匹配後內容就鎖住,不進行回溯(後文固化分組有具體示例)
除了上面描述的*量詞會進行貪婪匹配,其他所有能進行多次匹配的量詞可以選擇貪婪匹配模式、非貪婪匹配模式和佔有優先匹配模式,只需選擇對應的量詞元字元即可。如下:
(量詞後加上?) (量詞後加上+)
貪婪匹配量詞 非貪婪匹配量詞 佔有優先匹配量詞
-----------------------------------------------------------------
* *? *+
? ?? ?+
+ +? ++
{M,} {M,}? {M,}+
{M,N} {M,N}? {M,N}+
{N} {N}? {N}+幾點需要說明:
- 非貪婪匹配時的
{M,}?和{M,N}?,它們是等價的,因為最多隻匹配M次 - 在perl中不支援
{,N}的模式,所以也沒有對應的非貪婪和佔有優先匹配模式 - 關於
{N}這個量詞,由於是精確匹配N次,所以貪婪與否對最終結果無關緊要,但是卻影響匹配時的行為:貪婪匹配最長,需要回溯,非貪婪匹配最短,不回溯,佔有優先匹配最長不回溯。
看以下示例即可理解貪婪和非貪婪匹配的行為:
$str="abc123abc1234";
# greedy match
if( $str =~ /(a\w*3)/){
print "$&\n"; # abc123abc123
}
# lazy match
if( $str =~ /(a\w*?3)/){
print "$&\n"; # abc123
}以下是佔有優先匹配模式的示例:
$str="abc123abc1234";
if( $str =~ /a\w*+/){ # 成功
print "possessive1: $&\n";
}
if( $str =~ /a\w*+3/){ # 失敗
print "possesive2: $&\n";
}所以,在使用佔有優先匹配模式時,它後面不應該跟其他表示式,例如a*+x永遠匹配不了東西。絕大多數時候都是不會回溯的。但是少數情況下,它並非強制鎖住回溯,這個和正則引擎匹配原理有本文不多做解釋。
另外,固化分組和佔有優先並不完全等價,它們只是匹配行為相同:匹配後不回溯。具體可對比後文對應內容。
perl的分組捕獲和分組引用
分組的基本應用
在基礎正則中,使用括號可以對匹配的內容進行分組,這種行為稱為分組捕獲。捕獲後可以通過\1這種反向引用方式去引用(訪問)儲存在分組中的匹配結果。
例如:
"abc11ddabc11" =~ /([a-z]*)([0-9]*)dd\1\2/;在perl中,還可以使用\gN的方式來反向引用分組,這個在上一節"反斜線序列"中已經解釋過了。例如,以下是和上面等價的幾種寫法:
"abc11ddabc11" =~ /([a-z]*)([0-9]*)dd\g1\g2/;
"abc11ddabc11" =~ /([a-z]*)([0-9]*)dd\g{1}\g{2}/;
"abc11ddabc11" =~ /([a-z]*)([0-9]*)dd\g{-2}\g{-1}/;perl還會把分組的內容放進perl自帶的特殊變數$1,$2,...,$N中,它們和\1,\2,...\N在匹配成功時的結果上沒有區別,但是\N這種型別的反向引用只在正則匹配中有效,正則匹配結束後就消亡了,而$N因為是perl的變數,即使正則已經退出匹配,也依然可以引用。所以,我們可以使用$N的方式來輸出分組匹配的結果:
"abc11ddabc11" =~ /([a-z]*)([0-9]*)dd\1\2/;
print "first group \\1: $1\n";
print "second group \\2: $2\n";有兩點需要注意:
- 這些分組可能捕獲到的是空值(比如那些允許匹配0次的量詞),但是整個匹配是成功的。這時候引用分組時,得到的結果也將是空值
- 當分組匹配失敗的時候,
\1會在識別括號的時候重置,而$1仍儲存上一次分組成功的值
第一點,示例可知:
"abcde" =~ /([0-9]*)de/;
print "null group: $1\n";第二點,從機制上去分析。\1是每個正則匹配都相互獨立的,而$1則儲存分組捕獲成功的值,即使這次值是上次捕獲的。
這裡稍微解釋下正則匹配關於分組捕獲的匹配過程:
例如,匹配表示式"12abc22abc" =~ /\d(abc)\d\d\1/;,當正則引擎去匹配資料時:
1.首先匹配第一個數字1,發現符合\d,於是繼續用(abc)去匹配字串,因為發現了是分組括號,於是會將第二個字元2放進分組,發現不匹配字母a,於是匹配失敗,丟棄這個分組中的內容。
2.正則引擎繼續向後匹配數值2,發現符合\d,於是用(abc)去匹配字串,接著會將第三個字元a放進分組,發現能匹配,繼續匹配字串中的b、c發現都能匹配,於是分組捕獲完成,將其賦值給$1,之後就能用\1和$1去引用這個分組的內容。
3.後面繼續去匹配\d\d\1,直到匹配結束。
當然,具體匹配的過程不會真的這麼簡單,它會有一些優化匹配方式,以上只是用邏輯去描述匹配的過程。
perl中更強大的分組捕獲
在perl中,支援的分組捕獲更強大、更完整,它除了支援普通分組(也就是直接用括號的分組),還支援:
- 命名捕獲
(?<NAME>...):捕獲後放進一個已分配好名稱(即NAME)的分組中,以後可以使用這個名稱來引用這個分組,如\g{NAME}引用 - 匿名捕獲
(?:...):僅分組,不捕獲,所以後面無法再引用這個捕獲 - 固化分組
(?>...):一匹配成功就永不交回內容(用回溯的想法理解很容易)
匿名捕獲
匿名捕獲是指僅分組,不捕獲。因為不捕獲,所以無法使用反向引用,也不會將分組結果賦值給$1這種特殊變數。
雖然有了分組捕獲功能,就可以實現任何需求,但有時候可以讓這種行為變得更人性化,減少維護力度。
例如字串"xiaofang or longshuai",使用模式/(\w+) or (\w+)/去捕獲,用$1和$2分別引用or左右兩個單詞:
$str = "xiaofang or longshuai";
if ($str =~ /(\w+) or (\w+)/){
print "name1: $1, name2: $2\n";
}但如果需求是中間的關係or也可以換成and,為了同時滿足and和or兩種需求,使用模式/(\w+) (and|or) (\w+)/去匹配,但是這時引用的序號就得由$2變為$3:
$str = "xiaofang or longshuai";
if ($str =~ /(\w+) (or|and) (\w+)/){
print "name1: $1, name2: $3\n";
}如果使用匿名捕獲,對and和or這樣無關緊要,卻有可能改變匹配行為的內容,可以將其放進一個無關的分組中。這樣不會對原有的其餘正則表示式產生任何影響:
$str = "xiaofang or longshuai";
if ($str =~ /(\w+) (?:or|and) (\w+)/){
print "name1: $1, name2: $2\n";
}注意上面仍然使用$2引用第三個括號。
同樣,如果要在正則內部使用反向引用,也一樣使用\2來引用第三個括號。
另外,在前文還介紹過一個n修飾符,它也表示非捕獲僅分組行為。但它只對普通分組有效,對命名分組無效。且因為它是修飾符,它會使所有的普通分組都變成非捕獲模式。
$str = "xiaofang or longshuai";
if ($str =~ /(\w+) (or|and) (\w+)/n){
print "name1: $1, name2: $2\n";
}由於上面開啟了n修飾符,使得3個普通分組括號都變成非捕獲僅分組行為,所以\1和$1都無法使用。除非正則中使用了命名分組。
命名捕獲
命名捕獲是指將捕獲到的內容放進分組,這個分組是有名稱的分組,所以後面可以使用分組名去引用已捕獲進這個分組的內容。除此之外,和普通分組並無區別。
當要進行命名捕獲時,使用(?<NAME>)的方式替代以前的分組括號()即可。例如,要匹配abc並將其分組,以前普通分組的方式是(abc),如果將其放進命名為name1的分組中:(?<name1>abc)。
當使用命名捕獲的時候,要在正則內部引用這個命名捕獲,除了可以使用序號類的絕對引用(如\1或\g1或\g{1}),還可以使用以下任意一種按名稱引用方式:
\g{NAME}\k{NAME}\k<NAME>\k'NAME'
如果要在正則外部引用這個命名捕獲,除了可以使用序號類的絕對應用(如$1),還可以使用$+{NAME}的方式。
實際上,後一種引用方式的本質是perl將命名捕獲的內容放進了一個名為%+的特殊hash型別中,所以可以使用$+{NAME}的方式引用,如果你不知道這一點,那就無視與此相關的內容即可,不過都很簡單,一看就懂。
例如:
$str = "ma xiaofang or ma longshuai";
if ($str =~ /
(?<firstname>\w+)\s # firstname -> ma
(?<name1>\w+)\s # name1 -> xiaofang
(?:or|and)\s # group only, no capture
\g1\s # \g1 -> ma
(?<name2>\w+) # name2 -> longshuai
/x){
print "$1\n";
print "$2\n";
print "$3\n";
# 或者指定名稱來引用
print "$+{firstname}\n$+{name1}\n$+{name2}\n";
}其中上述程式碼中的\g1還可以替換為\1、\g{firstname}、\k{firstname}或\k<firstname>。
通過使用命名捕獲,可以無視序號,直接使用名稱即可準確引用。
固化分組
首先固化分組不是一種分組,所以無法去引用它。它和"佔有優先"匹配模式(貪婪匹配、惰性匹配、佔有優先匹配三種匹配模式,見後文)是等價的除了這兩種稱呼,在不同的書、不同的語言裡還有一種稱呼:原子匹配。
它的表示形式類似於分組(?>),所以有些地方將其稱呼為"固化分組"。再次說明,固化分組不是分組,無法進行引用。如果非要將其看作是分組,可以將其理解為被限定的匿名分組:不捕獲,只分組。
- 按照"佔有優先"的字面意義來理解比較容易:只要匹配成功了,就絕不回溯。
- 如果按照固化分組的概念來理解,就是將匹配成功的內容放進分組後,將其固定,不允許進行回溯。但是需要注意,這裡的不回溯是放進分組中的內容不會回溯給分組外面,而分組內部的內容是可以回溯的。
如果不知道什麼是回溯,看完下面的例子就明白。
例如"hello world"可以被hel.* world成功匹配,但不能被hel(?>.*) world匹配。因為正常情況下,.*匹配到所有內容,然後往回釋放已匹配的內容直到釋放完空格為止,這種往回釋放字元的行為在正則術語中稱為"回溯"。而固化分組後,.*已匹配後面所有內容,這些內容一經匹配絕不交回,即無法回溯。
但是,如果正則表示式是hel(?>.* world),即將原來分組外面的內容放進了分組內部,這時在分組內部是會回溯的,也就是說能匹配"hello world"。
$str="ma longshuai gao xiaofang";
if($str =~ /ma (?>long.*)/){ # 成功
print "matched\n";
}
if($str =~ /ma (?>long.*)gao/){ # 失敗
print "matched\n";
}
if($str =~ /ma (?>long.*gao)/){ # 成功
print "matched\n";
}
if($str =~ /ma (?>long.*g)ao/){ # 成功
print "matched\n";
}固化分組看上去挺簡單的,此處也僅介紹了它最簡單的形式。但實際上固化分組很複雜,它涉及了非常複雜的正則引擎匹配原理和回溯機制。如果有興趣,可以閱讀《精通正則表示式》一書的第四章。
環視錨定(斷言)
"環視"錨定,即lookaround anchor,也稱為"零寬斷言",它表示匹配的是位置,不是字元。
(?=...):表示從左向右的順序環視。例如(?=\d)表示當前字元的右邊是一個數字時就滿足條件(?!...):表示順序環視的取反。如(?!\d)表示當前字元的右邊不是一個數字時就滿足條件(?<=...):表示從右向左的逆序環視。例如(?<=\d)表示當前字元的左邊是一個數字時就滿足條件(?<!)...:表示逆序環視的取反。如(?<!\d)表示當前字元的左邊不是一個數字時就滿足條件
關於"環視"錨定,最需要注意的一點是匹配的結果不佔用任何字元,它僅僅只是錨定位置。
例如"your name is longshuai MA"和"your name is longfei MA"。使用(?=longshuai)將能錨定第一個句子中單詞"longshuai"前面的空字元,但它的匹配結果是"longshuai"前的空白字元,所以(?=longshuai)long才能代表"long"這幾個字串,所以僅對於此處的兩個句子,long(?=shuai)和(?=longshuai)long是等價的。
一般為了方便理解,在順序環視的時候會將匹配內容放在錨定括號的左邊(如long(?=longshuai)),在逆序環視的時候會將匹配的內容放在錨定括號的右邊(如(?<=long)shuai)。
另外,無論是哪種錨定,都是從左向右匹配再做回溯的(假設允許回溯),即使是逆序環視。
例如:
$str="abc123abcc12c34";
# 順序環視
$str =~ /a.*c(?=\d)/; # abc123abcc12c
print "$&\n";
# 順序否定環視
$str =~ /a.*c(?!\d)/; # abc123abc
print "$&\n";
# 逆序環視,這裡能逆序匹配成功,靠的是錨定括號後面的c
$str =~ /a.*(?<=\d)c/; # abc123abcc12c
print "$&\n";
# 逆序否定環視
$str =~ /a.*(?<!\d)c/; # abc123abcc
print "$&\n";逆序環視的表示式必須只能表示固定長度的字串。例如(?<=word)或(?<=word|word)可以,但(?<=word?)不可以,因為?匹配0或1長度,長度不定,它無法對左邊是word還是wordx做正確判斷。
$str="hello worlds Gaoxiaofang";
$str =~ /he.*(?<=worlds?) Gao/; # 報錯
$str =~ /he.*(?<=worlds|world) Gao/; # 報錯在PCRE中,這種變長的逆序環視錨定可重寫為(?<=word|words),但perl中不允許,因為perl嚴格要求長度必須固定。
\Q...\E
perl中的\Q...\E用來強制包圍一段字元,使得裡面的正則符號都當做普通字元,不會有特殊意義,它是一種非常強的引用。但注意,它無法強制變數的替換。
例如:
$sub="world";
$str="hello worlds gaoxiaofang";
$str =~ /\Q$sub\E/; # $sub會替換,所以匹配成功world
$str =~ /\Q$sub.\E/; # 元字元"."被當做普通的字元,所以無法匹配qr//建立正則物件
因為可以在正則模式中使用變數替換,所以我們可以將正則中的一部分表示式事先儲存在變數中。例如:
$str="hello worlds gaoxiaofang";
$pattern="w.*d";
$str =~ /$pattern/;
print "$&\n";但是,這樣缺陷很大,在儲存正則表示式的變數中存放的特殊字元要防止有特殊意義。例如,當使用m//的方式做匹配分隔符時,不能在變數中儲存/,除非轉義。
perl提供了qr/pattern/的功能,它把pattern部分構建成一個正則表示式物件,然後就可以在正則表示式中直接引用這個物件,更方便的是可用將這個物件儲存到變數中,通過引用變數的方式來引用這個以儲存好的正則物件。
$str="hello worlds gaoxiaofang";
# 直接作為正則表示式
$str =~ qr/w.*d/;
print "$&\n";
# 儲存為變數,再作為正則表示式
$pattern=qr/w.*d/;
$str =~ /$pattern/;
print "$&\n";
# 儲存為變數,作為正則表示式的一部分
$pattern=qr/w.*d/;
$str =~ /hel.* $pattern/;
print "$&\n";還允許為這個正則物件設定修飾符,比如忽略大小寫的匹配修飾符為i,這樣在真正匹配的時候,就只有這一部分正則物件會忽略大小寫,其餘部分仍然區分大小寫。
$str="HELLO wORLDs gaoxiaofang";
$pattern=qr/w.*d/i; # 忽略大小寫
$str =~ /HEL.* $pattern/; # 匹配成功,$pattern部分忽略大小寫
$str =~ /hel.* $pattern/; # 匹配失敗
$str =~ /hel.* $pattern/i; # 匹配成功,所有都忽略大小寫