
Java集合 | LinkedList 原始碼分析(JDK 1.8)
阿新 • • 發佈:2018-12-09
一、基本圖示
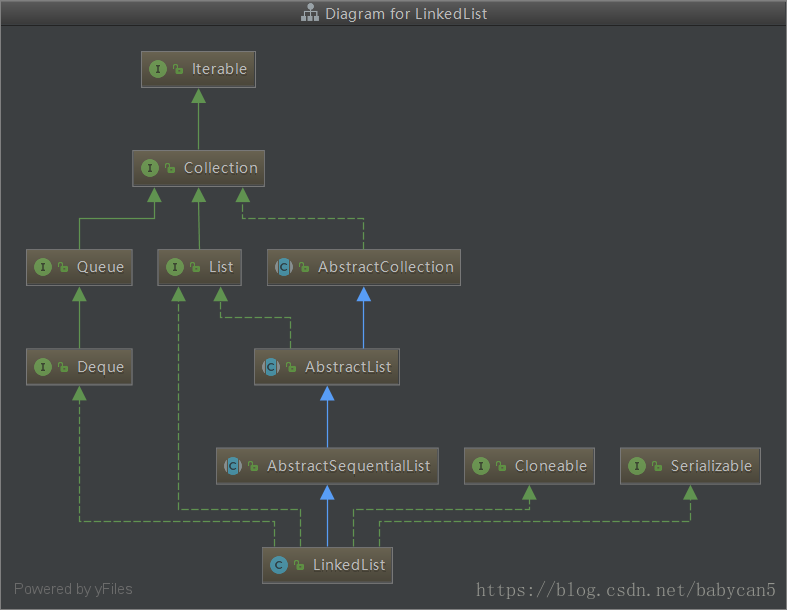
二、基本介紹
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable結構
- LinkedList 繼承 AbstractSequentialList 抽象類,該類是隻支援按次序訪問
- LinkedList 實現了 List 介面
- LinkedList 實現了 Deque 介面,即能被當作雙端佇列
- 實現了 Cloneable 介面,覆蓋了 clone 方法,即可以被克隆
- 實現了 Serializable 介面,支援序列化
特性
- 底層使用連結串列,還是雙向連結串列
- 元素是有序的,輸入順序和輸出順序一致
- 是執行緒不安全的
- 可以新增元素 null,可以新增相同的元素
三、雙向連結串列的基本結構
因為底層是雙向連結串列,因此所有成員變數都和連結串列的屬性有關
// 連結串列的長度
transient int size = 0;
// 頭節點
transient Node<E> first;
// 尾節點
transient Node<E> last;這是一個雙向連結串列改有的基本結構,包括指向前面的節點、資料、指向後面的節點
private static class Node<E> {
E item;
Node<E> next; //指向下一個節點
Node<E> prev; //指向上一個節點
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}四、內部呼叫的方法
因為在呼叫增加、刪除、修改方法的時候,都是直接呼叫這幾個方法,因此就直接來看這幾個方法。包括
void linkFirst(E e):把數值插入到連結串列頭部void linkLast(E e):把數值插入到連結串列尾部void linkBefore(E e, Node<E> succ):在指定節點前面插入值(節點不為空)E unlinkFirst(Node<E> f):刪除不為空的頭節點,返回刪除的值E unlinkLast(Node<E> l):刪除不為空的尾節點,返回刪除的值E unlink(Node<E> x):刪除不為空的指定節點Node<E> node(int index):返回指定位置的節點
// 把資料插入到連結串列頭部
private void linkFirst(E e) {
// 獲取當前連結串列的頭節點
final Node<E> f = first;
// 建立一個節點,向前指向 null,向後指向當前連結串列的頭節點 f
final Node<E> newNode = new Node<>(null, e, f);
// f 指向新的節點
first = newNode;
// 如果 f 為空(新增之前什麼也沒有),則連結串列的尾節點也指向新建節點
// 此時連結串列的頭節點和尾節點都指向這個新建立的節點
if (f == null)
last = newNode;
// 如果 f 不為空(新增之前頭節點已經有了),原來的頭節點向前指向新的節點
else
f.prev = newNode;
size++;
modCount++;
}
// 把資料插入到連結串列尾部
void linkLast(E e) {
// 獲取當前連結串列的尾節點
final Node<E> l = last;
// 建立一個節點,向前指向該連結串列的尾節點,向後指向 null
final Node<E> newNode = new Node<>(l, e, null);
// 將 l(之前的尾節點) 指向新的節點
last = newNode;
// 如果 l 為空,則連結串列的頭節點也指向該新節點,此時連結串列的頭和尾節點都指向該節點
if (l == null)
first = newNode;
// 如果 l 不為空(連結串列不為空),則原來的尾節點向後指向新建立的節點
else
l.next = newNode;
size++;
modCount++;
}
// 在指定節點前面插入值,這裡假設指定節點不為空
void linkBefore(E e, Node<E> succ) {
// 獲取指定節點的前一個節點
final Node<E> pred = succ.prev;
// 建立一共新節點,向前指向 succ 節點的前一個節點,向後指向 succ 節點,數值是 e
final Node<E> newNode = new Node<>(pred, e, succ);
// succ 向前指向新建的節點
succ.prev = newNode;
// 如果 succ 前面的節點為空,則新建的節點就是第一個節點
if (pred == null)
first = newNode;
// 如果 succ 前面的節點不為空,則用 succ 節點向後指向新建的節點
// 此時代表插入完成
else
pred.next = newNode;
size++;
modCount++;
}
// 刪除不為空的頭節點,返回刪除節點的值
private E unlinkFirst(Node<E> f) {
// 獲取頭節點的資料
final E element = f.item;
// 獲取頭節點的後面一個節點 next
final Node<E> next = f.next;
// 將頭節點的資料置空
f.item = null;
// 將頭節點向後指向 null
f.next = null;
// 此時後面一個節點變為頭節點
first = next;
// 如果頭節點向後指向 null,即原本連結串列中就這一個節點,移除後連結串列中就沒有節點了
if (next == null)
last = null;
// 如果頭節點後面還有節點,那麼刪除的頭節點就指向 null
else
next.prev = null;
size--;
modCount++;
return element;
}
// 刪除不為空的尾節點,返回刪除節點的值
private E unlinkLast(Node<E> l) {
// 獲取尾節點的數值
final E element = l.item;
// 獲取尾節點的前面一個節點 prev
final Node<E> prev = l.prev;
// 將尾節點的置空
l.item = null;
// 將尾節點向前指向 null
l.prev = null;
// 此時前面一個節點變為連結串列的尾節點
last = prev;
// 如果尾節點的向前指向 null,即連結串列本來就只有這一個節點,移除後連結串列中就沒有節點了
if (prev == null)
first = null;
// 如果尾節點前面還有節點,則向後指向 null
else
prev.next = null;
size--;
modCount++;
return element;
}
// 刪除指定不為空的節點,返回節點對應的值
E unlink(Node<E> x) {
// 獲取要刪除節點的值
final E element = x.item;
// 獲取刪除節點後面的節點 next,前面的節點 prev
final Node<E> next = x.next;
final Node<E> prev = x.prev;
// 如果要刪除的節點前面沒有節點,說明是第一個節點
if (prev == null) {
// 此時刪除節點後面的那個節點變成頭節點
first = next;
// 如果要刪除的節點不是第一個
} else {
// 讓要刪除節點的前一個節點向後指向要刪除節點的後一個節點,即直接跨過要刪除的節點
prev.next = next;
// 同時向前指向 null
x.prev = null;
}
// 如果要刪除節點後面沒有節點,說明是最後一個節點
if (next == null) {
// 此時刪除節點前面那個節點變為尾節點
last = prev;
// 如果要刪除的節點不是最後一個節點
} else {
// 讓要刪除節點的後一個節點向前指向要刪除節點的前一個節點,還是跳過要刪除的節點
next.prev = prev;
// 同時向後指向 null
x.next = null;
}
// 將要刪除的節點的值置空
x.item = null;
size--;
modCount++;
// 返回刪除的節點
return element;
}
// 獲取指定位置的節點
Node<E> node(int index) {
// 採用二分法來遍歷,如果該位置小於長度的一半,則從頭開始遍歷
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
// 如果位置大於長度的一半,從最後開始遍歷
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}需要注意 Node<E> node(int index) 方法,該方法會在後面的查詢和刪除等方法中用到,它的作用在於,是根據你傳入的位置來判斷是從連結串列的前面還是後開始查詢,當傳入位置小於長度的一半時,從前向後查詢;否則,從後向前查詢
五、新增方法
在指定位置進行插入的時候,會先呼叫 node(int index) 方法判斷該位置是在集合長度的一半之後還是之後,如果小於長度一半則從前向後尋找位置,然後新增元素;否則,從後向前尋找位置,然後新增
// 在集合尾部新增元素
public boolean add(E e) {
linkLast(e);
return true;
}
// 在集合的指定位置新增值
public void add(int index, E element) {
checkPositionIndex(index);
// 如果插入位置正好是集合最後一位的後一位
if (index == size)
// 則在連結串列最後新增
linkLast(element);
else
// 否則先根據位置確定對應的元素
// 然後把指定值插入到該元素的前面
linkBefore(element, node(index));
}
// 在指定位置插入一個集合
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index);
// 將傳入的集合轉為 Object 陣列
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
// 定義兩個節點,pred 是插入位置的前一個節點,succ 是插入位置的後一個節點
Node<E> pred, succ;
// 直接將集合插入到最後
if (index == size) {
// succ 沒什麼用,直接置空
succ = null;
// pred 用來儲存每插入一個元素的位置
pred = last;
// 如果集合不是插入到尾部
} else {
succ = node(index);
pred = succ.prev;
}
// 遍歷集合陣列
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
// 建立新節點,向前指向 pred
Node<E> newNode = new Node<>(pred, e, null);
// 如果 pred 為空,表明新建的節點是頭節點
if (pred == null)
first = newNode;
else
pred.next = newNode;
// pred 儲存最後一個新建節點的位置
pred = newNode;
}
// 如果 succ 是 null,說明集合是直接插入到尾部的
if (succ == null) {
// 此時插入的最後一個元素便是尾節點
last = pred;
// 否則,將插入的最後一個元素和插入位置的後一個節點相連線
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
// 將集合直接插入到尾部
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
// 在集合頭部插入元素
public void addFirst(E e) {
linkFirst(e);
}
// 在集合尾部插入元素
public void addLast(E e) {
linkLast(e);
}六、刪除方法
主要包括三種
- 按照位置刪除
- 按照指定元素刪除(如果重複則只刪除第一次出現的那個元素)
- 從前往後尋找
- 從後往前尋找
- 刪除第一個或最後一個元素
如果從指定位置刪除對應的元素,也會先判斷位置然後再進行對應的操作,這一點和增加操作一樣
// 刪除集合中的第一個元素
public E remove() {
return removeFirst();
}
// 刪除集合中指定位置的節點
public E remove(int index) {
checkElementIndex(index);
// 先使用 node(int index) 方法找到指定位置的節點
// 呼叫 unlink(Node<E> x) 刪除該節點
return unlink(node(index));
}
// 刪除集合中指定的元素(如果集合中有不止一個,則只刪除前面一個)
public boolean remove(Object o) {
// 如果指定元素為 null
if (o == null) {
// 遍歷連結串列中的元素
for (Node<E> x = first; x != null; x = x.next) {
// 只要遍歷到 null,刪除並返回 true
if (x.item == null) {
unlink(x);
return true;
}
}
// 否則,直接根據節點中的元素進行判斷
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
// 刪除第一個頭節點,返回刪除的元素
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
// 刪除最後一個節點,返回刪除的元素
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
// 刪除指定元素(從前往後如果有相同的則只刪除第一次出現的),就是 remove(Object o) 方法
public boolean removeFirstOccurrence(Object o) {
return remove(o);
}
// 刪除指定元素(從後往前如果有相同的則只刪除第一次出現的),就是倒置的 remove(Object o) 方法
public boolean removeLastOccurrence(Object o) {
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
// 清空集合方法
public void clear() {
// 這裡將連結串列從頭到末尾每個節點的元素,向前之前,向後指向前部置空
for (Node<E> x = first; x != null; ) {
Node<E> next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
first = last = null;
size = 0;
modCount++;
}七、修改,獲取的方法
// 在指定位置修改元素,返回被修改的元素的值
public E set(int index, E element) {
checkElementIndex(index);
// 獲取 node(int index) 找到指定該位置的節點
Node<E> x = node(index);
// 獲取該節點的元素,並替換
E oldVal = x.item;
x.item = element;
return oldVal;
}
// 獲取指定位置的元素
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
// 獲取集合的第一個元素
public E getFirst() {
// 獲取頭節點
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
// 獲取集合的最後一個元素
public E getLast() {
// 獲取尾節點
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}八、其他方法
// 返回傳入的元素在集合中的位置,如果沒有則返回 -1
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
// 判斷集合中是否存在傳入的元素
public boolean contains(Object o) {
return indexOf(o) != -1;
}九、遍歷方法
(1) 迭代器方式
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()) {
iterator.next();
}(2) 使用 for 迴圈
for(int i=0; i<list.size(); i++) {
list.get(i);
}(3) 使用 foreach
for(String i: list) {
}其中迭代器和 foreach 遍歷的方式速度基本是一樣的,因為 foreach 本質上也是用迭代器進行遍歷。一定不要使用 for 迴圈對 LinkedList 進行遍歷,速度會慢到令人絕望