
JAVA面試——資料庫知識
1、資料庫隔離級別有哪些,各自的含義是什麼,MYSQL預設的隔離級別是是什麼。
(1)、Read Uncommitted(讀取未提交內容):會出現髒讀,也就是可能讀取到其他會話中未提交事務修改的資料。
(2)、Read Committed(讀取提交內容):不可重複讀,只能讀取到已經提交的資料。Oracle等資料庫預設的隔離級別。
(3)、Repeatable Read(可重讀):出現幻讀。在同一個事務內的查詢都和事務開始時刻一致。InnoDB預設級別。
(4)、Serializable(序列讀):完全序列化的讀,每次讀都需要獲得表級共享鎖,讀寫相互都會阻塞。
MYSQL預設的隔離級別:
2、什麼是幻讀。 官方:幻讀是指當事務不是獨立執行時發生的一種現象,例如第一個事務對一個表中的資料進行了修改,比如這種修改涉及到表中的“全部資料行”。同時,第二個事務也修改這個表中的資料,這種修改是向表中插入“一行新資料”。那麼,以後就會發生操作第一個事務的使用者發現表中還存在沒有修改的資料行,就好象發生了幻覺一樣。一般解決幻讀的方法是增加範圍鎖RangeS,鎖定檢索範圍為只讀,這樣就避免了幻讀。 個人解讀:舉個栗子,A查詢ID(唯一索引)>6的資料,查詢結果為空,此時B插入一條ID=6的資料,因為當前A的隔離級別是可重複讀
3、MYSQL有哪些儲存引擎,各自優缺點。
☞ MYSQL儲存引擎種類(瞭解):MyISAM、InnoDB、BDB、MEMORY、MERGE、EXAMPLE、NDBCluster、ARCHIVE、CSV、BLACKHOLE、FEDERATED等。在Oracle 和SQL Server等資料庫中只有一種儲存引擎,所有資料儲存管理機制都是一樣的。而MySql資料庫提供了多種儲存引擎。使用者可以根據不同的需求為資料表選擇不同的儲存引擎,使用者也可以根據自己的需要編寫自己的儲存引擎。簡單的說下什麼是儲存引擎,儲存引擎說白了就是如何儲存資料、如何為儲存的資料建立索引和如何更新、查詢資料等技術的實現方法。因為在關係資料庫中資料的儲存是以表的形式儲存的,所以儲存引擎也可以稱為表型別(即儲存和操作此表的型別)。

4、高併發下,如何做到安全的修改同一行資料。
♀ 使用悲觀鎖:悲觀鎖本質是當前只有一個執行緒執行操作,排斥外部請求的修改。遇到加鎖的狀態,就必須等待。結束了喚醒其他執行緒進行處理。雖然此方案的確解決了資料安全的問題,但是,我們的場景是“高併發”。也就是說,會很多這樣的修改請求,每個請求都需要等待“鎖”,某些執行緒可能永遠都沒有機會搶到這個“鎖”,這種請求就會死在那裡。同時,這種請求會很多,瞬間增大系統的平均響應時間,結果是可用連線數被耗盡,系統陷入異常。(細節參考5)
♂ 也是通過FIFO(First Input First Output,先進先出)快取佇列思路:直接將請求放入佇列中,就不會導致某些請求永遠獲取不到鎖。看到這裡,是不是有點強行將多執行緒變成單執行緒的感覺哈。

5、樂觀鎖和悲觀鎖是什麼,InnoDB的標準行級鎖有哪2種,解釋其含義。
♩ 樂觀鎖(Optimistic Concurrency Control,縮寫”OCC”):是一種併發控制的方法。樂觀的認為多使用者併發的事務在處理時不會彼此互相影響,各事務能夠在使用鎖的情況下處理各自的資料。在提交更新資料之前,每個事務會先檢查該事務讀取資料後,有沒有其他事務又修改了該資料。如果其他事務有更新的話,正在提交的事務會進行回滾。不過,當需求多為更新資料時,就會增大資料之間的衝突,也就增大CPU的計算開銷,此時不建議使用。
♪ 資料是否修改的標準是:在表中的資料進行操作時,先給資料表最新的資料加一個版本(version)欄位,每操作一次,將那條記錄的版本號加1。也就是先查詢出那條記錄,獲取出version欄位,修改完資料後準備提交之前,先判斷此刻version的值是否與剛剛查詢出來時的version的值相等,如果相等,則說明這段期間,沒有其他程式對其進行操作,則可以執行更新,將version欄位的值加1;如果更新時發現此刻的version值與剛剛獲取出來的version的值不相等,則說明這段期間已經有其他程式對其進行操作了,則不進行更新操作。

1.查詢出商品資訊
select (status,status,version) from t_goods where id=#{id}
2.根據商品資訊生成訂單
3.修改商品status為2
update t_goods
set status=2,version=version+1
where id=#{id} and version=#{version};♫ 悲觀鎖(Pessimistic Concurrency Control,縮寫”PCC”):與樂觀鎖相對應的就是悲觀鎖了。悲觀鎖就是在操作資料時,認為此操作會出現資料衝突,所以在進行每次操作時都要通過獲取鎖才能進行對相同資料的操作,這點跟java中的synchronized很相似,所以悲觀鎖需要耗費較多的時間。所以悲觀併發控制主要用於資料爭用激烈的環境,以及發生併發衝突時使用鎖保護資料的成本要低於回滾事務的成本的環境中。另外與樂觀鎖相對應的,悲觀鎖是由資料庫自己實現了的,要用的時候,我們直接呼叫資料庫的相關語句就可以了。說到這裡,由悲觀鎖涉及到的另外兩個鎖概念就出來了,它們就是共享鎖與排它鎖。共享鎖和排它鎖是悲觀鎖的不同的實現,它倆都屬於悲觀鎖的範疇。

#0.開始事務
begin;/begin work;/start transaction; (三者選一就可以)
#1.查詢出商品資訊
select status from t_goods where id=1 for update;
#2.根據商品資訊生成訂單
insert into t_orders (id,goods_id) values (null,1);
#3.修改商品status為2
update t_goods set status=2;
#4.提交事務
commit;/commit work;InnoDB的標準行級鎖有哪2種: ♬共享鎖:共享鎖指的就是對於多個不同的事務,對同一個資源共享同一個鎖,在執行語句後面加上lock in share mode就代表對某些資源加上共享鎖。 ♬排它鎖:排它鎖與共享鎖相對應,就是指對於多個不同的事務,對同一個資源只能有一把鎖。在需要執行的語句後面加上for update就可以了。對於update,insert,delete語句會自動加排它鎖。 總結:樂觀鎖適用於多讀的應用型別,這樣可以提高吞吐量,像資料庫如果提供類似於write_condition機智的其實都是提供的樂觀鎖。 相反,如果經常發生衝突,上層應用會不斷進行 retry,這樣反而降低了效能,所以這種情況下用悲觀鎖比較合適
6、SQL優化的一般步驟是什麼,怎麼看執行計劃,如何理解其中各個欄位的含義。
【1】、通過 show status 命令瞭解各種 sql 的執行頻率。mysql客戶端連線成功後,通過show [session|global] status命令可以提供服務狀態資訊,也可以使用mysqladmin extend-status命令獲取這些訊息。


☛ id:select查詢的序列號,包含一組數字,表示查詢中執行select子句或操作表的順序。三種情況:id相同--->執行順序由上而下。id不同--->如果是子查詢,id序號會遞增,id越大優先順序越高,越先被執行。id相同不同同時存在--->id如果相同,可以認為是一組,由上往下執行;在所有組裡id越大,優先順序越高,越先執行。
☛ select_type:型別:主要用於區別普通查詢、聯合查詢、子查詢等的複雜程度。

㏘ SIMPLE:簡單的select查詢,查詢中不包含子查詢或者UNION。 ㏘ PRIMARY:查詢中若包含任何複雜的自查詢,最外層查詢為PRIMARY。 ㏘ SUBQUERY:在SELECT 或 WHERE中包含子查詢。 ㏘ DERIVED:在FROM列表中包含的子查詢被標記為DERIVED(衍生)MySQL會遞迴執行這些子查詢,把結果放進臨時表。 ㏘ UNION:若第二個SELECT出現在UNION之後,則被標記為UNION,若UNION包含在FROM子句的子查詢,則外層SELECT將被標記為DERIVED。 ㏘ UNION RESULT:從UNION表中獲取結果的SELECT。 ☛ table:顯示這行資料是關於那張表的。
☛ type:
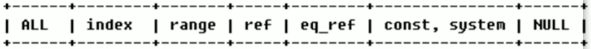
㏘ 從最好到最差:system>const>eq_ref>ref>range>index>ALL,一般達到rang級別,最好達到ref級別。 ☛ possible_keys :顯示可能應用到這張表中的索引,查詢欄位上若存在索引則列出來,但不一定被查詢實際使用。 ☛ keys:實際使用的索引。如果未null,則沒有使用索引。若查詢中出現了覆蓋索引(覆蓋索引:查詢的欄位和建立的索引的欄位和個數完全一樣時),則該索引只出現key列表中。 ☛ key_len:表示索引中使用的位元組數,可通過該列查找出使用索引的長度。在不損壞精準性的情況下,長度越短越好。key_len顯示的值為索引欄位的最大可能長度,並非實際長度,即key_len是根據表定義實際計算出來的,不是通過表內檢出來的。 ☛ ref:顯示索引的那一列被使用,如果可能的話,是一個常數。那些列或常量被用於查詢索引上的值。 ☛ rows:根據表統計資訊及索引選用情況,大致估算出找到所需的記錄的行數。 ☛ Extra:包含不適合在其他列中顯示,但十分重要的資訊。 更多優化功能參考:https://blog.csdn.net/zhengzhaoyang122/article/details/79463583
7、資料庫會死鎖嗎,舉一個死鎖的例子,mysql怎麼解決死鎖。 ▶ 會產生死鎖,具體舉個栗子,如下:
-- 建立表test1
CREATE TABLE test1 (
id int(11) NOT NULL AUTO_INCREMENT,
name varchar(10) NOT NULL,
PRIMARY KEY (id)
);
insert into test1 values('hello');
-- 建立表test2
CREATE TABLE test2 (
id int(11) NOT NULL AUTO_INCREMENT,
name varchar(10) NOT NULL,
PRIMARY KEY (id)
);
-- Transcation 1
begin;
insert into test2 select * from test1 where id = 1;
delete from test1 where id = 1;
-- Transcation 2
begin;
insert into test2 select * from test1 where id = 1;| Transcation1 | Transcation2 |
| ---這條sql得到test1表主鍵索引鎖共享鎖S(id=1) insert into test2 select * from test1 where id = 1; | |
| ---這條sql試圖獲取test1表主鍵索引鎖共享鎖S(id=1),但是已經被T1佔有,所以它進入鎖請求佇列. insert into test2 select * from test1 where id = 1; | |
|
---這條sql試圖把自己擁有的test1表主鍵索引鎖共享鎖S(id=1)升級為排它鎖X(id=1) ---這時T1也發起一個鎖請求,這個時候mysql發現鎖請求佇列裡邊已存在一個事物T2對(id=1)的這條記錄申請了S鎖,死鎖產生了。 delete from test1 where id = 1; |
|
| 死鎖產生後mysql根據兩個事務的權重,事務2的權重更小,被選為死鎖的犧牲者,rollback | |
| T2 rollback 之後T1成功獲取了鎖執行成功 |
▶要解決死鎖首先要了解產生死鎖的原因:①、系統資源不足。②、程序執行推進的順序不合適。③、資源分配不當等。| ㊧、如果系統資源充足,程序的資源請求都能夠得到滿足,死鎖出現的可能性就很低,否則就會因爭奪有限的資源而陷入死鎖。其次,程序執行推進順序與速度不同,也可能產生死鎖。 ▶產生死鎖的四個必要條件:①、互斥條件:一個資源每次只能被一個程序使用。 ②、請求與保持條件:一個程序因請求資源而阻塞時,對已獲得的資源保持不放。 ③、不剝奪條件:程序已獲得的資源,在末使用完之前,不能強行剝奪。 ④、迴圈等待條件:若干程序之間形成一種頭尾相接的迴圈等待資源關係。 ▶這四個條件是死鎖的必要條件,只要系統發生死鎖,這些條件必然成立,而只要上述條件之一不滿足,就不會發生死鎖。 ▶這裡提供兩個解決資料庫死鎖的方法: 1)重啟資料庫。 2)殺掉搶資源的程序:先查哪些程序在搶資源:
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX;☎、殺掉搶資源的程序:
Kill trx_mysql_thread_id;8、MySql的索引原理,索引的型別有哪些,如何建立合理的索引,索引如何優化。 MySql索引的原理:1)、通過不斷地縮小想要獲取資料的範圍來篩選出最終想要的結果,同時把隨機的事件變成順序的事件,也就是說,有了這種索引機制,我們可以總是用同一種查詢方式來鎖定資料。 2)、索引是通過複雜的演算法,提高資料查詢效能的手段。從磁碟io到記憶體io的轉變。 MySql索引原理參考部落格:https://blog.csdn.net/u013235478/article/details/50625677 MySql索引的型別:1)、普通索引index:加速查詢 2)、唯一索引:①、主鍵索引:primary key:加速查詢+主鍵唯一約束且不為空。 ②、唯一索引:unique:加速查詢+主鍵唯一約束。 3)、聯合索引:①、primary key(id,name):聯合主鍵索引。 ②、unique(id,name):聯合唯一索引。 ③、unique(id,name):聯合普通索引。 4)、全文索引fulltext:用於搜尋很長一篇文章的時候,效果最好。 5)、空間索引spatial:瞭解就好,幾乎不用 建立索引的原則:1)、最左字首匹配原則,非常重要的原則,mysql會一直向右匹配直到遇到範圍查詢(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)順序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引則都可以用到,a,b,d的順序可以任意調整。 2)、=和in可以亂序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意順序,mysql的查詢優化器會幫你優化成索引可以識別的形式。 3)、儘量選擇區分度高的列作為索引,區分度的公式是count(distinct col)/count(*),表示欄位不重複的比例,比例越大我們掃描的記錄數越少,唯一鍵的區分度是1,而一些狀態、性別欄位可能在大資料面前區分度就是0,那可能有人會問,這個比例有什麼經驗值嗎?使用場景不同,這個值也很難確定,一般需要join的欄位我們都要求是0.1以上,即平均1條掃描10條記錄。 4)、索引列不能參與計算,保持列“乾淨”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很簡單,b+樹中存的都是資料表中的欄位值,但進行檢索時,需要把所有元素都應用函式才能比較,顯然成本太大。所以語句應該寫成create_time = unix_timestamp(’2014-05-29’)。 5)、儘量的擴充套件索引,不要新建索引。比如表中已經有a的索引,現在要加(a,b)的索引,那麼只需要修改原來的索引即可 索引如何優化,領出來單獨寫了一篇部落格:https://blog.csdn.net/zhengzhaoyang122/article/details/79463583
9、聚集索引和非聚集索引的區別。 “聚簇”:就是索引和記錄緊密在一起。 “非聚簇索引”:索引檔案和資料檔案分開存放,索引檔案的葉子頁只儲存了主鍵值,要定位記錄還要去查詢相應的資料塊。
10、select for update 是什麼含義,會鎖表還是鎖行或是其他。 select for update 語句是我們經常使用手工加鎖語句。藉助for update子句,我們可以在應用程式的層面手工實現資料加鎖保護操作。屬於併發行鎖,這個我們上面在悲觀鎖的時候也有介紹。
11、為什麼要用Btree實現,它是怎麼分裂的,什麼時候分裂,為什麼是平衡的。 Key 超過1024才分裂 因為隨著資料的增多,一個結點的key滿了,為了保持B樹的特性,就會產生分裂,就向紅黑樹和AVL樹為了保持樹的性質需要進行旋轉一樣!
12、資料庫的ACID是什麼。 ☛ A,atomic,原子性,要麼都提交,要麼都失敗,不能一部分成功,一部分失敗。 ☛ C,consistent,一致性,事物開始及結束後,資料的一致性約束沒有被破壞 ☛ I,isolation,隔離性,併發事物間相互不影響,互不干擾。 ☛ D,durability,永續性,已經提交的事物對資料庫所做的更新必須永久儲存。即便發生崩潰,也不能被回滾或資料丟失。
13、某個表有近千萬資料,CRUD比較慢,如何優化。 ◥ 資料千萬級別之多,佔用的儲存空間也比較大,可想而知它不會儲存在一塊連續的物理空間上,而是鏈式儲存在多個碎片的物理空間上。可能對於長字串的比較,就用更多的時間查詢與比較,這就導致用更多的時間。 1)、作為關係型資料庫,是什麼原因出現了這種大表?是否可以做表拆分,減少單表字段數量,優化表結構。 2)、在保證主鍵有效的情況下,檢查主鍵索引的欄位順序,使得查詢語句中條件的欄位順序和主鍵索引的欄位順序保持一致。 3)、在程式邏輯中採用手動事務控制,不要每插入一條資料就自動提交,而是定義一個計數器,進行批量手動提交,能夠有效提高執行速度。
14、Mysql怎麼優化table scan的。 ☈ 避免在where子句中對欄位進行is null判斷。 ☈ 應儘量避免在where 子句中使用!=或<>操作符,否則將引擎放棄使用索引而進行全表掃描。 ☈ 避免在where 子句中使用or 來連線條件。 ☈ in 和not in 也要慎用。 ☈ Like查詢(非左開頭)。 ☈ 使用[email protected]引數這種。 ☈ where 子句中對欄位進行表示式操作num/2=XX。 ☈ 在where子句中對欄位進行函式操作。
15、如何寫sql能夠有效的使用到複合索引。 ▓ 由於複合索引=組合索引,類似多個木板拼接在一起,如果中間斷了就無法用了,所以要能用到複合索引,首先開頭(第一列)要用上,比如index(a,b) 這種,我們可以select table tname where a=XX 用到第一列索引 如果想用第二列 可以 and b=XX 或者and b like‘TTT%’。
16、mysql中in 和exists 區別。 ♒mysql中的in語句是把外表和內表作hash 連線,而exists語句是對外表作loop迴圈,每次loop迴圈再對內表進行查詢。一直大家都認為exists比in語句的效率要高,這種說法其實是不準確的。這個是要區分環境的。 ㊤、如果查詢的兩個表大小相當,那麼用in和exists差別不大。 ㊥、如果兩個表中一個較小,一個是大表,則子查詢表大的用exists,子查詢表小的用in。 ㊦、not in 和not exists如果查詢語句使用了not in 那麼內外表都進行全表掃描,沒有用到索引;而not extsts 的子查詢依然能用到表上的索引。所以無論那個表大,用not exists都比not in要快。 ▁▂▃ EXISTS只返回TRUE或FALSE,不會返回UNKNOWN。 ▁▂▃ IN當遇到包含NULL的情況,那麼就會返回UNKNOWN。
17、資料庫自增主鍵可能的問題。
後續晚上補充,現有個講座,就寫到這。。。
【1】、使用自增主鍵對資料庫做分庫分表,可能出現一些諸如主鍵重複等的問題,或者在資料庫匯入的時候,可能會因為主鍵出現一些問題。 【2】、
18、MVCC的含義,如何實現的。
19、你做過的專案裡遇到分庫分表了嗎,怎麼做的,有用到中介軟體麼,比如sharding jdbc等,他們的原理知道麼。
20、MYSQL的主從延遲怎麼解決。