
高效能MySQL之Schema設計對系統性能的影響
本文主要是對高效能MySQL書籍中的內容進行一個簡短的總結以及個人理解,記錄一下學習的過程。
前言:
與資料庫互動的軟體系統中,系統的架構實現以及資料互動的SQL語句對系統的效能至關重要,系統的資料模型設計實現對系統性能的影響通俗一點說就是資料庫Schema設計對系統的影響。資料庫Schema的設計並不是一件簡單的事情,並不是說做到第三、四正規化就算可以了。(個人注:通常大型系統的資料庫Schema設計會通過資料冗餘來提高效能)。不同的資料庫Schema對系統的效能影響各不相同,下面通過一個例子進行說明:
需求概述:一個簡單的討論系統,需要有使用者、使用者組、組討論區這三部分基本功能。
簡單分析:
- 需要存放使用者資料
- 存放分組資訊以及使用者與分組的關係資訊
- 需要存放討論資訊的表
解決方案1:
比較直觀的設計,使用四張表進行儲存,使用者表、分組表、使用者分組關係表以及討論組帖子表,各個表如下:
- 使用者表 user

2. 分組表 groups

3.使用者分組關係表 user_group
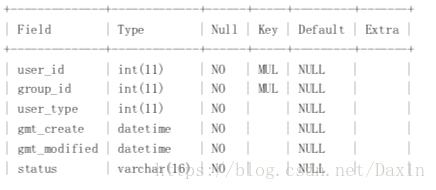
4. 討論帖子表 group_message
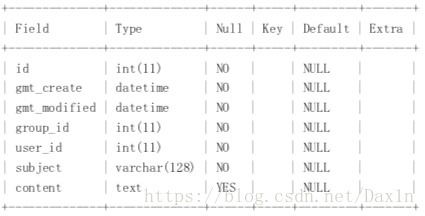
優化方案2:
1. 使用者表 user

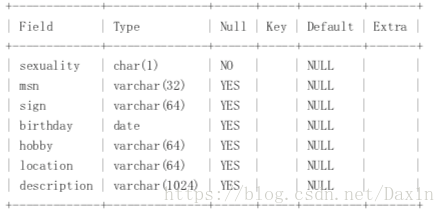
2.使用者畫像表 user_profile
3.分組表與使用者分組關係表不變
4.討論組帖子表(注意:此表添加了一個author欄位)

5:分組訊息內容表

方案評估:
憑藉經驗,任何好的設計都是迭代出來的,所謂迭代其實就是在專案的過程中逐漸發現問題,解決問題。馬克思說過:實踐是檢驗真理的唯一標準,資料庫schema設計也不例外,接下來就檢驗一下兩種方案的優劣:
1、場景一
使用者登陸討論區,選擇一個分組需要將該分組的所有帖子進行分頁顯示,暫時假定一頁顯示20個條目,此時分別對應的SQL如下:
方案1查詢語句:
SELECT u.id, u.nick_name, t.id, t.subject FROM USER u, ( SELECT user_id, subject, id FROM GROUP_MESSAGE WHERE group_id = '1001' ORDER BY gmt_modified LIMIT 20 ) t WHERE t.user_id = u.id;
方案2查詢語句:
SELECT user_id, subject, id, author
FROM GROUP_MESSAGE
WHERE group_id = '1001'
ORDER BY gmt_modified
LIMIT 20結論:很直觀就可以發現,該場景下方案2更優秀,資料庫的join操作往往是導致資料效能差的主要原因,方案2不需要join,一張單獨的表就可以直接查詢出來。該設計就是違背資料庫的正規化,但是通過資料冗餘的方式可以提升效能,通過本場景可以知道,讓我們需要避免由於join查詢帶來的效能瓶頸時候可以使用冗餘資料解決,企業中很常見。擔心細心讀者會發現這種設計帶來了暱稱更新需要更新兩張表,對於這個問題一般來說通過程式邏輯控制更新即可,總和來說還是利大於弊,但是實際上很多論壇都是一旦更選擇了使用者名稱字便不再支援修改名字,這樣就避免了資料不一致的問題。
2、場景2
使用者可能時常查詢使用者的資訊資料,但是次數相對比較,一般都是使用者在修改個人資料或者點選其他使用者頭像時候時候才會檢視一個使用者的完整資訊,通常情況下只是會顯示使用者的部分資訊,我們可以這些必須要顯示的部分使用者資訊與部分其他不經常被訪問的使用者資訊分為兩張表儲存,例如方案2設計中的使用者表與使用者畫像表。這麼做對查詢帶來的好處是:可以減少查詢的檢索資料量,提高檢索效能。但是你可能會覺著當要查詢使用者的完整資訊時候需要進行使用者表與畫像表的關聯,效能會變差?!效能確實會降低,但是由於使用者表與畫像表都是1對1關聯,關聯欄位的過濾性非常高,在根據場景也知道,查詢使用者完整資訊發生的頻次也不高,因此此處來帶的損失與場景1中的獲益對比而言,非常微不足道。
感悟:
好的程式碼一定是重構出來的,好的設計一定是迭代驗證出來的。實踐是檢驗真理的唯一標準。