
使用scikit-learn進行初步的資料預處理
阿新 • • 發佈:2018-12-10
對於機器學習來說,sklearn具有非常豐富且方便的演算法模型庫,現在我們將使用sklearn中的preprocessing庫來對資料進行初步的預處理。
1.Z-Score標準化(儘量使均值為0,方差為1)
標準化即將資料按比例進行縮放,使其落入一個限定的區間。特點是使得不同量綱之間的特徵具有可比性,同時不改變原始資料的分佈。屬於無量綱化處理。
公式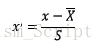
需要計算特徵的均值和標準差,使用sklearn中preprocessing庫中的StandardScaler類對特徵進行標準化程式碼如下:
from sklearn.preprocessing import StandardScaler 特點:
1.標準化後不會改變原始資料的分佈,即不會影響各自特徵對目標函式的權重。 2.在樣本資料大的情況下比較穩定,適用於嘈雜的現代大資料場景。
2.區間縮放法
顧名思義,將資料進行伸縮變換到[0, 1]或者是[-1, 1]範圍內進行處理,也是屬於無量綱化處理。
最小最大值標準化(MinMaxScaler)
使用sklearn中preprocessing庫中的MinMaxScaler類對特徵進行標準化程式碼如下:
from 絕對值最大標準化
使用sklearn中preprocessing庫中的MaxAbsScaler
from preprocessing import MaxAbsScaler
# 通過除以最大值,將資料縮放至[-1, 1]
# 這意味著資料以0為中心或者含有非常多的0,即稀疏資料
mas = MaxAbsScaler()
train_data = mas.fit_transform(data)特點:
1.對不同特徵維度資料進行伸縮變換,達到歸一。 2.改變了原始資料的分佈,即各特徵對目標函式的權重影響是一致的。 3.可對方差特別小的資料增強其穩定性,也可以維持稀疏矩陣中多為0的樣本條目。 4.可以提高迭代求解的收斂速度和精度。 5.最小值和最大值容易受噪聲點影響,魯棒性差。
3.正則化
奧卡姆剃刀定律:如無需要,勿增實體。因此模型越複雜,越容易出現過擬合。之前以最小化損失函式(經驗風險最小化)為目標,後來以最小化損失函式和模型複雜度(結構風險最小化)為目標。所以,通過降低模型的複雜度來防止模型過擬合的規則稱為正則化。
- 機器學習中最常見的無外乎就是
L1正則化和L2正則化。 - 對於線性迴歸模型而言,使用L1正則化的模型稱為
Lasso迴歸,使用L2正則化的模型稱為嶺迴歸(Ridge 迴歸)。 - 在一般迴歸模型分析中,w一般稱為迴歸係數,而使用正則化項就是對迴歸係數進行處理。
- L1正則化是指權值向量w中各個元素的絕對值之和,通常表示為||w||1
- L2正則化是指權值向量w中各個元素的平方和然後再求平方根,通常表示為||w||2
- L1正則使得帶有L1正則的模型在擬合過程中,部分引數權值降為0,可以產生稀疏權值矩陣,進而用來進行特徵選擇。
- L2正則即使帶有L2正則的模型在擬合的過程中,不斷的讓權值變小,因此加入有資料發生偏移(噪聲點)也不會對結果造成什麼影響,即抗干擾能力強。
- L1正則之所以一定程度上可以防止過擬合,是因為當L1的正則化係數很小時,得到的最優解會很小,可以達到和L2正則化類似的效果。
使用sklearn中preprocessing庫中的normalize類對特徵進行標準化程式碼如下:
from preprocessing import normalize
# data 為被正則的資料集,norm 引數選擇為 l1, l2
# 即選擇L1正則還是L2正則
train_data = normalize(data, norm = 'l2')