
馬士兵老師高併發之6大執行緒池
Executor
執行器,這是一個介面,內部維護了一個方法execute它負責執行一項任務。引數為Runnable,方法的具體實現由我們自己來執行。如下面的程式碼,我們既可以使用單純的方法呼叫也可以新啟一個新的執行緒去執行Runnable的run方法。
import java.util.concurrent.Executor; public class T01_MyExecutor implements Executor { public static void main(String[] args) { new T01_MyExecutor().execute(()->System.out.println("hello executor")); } @Override public void execute(Runnable command) { //new Thread(command).run(); command.run(); } }
ExecutorService
代表著啟動一系列的執行緒為使用者提供服務(本質上也是一個執行器),比如說Java8的官方文件就舉了一個網路接受連線池的例子(程式碼如下)。在這裡ExecutorService就代表著一個的執行緒池對外提供接受網路請求的服務。同時它也是一系列執行緒池的介面比如說
RorkJoinPool、ScheduledThreadPoolExecutor,、ThreadPoolExecutor等。同時它可以提交Callable與Runnable的物件返回一個未來的執行結果物件Future。這裡順便說一下,Callable是一個增強版的Runnable,它的call方法可以丟擲異常可以有返回值。其中它的返回值放在了Future物件中,我們可以使用Future物件的get方法來獲得返回值。
class NetworkService implements Runnable { private final ServerSocket serverSocket; private final ExecutorService pool; public NetworkService(int port, int poolSize) throws IOException { serverSocket = new ServerSocket(port); pool = Executors.newFixedThreadPool(poolSize); } public void run() { // run the service try { for (;;) { pool.execute(new Handler(serverSocket.accept())); } } catch (IOException ex) { pool.shutdown(); } } } class Handler implements Runnable { private final Socket socket; Handler(Socket socket) { this.socket = socket; } public void run() { // read and service request on socket } }
除了以上方法來建立一個ExecutorService還可以使用Executors這個工具類來建立它,在這裡我們可以把Executors理解為就像utils,collections的工具類。
Future將來的結果
Future常與Callable聯合使用,Future可以獲得Callable執行後的返回值。如果想新建一個執行緒執行一個這個Callable中的call方法而且獲得返回值的話我們可以使用以下的思路。
方案一:new Thread(new FutureTask(一個實現了Callable的類的物件)).start();使用FutureTask來接收任務的返回值。
方案二:new一個執行緒池然後然後提交Callable的實現的物件。使用Future來獲得Callable的返回值。具體實現如下:
/**
* 認識future
*/
package yxxy.c_026;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import java.util.concurrent.FutureTask;
import java.util.concurrent.TimeUnit;
public class T06_Future {
public static void main(String[] args) throws InterruptedException, ExecutionException {
FutureTask<Integer> task = new FutureTask<>(()->{
TimeUnit.MILLISECONDS.sleep(500);
return 1000;
}); //new Callable () { Integer call();}
new Thread(task).start();
System.out.println(task.get()); //阻塞
//*******************************
ExecutorService service = Executors.newFixedThreadPool(5);
Future<Integer> f = service.submit(()->{
TimeUnit.MILLISECONDS.sleep(500);
return 1;
});
System.out.println(f.get());
System.out.println(f.isDone());
}
}6大執行緒池的介紹
FixedThreadPool
一個固定大小的執行緒池執行以下程式得到相應的結果:
public class T05_ThreadPool {
public static void main(String[] args) throws InterruptedException {
ExecutorService service = Executors.newFixedThreadPool(5); //execute submit
for (int i = 0; i < 6; i++) {
service.execute(() -> {
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName());
});
}
System.out.println(service);
service.shutdown();
System.out.println(service.isTerminated());
System.out.println(service.isShutdown());
System.out.println(service);
TimeUnit.SECONDS.sleep(5);
System.out.println(service.isTerminated());
System.out.println(service.isShutdown());
System.out.println(service);
}
}執行結果
[email protected][Running, pool size = 5, active threads = 5, queued tasks = 1, completed tasks = 0]
false
true
[email protected][Shutting down, pool size = 5, active threads = 5, queued tasks = 1, completed tasks = 0]
pool-1-thread-1
pool-1-thread-2
pool-1-thread-5
pool-1-thread-4
pool-1-thread-3
pool-1-thread-1
true
true
[email protected][Terminated, pool size = 0, active threads = 0, queued tasks = 0, completed tasks = 6]- 整個程式new了一個5個執行緒的執行緒池,使用for迴圈向這個執行緒池拋了5個任務。它的執行原則是哪一個執行緒空閒就由哪個執行緒來執行這個任務。所以我們看到的執行緒池的執行緒序號是不固定的亂序的,但是它有個規則就是先執行完任務的執行緒會在新執行緒到來時優先分配到任務。
- 執行緒池shutdown之後程式不會立刻停止而是要等待的所有執行緒都執行完畢之後再停止服務,所以我們看到的就是Runningà Shutting downà Terminated
- 執行緒池的任務大體上分為兩類,等待就緒佇列與已完成任務的佇列。通過輸出結果我們可以看出在開始有5個正在執行的任務1個任務駐留在就緒佇列等待執行,在執行結束後我們的已執行佇列中就會有6個元素。
CachedPool
CachedPool的主要特點就是如果新來的一個任務需要這個執行緒池來執行的話,如果當前執行緒池沒有閒置的執行緒那麼就新啟動一個執行緒,如果有空閒執行緒那麼就使用其中的一個空閒執行緒。就是這樣的一個有彈性的執行緒池。預設情況下當一個執行緒空閒超過60s那麼就會銷燬,而且執行緒數量最大不能超過int型別的最大值或者是計算機記憶體的大小。以下程式碼展示了這樣的特性:
package yxxy.c_026;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class T08_CachedPool {
public static void main(String[] args) throws InterruptedException {
ExecutorService service = Executors.newCachedThreadPool();
System.out.println(service);
for (int i = 0; i < 2; i++) {
service.execute(() -> {
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName());
});
}
System.out.println(service);
TimeUnit.SECONDS.sleep(80);
System.out.println(service);
}
}SingleThreadPool
這個執行緒池中只有一個執行緒,那麼你可能回會問這與單個執行緒有什麼區別呢?: - ) 原因就是它可以被複用!它的使用場景就是當我們需要保證任務執行的先後順序的時候就可以使用它。
ScheduledPool
一個定時執行任務的一個執行緒池它所執行的任務的引數如下:
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit)initialDelay:在開始多少單位時間的時候執行第一個任務。
Period:每隔多長時間執行下一個任務。
Unit:時間的單位。
它的底層基於DelayedWorkQueue。
以下程式碼展示了已啟動就開始執行的而且步幅為0.5s的執行緒執行方式:
public class T10_ScheduledPool {
public static void main(String[] args) {
ScheduledExecutorService service = Executors.newScheduledThreadPool(4);
service.scheduleAtFixedRate(()->{
try {
TimeUnit.MILLISECONDS.sleep(new Random().nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName());
}, 0, 500, TimeUnit.MILLISECONDS);
}
}工作竊取執行緒池,一般情況下CPU是幾核的就會啟動幾個執行緒,每一個執行緒都維護者自己的一個執行佇列的,當某些執行緒將自己佇列中的任務都執行完畢的時候就會去其他執行緒的佇列中竊取任務來執行以此提高效率。它的底層是基於ForkJoinPool的,常常用於任務分配不均勻的場景中。
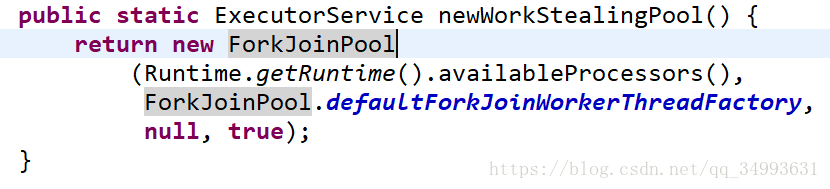
需要注意的是,這個執行緒池產生的都是daemon的執行緒(後臺執行緒),所以我們需要將主執行緒阻塞來觀察輸出結果。
public class T11_WorkStealingPool {
public static void main(String[] args) throws IOException {
ExecutorService service = Executors.newWorkStealingPool();
System.out.println(Runtime.getRuntime().availableProcessors());
service.execute(new R(1000));
service.execute(new R(2000));
service.execute(new R(2000));
service.execute(new R(2000)); //daemon
service.execute(new R(2000));
//由於產生的是精靈執行緒(守護執行緒、後臺執行緒),主執行緒不阻塞的話,看不到輸出
System.in.read();
}
static class R implements Runnable {
int time;
R(int t) {
this.time = t;
}
@Override
public void run() {
try {
TimeUnit.MILLISECONDS.sleep(time);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(time + " " + Thread.currentThread().getName());
}
}
}ForkJoinPool
這個執行緒池設計的思想就與MapReduce極其相似,將一個大的任務分解成一個個小的任務當多個執行緒來執行。然後將計算的結果彙總得到最終結果。這也是用到了遞迴的思想。其中它的任務分為兩種一種沒有返回值是RecursiveAction,一種有返回值RecursiveTask。常常用於大量資料的運算以下為示例程式碼:
package yxxy.c_026;
import java.io.IOException;
import java.util.Arrays;
import java.util.Random;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class T12_ForkJoinPool {
static int[] nums = new int[1000000];
static final int MAX_NUM = 50000;
static Random r = new Random();
static {
for(int i=0; i<nums.length; i++) {
nums[i] = r.nextInt(100);
}
System.out.println(Arrays.stream(nums).sum()); //stream api
}
/*
static class AddTask extends RecursiveAction {
int start, end;
AddTask(int s, int e) {
start = s;
end = e;
}
@Override
protected void compute() {
if(end-start <= MAX_NUM) {
long sum = 0L;
for(int i=start; i<end; i++) sum += nums[i];
System.out.println("from:" + start + " to:" + end + " = " + sum);
} else {
int middle = start + (end-start)/2;
AddTask subTask1 = new AddTask(start, middle);
AddTask subTask2 = new AddTask(middle, end);
subTask1.fork();
subTask2.fork();
}
}
}
*/
static class AddTask extends RecursiveTask<Long> {
int start, end;
AddTask(int s, int e) {
start = s;
end = e;
}
@Override
protected Long compute() {
if(end-start <= MAX_NUM) {
long sum = 0L;
for(int i=start; i<end; i++) sum += nums[i];
return sum;
}
int middle = start + (end-start)/2;
AddTask subTask1 = new AddTask(start, middle);
AddTask subTask2 = new AddTask(middle, end);
subTask1.fork();
subTask2.fork();
return subTask1.join() + subTask2.join();
}
}
public static void main(String[] args) throws IOException {
ForkJoinPool fjp = new ForkJoinPool();
AddTask task = new AddTask(0, nums.length);
fjp.execute(task);
long result = task.join();
System.out.println(result);
//System.in.read();
}
}事實上利用普通的執行緒池也可以完成大量資料的並行運算程式碼如下:
/**
* 執行緒池的概念
* nasa
*/
package yxxy.c_026;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class T07_ParallelComputing {
public static void main(String[] args) throws InterruptedException, ExecutionException {
long start = System.currentTimeMillis();
List<Integer> results = getPrime(1, 200000);
long end = System.currentTimeMillis();
System.out.println(end - start);
final int cpuCoreNum = 4;
ExecutorService service = Executors.newFixedThreadPool(cpuCoreNum);
MyTask t1 = new MyTask(1, 80000); //1-5 5-10 10-15 15-20
MyTask t2 = new MyTask(80001, 130000);
MyTask t3 = new MyTask(130001, 170000);
MyTask t4 = new MyTask(170001, 200000);
Future<List<Integer>> f1 = service.submit(t1);
Future<List<Integer>> f2 = service.submit(t2);
Future<List<Integer>> f3 = service.submit(t3);
Future<List<Integer>> f4 = service.submit(t4);
start = System.currentTimeMillis();
f1.get();
f2.get();
f3.get();
f4.get();
end = System.currentTimeMillis();
System.out.println(end - start);
}
static class MyTask implements Callable<List<Integer>> {
int startPos, endPos;
MyTask(int s, int e) {
this.startPos = s;
this.endPos = e;
}
@Override
public List<Integer> call() throws Exception {
List<Integer> r = getPrime(startPos, endPos);
return r;
}
}
static boolean isPrime(int num) {
for(int i=2; i<=num/2; i++) {
if(num % i == 0) return false;
}
return true;
}
static List<Integer> getPrime(int start, int end) {
List<Integer> results = new ArrayList<>();
for(int i=start; i<=end; i++) {
if(isPrime(i)) results.add(i);
}
return results;
}
}這是一個質數計算的問題,我們把質數計算劃分為不同的資料段是因為越大的質數越難計算,所以直觀上計算大量的小數字的質數的時間相當於計算少量的大數字花的時間。這樣一來我們就將這個大的任務相對均勻的拆分開來避免了任務分配不均勻造成的等待(也就是時間浪費)。
執行緒池的底層實現
前四種執行緒池的底層原始碼如下:
ChchedThreadPool

FixedThreadPool

ScheduledPool
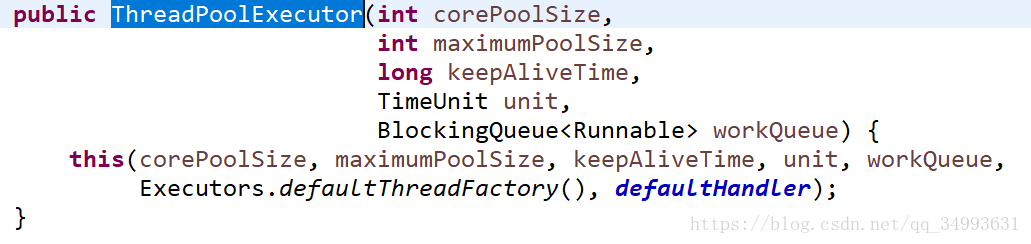
SingleThreadPool

我們會發現他們都是基於ThreadExecutor。
而WorkStealingPool與ForkJoinPool的底層都是ForkJoinPool。
最後感謝馬士兵老師,一個專心做教育的老師。