
GPU加速原理
原文:https://blog.csdn.net/weiweigfkd/article/details/23051255
GPU加速技術&原理介紹
1、GPU&CPU
GPU英文全稱Graphic Processing Unit,中文翻譯為“圖形處理器”。與CPU不同,GPU是專門為處理圖形任務而產生的晶片。從這個任務定位上面來說,不僅僅在計算機的顯示卡上面,在手機、遊戲機等等各種有多媒體處理需求的地方都可以見到GPU的身影。
在GPU出現之前,CPU一直負責著計算機中主要的運算工作,包括多媒體的處理工作。CPU的架構是有利於X86指令集的序列架構,CPU從設計思路上適合儘可能快的完成一個任務。但是如此設計的CPU在多媒體處理中的缺陷也顯而易見:多媒體計算通常要求較高的運算密度、多併發執行緒和頻繁地儲存器訪問,而由於X86平臺中CISC(Complex Instruction Set Computer)架構中暫存器數量有限,CPU並不適合處理這種型別的工作。以Intel為代表的廠商曾經做過許多改進的嘗試,從1999年開始為X86平臺連續推出了多媒體擴充套件指令集——SSE(Streaming SIMD Extensions)的一代到四代版本,但由於多媒體計算對於浮點運算和平行計算效率的高要求,CPU從硬體本身上就難以滿足其巨大的處理需求,僅僅在軟體層面的改並不能起到根本效果。
對於GPU來說,它的任務是在螢幕上合成顯示數百萬個畫素的影象——也就是同時擁有幾百萬個任務需要並行處理,因此GPU被設計成可並行處理很多工,而不是像CPU那樣完成單任務。
因此CPU和GPU架構差異很大,CPU功能模組很多,能適應複雜運算環境;GPU構成則相對簡單,目前流處理器和視訊記憶體控制器佔據了絕大部分電晶體。CPU中大部分電晶體主要用於構建控制電路(比如分支預測等)和Cache,只有少部分的電晶體來完成實際的運算工作。而GPU的控制相對簡單,且對Cache的需求小,所以大部分電晶體可以組成各類專用電路、多條流水線,使得GPU的計算速度有了突破性的飛躍,擁有了更強大的處理浮點運算的能力。
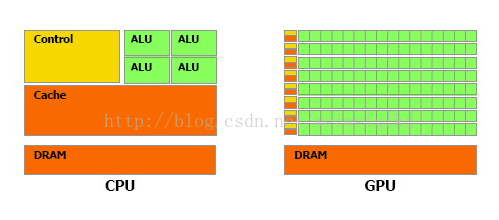
圖1:CPU和GPU架構
隨著計算機多媒體計算需求的持續發展,1999年Nvidia向市場推出了史上第一款GPU:Geforece 256(圖2)。開啟了GPU計算的歷史。

圖2:Nvidia Geforce256
2、GPU加速的原理
GPU一推出就包含了比CPU更多的處理單元,更大的頻寬,使得其在多媒體處理過程中能夠發揮更大的效能。例如:當前最頂級的CPU只有4核或者6核,模擬出8個或者12個處理執行緒來進行運算,但是普通級別的GPU就包含了成百上千個處理單元,高階的甚至更多,這對於多媒體計算中大量的重複處理過程有著天生的優勢。下圖展示了CPU和GPU架構的對比。
圖3:CPU和GPU對比
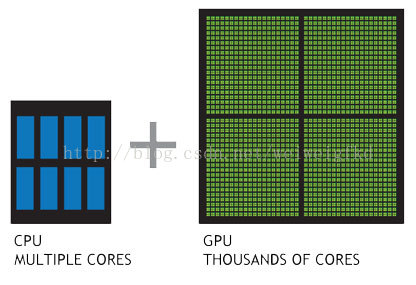
從硬體設計上來講,CPU 由專為順序序列處理而優化的幾個核心組成。另一方面,GPU 則由數以千計的更小、更高效的核心組成,這些核心專為同時處理多工而設計。
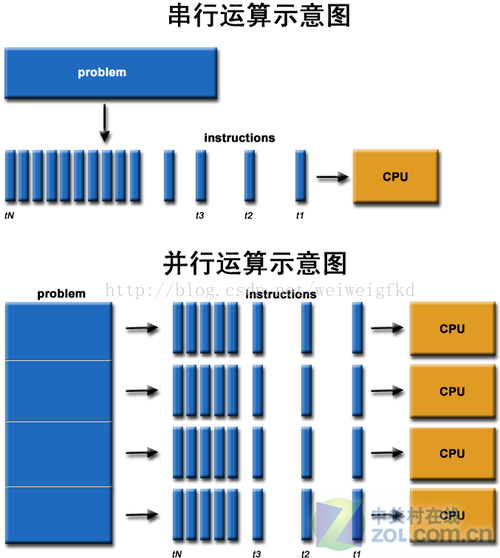
圖4:序列和平行計算
通過上圖我們可以較為容易地理解序列運算和並行運算之間的區別。傳統的序列編寫軟體具備以下幾個特點:要執行在一個單一的具有單一中央處理器(CPU)的計算機上;一個問題分解成一系列離散的指令;指令必須一個接著一個執行;只有一條指令可以在任何時刻執行。而平行計算則改進了很多重要細節:要使用多個處理器執行;一個問題可以分解成可同時解決的離散指令;每個部分進一步細分為一系列指示;每個部分的問題可以同時在不同處理器上執行。
舉個生活中的例子來說,你要點一份餐館的外賣,CPU型餐館用一輛大貨車送貨,每次可以拉很多外賣,但是送完一家才能到下一家送貨,每個人收到外賣的時間必然很長;而GPU型餐館用十輛小摩托車送貨,每輛車送出去的不多,但是並行處理的效率高,點餐之後收貨就會比大貨車快很多。
下面一段視訊也直觀地展示了CPU和GPU處理效率上的區別。
http://v.youku.com/v_show/id_XNjY3MTY4NjAw.html
在1999年Nvidia推出Geforce的同時,還提出了GPGPU(GeneralPurpose GPU)的概念,即基於GPU的通用計算。CPU 包含幾個專為序列處理而優化的核心,而 GPU 則由數以千計更小、更節能的核心組成,這些核心專為提供強勁的並行效能而設計。程式的序列部分在 CPU 上執行,而並行部分則在 GPU上執行。如此一來,能夠最大程度地提高程式執行的效率。這就是GPU加速的基本思想。
3、GPU加速技術
當前CPU發展速度已經落後於摩爾定律,而GPU正以超過摩爾定律的速度快速發展。
在SIGGRAPH2003大會上,許多業界泰斗級人物發表了關於利用GPU進行各種運算的設想和實驗模型。SIGGRAPH會議還特地安排了時間進行GPGPU的研討交流。與此同時,在計算機進入DirectX 9 Shader Model 3.0時代,新的Shader Model在指令槽、流控制方面的顯著增強使得對應GPU的可程式設計效能得到了大大的提升。GPGPU的研究由此進入快車道。
下面對幾個值得關注的技術做簡單介紹。
CUDA
為充分利用GPU的計算能力,NVIDIA在2006年推出了CUDA(ComputeUnified Device Architecture,統一計算裝置架構)這一程式設計模型。CUDA是一種由NVIDIA推出的通用平行計算架構,該架構使GPU能夠解決複雜的計算問題。它包含了CUDA指令集架構(ISA)以及GPU內部的平行計算引擎。開發人員現在可以使用C語言來為CUDA架構編寫程式。
通過這個技術,使用者可利用NVIDIA的GeForce 8以後的GPU和較新的QuadroGPU進行計算。以GeForce 8800 GTX為例,其核心擁有128個內處理器。利用CUDA技術,就可以將那些內處理器串通起來,成為執行緒處理器去解決資料密集的計算。而各個內處理器能夠交換、同步和共享資料。
從CUDA體系結構的組成來說,包含了三個部分:開發庫、執行期環境和驅動。
開發庫是基於CUDA技術所提供的應用開發庫。CUDA的1.1版提供了兩個標準的數學運算庫——CUFFT(離散快速傅立葉變換)和CUBLAS(離散基本線性計算)的實現。這兩個數學運算庫所解決的是典型的大規模的平行計算問題,也是在密集資料計算中非常常見的計算型別。開發人員在開發庫的基礎上可以快速、方便的建立起自己的計算應用。此外,開發人員也可以在CUDA的技術基礎上實現出更多的開發庫。
執行期環境提供了應用開發介面和執行期元件,包括基本資料型別的定義和各類計算、型別轉換、記憶體管理、裝置訪問和執行排程等函式。基於CUDA開發的程式程式碼在實際執行中分為兩種,一種是執行在CPU上的宿主程式碼(Host Code),一種是執行在GPU上的裝置程式碼(Device Code)。不同型別的程式碼由於其執行的物理位置不同,能夠訪問到的資源不同,因此對應的執行期元件也分為公共元件、宿主元件和裝置元件三個部分,基本上囊括了所有在GPGPU開發中所需要的功能和能夠使用到的資源介面,開發人員可以通過執行期環境的程式設計介面實現各種型別的計算。
由於目前存在著多種GPU版本的NVIDIA顯示卡,不同版本的GPU之間都有不同的差異,因此驅動部分基本上可以理解為是CUDA-enable的GPU的裝置抽象層,提供硬體裝置的抽象訪問介面。CUDA提供執行期環境也是通過這一層來實現各種功能的。由於體系結構中硬體抽象層的存在,CUDA今後也有可能發展成為一個通用的GPGPU標準介面,相容不同廠商的GPU產品
OpenCL
OpenCL是Open Computing Language(開放式計算語言)的簡稱,它是第一個為異構系統的通用並行程式設計而產生的統一的、免費的標準。OpenCL最早由蘋果公司研發,其規範是由Khronos Group推出的。OpenCL支援由多核的CPU、GPU、Cell型別架構以及訊號處理器(DSP)等其他的並行裝置組成的異構系統。OpenCL的出現,使得軟體開發人員編寫高效能伺服器、桌面計算系統以及手持裝置的程式碼變得更加快捷。
OpenCL是一個為異構平臺編寫程式的框架,此異構平臺可由CPU,GPU或其他型別的處理器組成。OpenCL由一門用於編寫kernels (在OpenCL裝置上執行的函式)的語言(基於C99)和一組用於定義並控制平臺的API組成。其框架如下:
OpenCL平臺API:平臺API定義了宿主機程式發現OpenCL裝置所用的函式以及這些函式的功能,另外還定義了為OpenCL應用建立上下文的函式。
OpenCL執行時API:這個API管理上下文來建立命令佇列以及執行時發生的其他操作。例如,將命令提交到命令佇列的函式就來自OpenCL執行時API。
OpenCL程式語言:這是用來編寫核心程式碼的程式語言。它基於ISO C99標準的一個擴充套件子集,因此通常稱為OpenCL C程式語言。
OpenCL由用於編寫核心程式的語言和定義並控制平臺的API組成,提供了基於任務和基於資料的兩種平行計算機制,使得GPU的計算不在僅僅侷限於圖形領域,而能夠進行更多的平行計算。OpenCL還是一個開放的工業標準,它可以為CPU和GPU等不同的裝置組成的異構平臺進行程式設計。OpenCL是一種語言,也是一個為並行程式設計而提供的框架,程式設計人員可以利用OpenCL編寫出一個能夠在GPU上執行的通用程式。在遊戲、娛樂、科研、醫療等各種領域都有廣闊的發展前景。
AMD Fusion
與Nvidia不同,AMD走了一條全新的路子:將CPU和GPU融為一體,打造了AMDFusion,即APU(Accelerated Processing Units)。這是AMD融聚未來理念的產品,它第一次將處理器和獨顯核心做在一個晶片上,協同計算、彼此加速,同時具有高效能處理器和最新支援DX11獨立顯示卡的處理效能,大幅提升電腦執行效率,實現了CPU與GPU真正的融合。與傳統的x86中央處理器相比, APU提出了“異構系統架構”(Heterogeneous System Architecture,HSA),即單晶片上兩個不同的架構進行協同運作。以往整合圖形核心一般是內置於主機板的北橋中。而AMD Fusion專案則是結合現時的處理器和繪圖核心,即是將處理一般事務的CPU核心、處理3D幾何任務以及圖形核心之擴充套件功能的現代GPU核心、以及主機板的北橋融合到一塊晶片上。這種設計允許一些應用程式或其相關連結介面來呼叫圖形處理器來加速處理程序,例如OpenCL。
未來AMD將會在AMD APU上實現儲存器統一定址空間,使CPU和GPU進一步結合。最終的目標是要將圖形處理器和中央處理器“深度整合”、“完全融合”,可根據任務型別自動分配運算任務予不同的運算單元中。
目前計算機業界認為,類似的統合技術將是未來處理器的一個主要發展方向。
4、GPU加速應用
BOINC平臺的GPU加速專案
BOINC的中文全稱是伯克利開放式網路計算平臺(Berkeley Open Infrastructure for Network Computing),他能夠把許多不同的分散式計算專案聯絡起來統一管理。並對計算機資源進行統一分配。BOINC目前已經成熟,多個專案已經成功運行於BOINC平臺之上,如[email protected]、[email protected]、[email protected] 、World Community Grid世界公共網格等。
圖5:BOINC分散式計算平臺
[email protected]是一個基於 BOINC 平臺的分散式運算專案。專案試圖精確構建銀河系附近星流的三維動態模型。專案的另一個目標是開發並優化分散式計算的演算法。該專案在今年年初已經匯聚了超過1PetaFlops運算能力,運算速度超過了世界上第二快的超級計算機,該專案在推出後不久就提供了支援ATI顯示卡的運算程式。
圖6:[email protected]專案模擬
[email protected]這個專案折射到計算機硬體方面,實際上就是畫素對比,是對比進化演算法得來的銀河系演進圖與真實拍得的照片的差異。它是按照進化演算法先驗算一個銀河系在某時間斷面的圖,然後拿這個圖跟拍攝的實際照片進行對比。[email protected]雖然是研究天體的專案,但這種研究演算法天生具有遺傳演算法的特性,其主要特點是直接對結構物件進行操作,不存在求導和函式連續性的限定;[email protected]提供的ATI顯示卡計算任務具有內在的隱並行性和更好的全域性尋優能力,這個專案裡更多的也不是分支巢狀,而是把算好的結果跟已知的觀測結果進行比對,這樣ATI GPU架構吞吐量巨大的優勢就能夠很好體現了。
另一個活躍在BOINC平臺上的支援GPU計算的專案是CollatzConjecture,這是一個利用聯網計算機進行數學方面研究,特別是測試又稱為3X+1或者HOTPO(取半或乘三加一)的考拉茲猜想的研究專案。該專案的運算目的很簡單,變數只有一個n,如果它是奇數,則對它乘3再加1,如果它是偶數,則對它除以2,如此迴圈,最終都能夠得到1。這個專案的研究目標就是尋找最大的質數。
該專案的主程式分支出現在初始段,而且所有的執行緒的分支幾乎都是統一的,所以對於分支能力的考驗是比較少的,反而它能夠使幾乎所有執行緒都同步進行這個相對簡單的吞吐過程。這就決定了該專案上ATI GPU的運算速度要比NVIDIA GPU快,因為ATI所提供的硬體結構更適應於這種資料結構。
最具影響力的[email protected]專案
[email protected]是一個研究蛋白質摺疊,誤折,聚合及由此引起的相關疾病的分散式計算專案。我們使用聯網式的計算方式和大量的分散式計算能力來模擬蛋白質摺疊的過程,並指引我們近期對由摺疊引起的疾病的一系列研究,找到相關疾病的發病原因和治療方法。
[email protected]能瞭解蛋白質摺疊、誤折以及相關的疾病。目前進行中的研究有:癌症、阿茲海默症(老年失智症)、亨廷頓病、成骨不全症、帕金森氏症、核糖體與抗生素。
圖7:不同硬體為[email protected]專案提供的運算能力
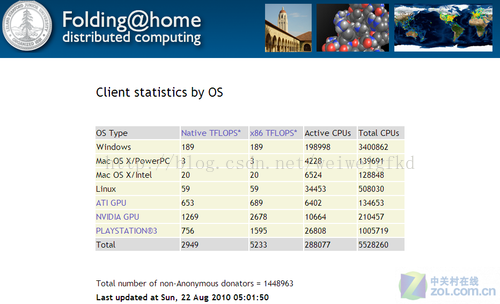
您可以在斯坦福大學官方網頁上下載並執行客戶端程式,隨著更多志願者的計算機加入,此專案計算的速度就越快,就會計算出蛋白質在更長時間內的摺疊,距離科學家找到最終答案也就越來越近。如果蛋白質沒有正確地摺疊將會使人得一些病症:如阿茲海默氏症(Alzheimers)、囊腫纖維化(Cystic fibrosis)、瘋牛病(Mad Cow, BSE)等, 甚至許多癌症的起因都是蛋白質的非正常摺疊。
[email protected]所研究的是人類最基本的特定致病過程中蛋白質分子的摺疊運動。專案的核心原理在於求解任務目標分子中每一個原子在邊界條件限制下由肽鍵和長程力等作用所導致的運動方程,進而達到實現模擬任務目標分子摺疊運動的目的。每一個原子背後都附庸這若干個方程,每一個方程都可以轉換成一組簡單的向量指令。同時由於長程力的影響,條件分支也隨處可見,[email protected]在GPU使用量上也要大於圖形程式設計。
圖8:在分子動力學領域廣泛使用的GROMACS引擎
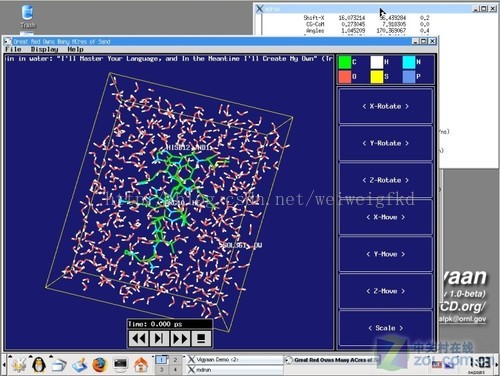
由於針對不同的系統其程式碼進行了高度優化,GROMACS是目前最快的分子動力學模擬軟體。此外,由於支援不同的分子力場以及按照GPL協議發行,GROMACS擁有很高的可定製性。GROMACS目前最新版本為4.07,可以到官方網站下載並自行編譯。GROMACS支援並行/網格計算擴充套件,可靈活搭配MPI規範的並行運算介面,如MPICH、MPICH2、MPILAM、DeoinMPI等。國內也有很多分子動力專業人員同樣使用GROMACS做研究,GROMACS幾乎成為模擬蛋白質摺疊領域內的標準。
2006年9月底,ATI宣佈了通用計算GPGPU架構,並得到了斯坦福大學[email protected]專案的大力支援,加入了人類健康研究。2007年3月22日,PS3正式加入史丹佛大學分散式運算研究計劃,至今已有超過百萬名 PS3 玩家註冊參與。NVIDIA於2008年6月宣佈旗下基於G80及以上核心的顯示卡產品都支援該專案的通用計算,更是對分散式計算的重要貢獻。
圖9:Radeon HD4870顯示卡正在執行[email protected]專案
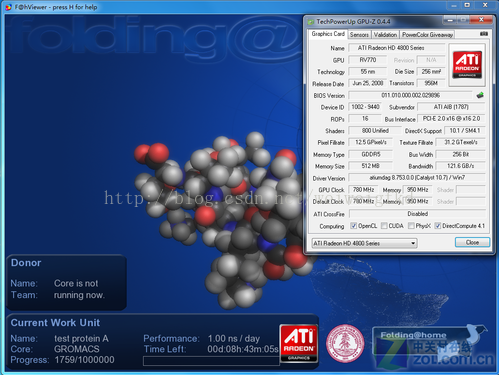
[email protected]在自身定位明確、成功發展的基礎下,通過斯坦福大學的大力推廣,已經獲得了全世界廣泛認同。而近期PS3和GPU的參與更是將[email protected]的運算能力推向高峰。值得一提的是NVIDIA在2008年6月果斷宣佈加入[email protected]專案,至今已經為該專案提供了超過2 PFlops運算能力。
目前[email protected]已經成為全世界最有影響力和公信力的專案,同時是各大廠商和機構鼎力支援的專案,當然它毫無疑問地擁有最廣大的志願者團隊——截止2010年4月18日,全球共計1,396,683人蔘與該專案,最近的統計顯示志願者貢獻的總運算能力已經達到了5PFlops,遠超現在全世界最快的超級計算機。
該專案在中國擁有約2000多名參與者,其中最強大的[email protected] Power([email protected]中國力量,團隊編號3213)團隊已經擁有2585人,最近活躍使用者200人以上,目前貢獻計算量排名世界第47位,團隊整體運算能力約為50到100TFLOPS。
GPU架構對於其他例項的適應性
前文提到的幾種GPU計算專案,都是一些非常直接具體的科學計算專案,它們是使用者直接體會GPU計算的最簡單途徑。除此之外,還有大量例項可以在GPU上完成運算,特別是ATI提供的這種硬體架構可以在一些特殊運算中獲得極高的加速比。
比如對於那些很難解決或者不可能精確求解的問題,蒙特卡洛演算法提供了一種近似的數值解決方法。蒙特卡洛模擬與生俱來的特徵就是多次獨立重複實驗的使用,每次獨立實驗都有某些隨機數驅動。根據大數定律,組合的實驗次數越多,最後得到的平均答案就越接近於真實的答案。每次重複實驗天生就具有較強的並行特徵,而且它們通常由密集數操作組成,因此GPU幾乎為蒙特卡洛模擬提供了一個完美的平臺。
第二個要介紹的例子是使用GPU進行Nbody模擬。它在數值上近似地表示一個多體系統的演化過程,該系統中的一個體(Body)都持續地與所有其他的體相互作用。一個相似的例子是天體物理學模擬,在該模擬中,每個體代表一個星系或者一個獨立執行的星系,各個體之間通過萬有引力相互吸引,如圖所示。在很多其他電腦科學問題中也會用到N-body模擬,例如蛋白質摺疊就用到Nbody模擬計算靜電荷範德華力。其他使用Nbody模擬的例子還有湍流流場模擬與全域性光照計算等計算機圖形學中的問題。
圖10:DirectX 11 SDK Nbody Gravity測試專案
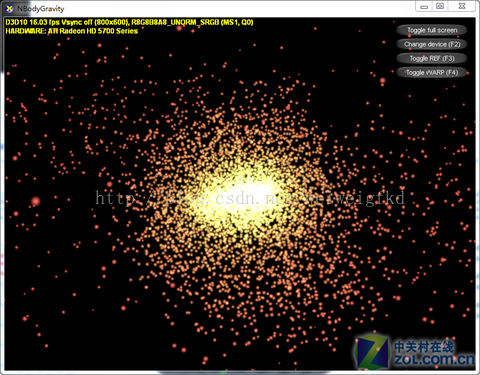
Nbody模擬問題的研究貫穿了整個計算科學的歷史。在20世紀80年代,研究人員引進了分層和網格型別的演算法,成功降低了計算複雜度。自從出現了平行計算機,Nbody模擬的並行化也開始被研究了。同時從CPU到GPU的現有研究成果不僅僅是為了降低運算的功耗,還可以降低分層度,節省遠域計算的時間。
N Body Gravity測試具備兩個顯著的特點,首先是高並行度,該測試擁有大量相互碰撞的粒子,粒子之間會產生複雜而又數量較多的力量變化。同時該測試擁有較高的運算密度,GPU在處理此類問題時可以有效展現其強大的並行運算能力。在NVIDIA最初G80架構的Geforce 8800GTX GPU上每秒可以計算100多億個引力系統的效能,這個成績是一個經過高度優化的CPU實現的效能的50多倍。
圖10:利用開源的防毒軟體ClamAV來基於GPU進行病毒檢測
GPU還可以作為一個高速過濾器,來檢驗計算機病毒,這一原理和[email protected]專案的畫素對比有異曲同工之處。作為一個並行資料處理器,GPU擅長於處理那些具有常規的、固定大小的輸入輸出資料集合的演算法任務。因為通過讓CPU處理變長的和序列的任務,而GPU處理並行度較高的任務,可以最大限度地利用GPU進行病毒檢測。GPU可以使用很少的位元組來確定是否可能與資料庫中的某個特徵匹配,然後GPU再確認所有的匹配。