
深入理解 Kafka Connect:轉換器和序列化
原文連結:https://blog.csdn.net/D55dffdh/article/details/82423831
AI 前線導讀:Kafka Connect 是一個簡單但功能強大的工具,可用於 Kafka 和其他系統之間的整合。人們對 Kafka Connect 最常見的誤解之一是它的轉換器。這篇文章將告訴我們如何正確地使用訊息的序列化格式,以及如何在 Kafka Connect 聯結器中對其進行標準化。
Kafka Connect 是 Apache Kafka 的一部分,為其他資料儲存和 Kafka 提供流式整合。對於資料工程師來說,他們只需要配置一下 JSON 檔案就可以了。Kafka 提供了一些可用於常見資料儲存的聯結器,如 JDBC、Elasticsearch、IBM MQ、S3 和 BigQuery,等等。
對於開發人員來說,Kafka Connect 提供了豐富的 API,如果有必要還可以開發其他聯結器。除此之外,它還提供了用於配置和管理聯結器的 REST API。
Kafka Connect 是一種模組化元件,提供了一種非常強大的整合方法。一些關鍵元件包括:
- 聯結器——定義如何與資料儲存整合的 JAR 檔案;
- 轉換器——處理資料的序列化和反序列化;
- 變換——可選的執行時訊息操作。
人們對 Kafka Connect 最常見的誤解與資料的序列化有關。Kafka Connect 使用轉換器處理資料序列化。接下來讓我們看看它們是如何工作的,並說明如何解決一些常見問題。
Kafka 訊息都是位元組
Kafka 訊息被儲存在主題中,每條訊息就是一個鍵值對。當它們儲存在 Kafka 中時,鍵和值都只是位元組。Kafka 因此可以適用於各種場景,但這也意味著開發人員需要決定如何序列化資料。
在配置 Kafka Connect 時,序列化格式是最關鍵的配置選項之一。你需要確保從主題讀取資料時使用的序列化格式與寫入主題的序列化格式相同,否則就會出現混亂和錯誤!
序列化格式有很多種,常見的包括:
- JSON;
- Avro;
- Protobuf;
- 字串分隔(如 CSV)。
選擇序列化格式
選擇序列化格式的一些指導原則:
- schema。很多時候,你的資料都有對應的 schema。你可能不喜歡,但作為開發人員,你有責任保留和傳播 schema。schema 為服務之間提供了一種契約。某些訊息格式(例如 Avro 和 Protobuf)具有強大的 schema 支援,而其他訊息格式支援較少(JSON)或根本沒有(CVS)。
- 生態系統相容性。Avro 是 Confluent 平臺的一等公民,擁有來自 Confluent Schema Registry、Kafka Connect、KSQL 的原生支援。另一方面,Protobuf 依賴社群為部分功能提供支援。
- 訊息大小。JSON 是純文字的,並且依賴了 Kafka 本身的壓縮機制,Avro 和 Protobuf 都是二進位制格式,序列化的訊息體積更小。
- 語言支援。Avro 在 Java 領域得到了強大的支援,但如果你的公司不是基於 Java 的,那麼可能會覺得它不太好用。
如果目標系統使用 JSON,Kafka 主題也必須使用 JSON 嗎?
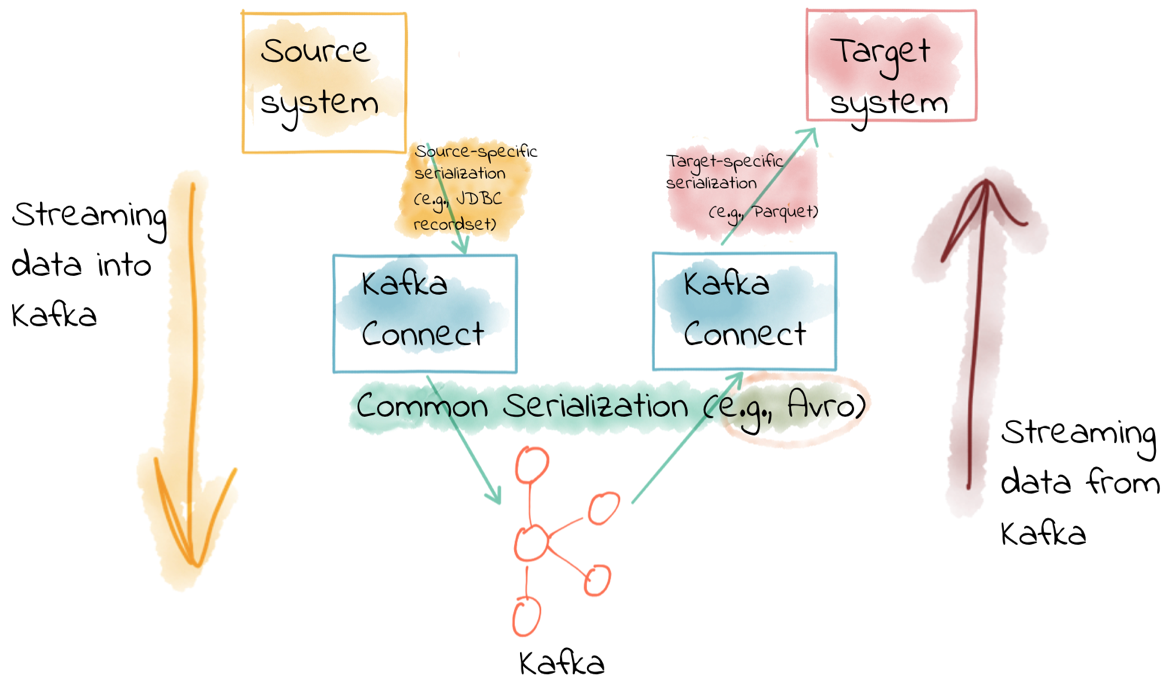
完全不需要這樣。從資料來源讀取資料或將資料寫入外部資料儲存的格式不需要與 Kafka 訊息的序列化格式一樣。
Kafka Connect 中的聯結器負責從源資料儲存(例如資料庫)獲取資料,並以資料內部表示將資料傳給轉換器。然後,Kafka Connect 的轉換器將這些源資料物件序列化到主題上。
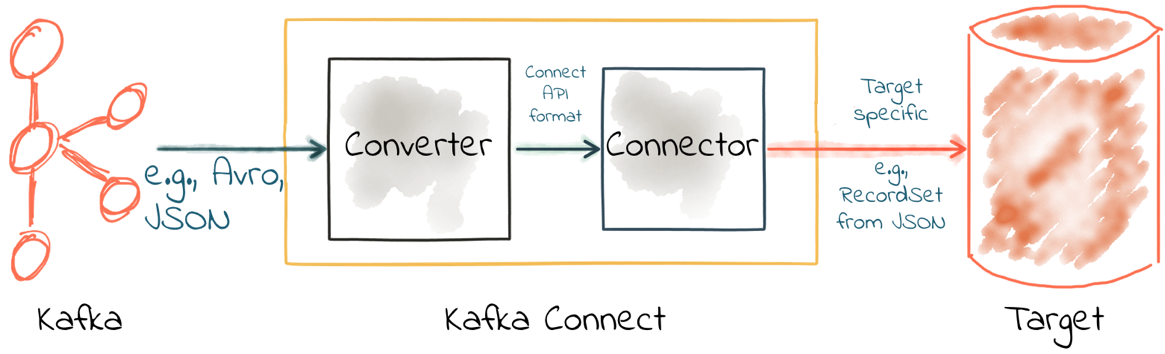
在使用 Kafka Connect 作為接收器時剛好相反——轉換器將來自主題的資料反序列化為內部表示,傳給聯結器,以便能夠使用特定於目標的適當方法將資料寫入目標資料儲存。
也就是說,主題資料可以是 Avro 格式,當你將資料寫入 HDFS 時,指定接收器的聯結器使用 HDFS 支援的格式即可。
配置轉換器
Kafka Connect 預設使用了 worker 級別的轉換器配置,聯結器可以對其進行覆蓋。由於在整個管道中使用相同的序列化格式通常會更好,所以一般只需要在 worker 級別設定轉換器,而不需要在聯結器中指定。但你可能需要從別人的主題拉取資料,而他們使了用不同的序列化格式——對於這種情況,你需要在聯結器配置中設定轉換器。即使你在聯結器的配置中進行了覆蓋,它仍然是執行實際任務的轉換器。
好的聯結器一般不會序列化或反序列化儲存在 Kafka 中的訊息,它會讓轉換器完成這項工作。
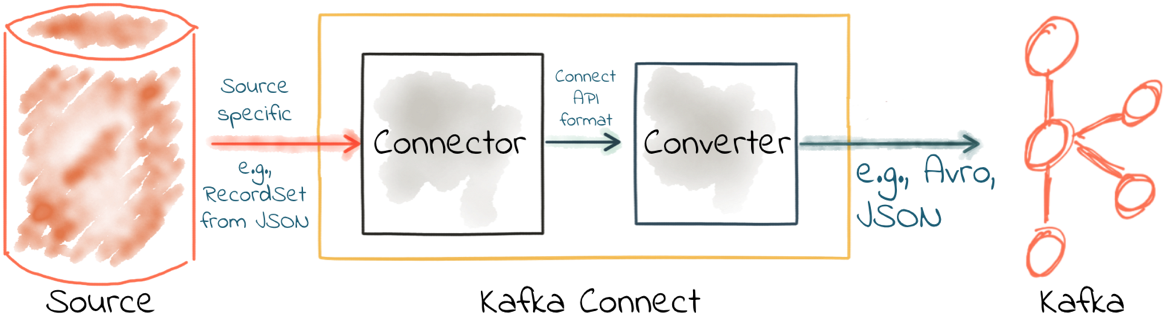
請記住,Kafka 訊息是鍵值對位元組,你需要使用 key.converter 和 value.converter 為鍵和值指定轉換器。在某些情況下,你可以為鍵和值使用不同的轉換器。
這是使用 String 轉換器的一個示例。
複製程式碼
|
|
有些轉換器有一些額外的配置。對於 Avro,你需要指定 Schema Registry。對於 JSON,你需要指定是否希望 Kafka Connect 將 schema 嵌入到 JSON 訊息中。在指定特定於轉換器的配置時,請始終使用 key.converter. 或 value.converter. 字首。例如,要將 Avro 用於訊息載荷,你需要指定以下內容:
複製程式碼
|
|
|
|
|
常見的轉換器包括:
- Avro——來自 Confluent 的開源專案
複製程式碼
|
|
- String——Apache Kafka 的一部分
複製程式碼
|
|
- JSON——Apache Kafka 的一部分
複製程式碼
|
|
- ByteArray——Apache Kafka 的一部分
複製程式碼
|
|
- Protobuf——來自社群的開源專案
複製程式碼
|
|
JSON 和 schema
雖然 JSON 預設不支援嵌入 schema,但 Kafka Connect 提供了一種可以將 schema 嵌入到訊息中的特定 JSON 格式。由於 schema 被包含在訊息中,因此生成的訊息大小可能會變大。
如果你正在設定 Kafka Connect 源,並希望 Kafka Connect 在寫入 Kafka 訊息包含 schema,可以這樣:
複製程式碼
|
|
|
|
|
生成的 Kafka 訊息看起來像下面這樣,其中包含 schema 和 payload 節點元素:
複製程式碼
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
請注意訊息的大小,訊息由 playload 和 schema 組成。每條訊息中都會重複這些資料,這也就是為什麼說 Avro 這樣的格式會更好,因為它的 schema 是單獨儲存的,訊息中只包含載荷(並進行了壓縮)。
如果你正在使用 Kafka Connect 消費 Kafka 主題中的 JSON 資料,那麼就需要知道資料是否包含了 schema。如果包含了,並且它的格式與上述的格式相同,那麼你可以這樣設定:
複製程式碼
|
|
|
|
|
不過,如果你正在消費的 JSON 資料如果沒有 schema 加 payload 這樣的結構,例如:
複製程式碼
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
那麼你必須通過設定 schemas.enable = false 告訴 Kafka Connect 不要查詢 schema:
複製程式碼
|
|
|
|
|
和之前一樣,轉換器配置選項(這裡是 schemas.enable)需要使用字首 key.converter 或 value.converter。
常見錯誤
如果你錯誤地配置了轉換器,將會遇到以下的一些常見錯誤。這些訊息將顯示在你為 Kafka Connect 配置的接收器中,因為你試圖在接收器中反序列化 Kafka 訊息。這些錯誤會導致聯結器失敗,主要錯誤訊息如下所示:
複製程式碼
|
|
|
|
|
|
|
|
|
|
|
在錯誤訊息的後面,你將看到堆疊資訊,描述了發生錯誤的原因。請注意,對於聯結器中的任何致命錯誤,都會丟擲上述異常,因此你可能會看到與序列化無關的錯誤。要快速檢視錯誤配置可能會導致的錯誤,請參考下表:

問題:使用 JsonConverter 讀取非 JSON 資料
如果你的源主題上有非 JSON 資料,但嘗試使用 JsonConverter 讀取它,你將看到:
複製程式碼
|
|
|
|
|
|
|
|
這有可能是因為源主題使用了 Avro 或其他格式。
解決方案:如果資料是 Avro 格式的,那麼將 Kafka Connect 接收器的配置改為:
複製程式碼
|
|
|
|
|
或者,如果主題資料是通過 Kafka Connect 填充的,那麼你也可以這麼做,讓上游源也傳送 JSON 資料:
複製程式碼
|
|
|
|
|
問題:使用 AvroConverter 讀取非 Avro 資料
這可能是我在 Confluent Community 郵件組和 Slack 組等地方經常看到的錯誤。當你嘗試使用 Avro 轉換器從非 Avro 主題讀取資料時,就會發生這種情況。這包括使用 Avro 序列化器而不是 Confluent Schema Registry 的 Avro 序列化器(它有自己的格式)寫入的資料。
複製程式碼
|
|
|
|
|
|
|
|
|
|
|
|
|
|
解決方案:檢查源主題的序列化格式,修改 Kafka Connect 接收器聯結器,讓它使用正確的轉換器,或將上游格式切換為 Avro。如果上游主題是通過 Kafka Connect 填充的,則可以按如下方式配置源聯結器的轉換器:
複製程式碼
|
|
|
|
|
問題:沒有使用預期的 schema/payload 結構讀取 JSON 訊息
如前所述,Kafka Connect 支援包含載荷和 schema 的 JSON 訊息。如果你嘗試讀取不包含這種結構的 JSON 資料,你將收到這個錯誤:
複製程式碼
|
|
需要說明的是,當 schemas.enable=true 時,唯一有效的 JSON 結構需要包含 schema 和 payload 這兩個頂級元素(如上所示)。
如果你只有簡單的 JSON 資料,則應將聯結器的配置改為:
複製程式碼
|
|
|
|
|
如果要在資料中包含 schema,可以使用 Avro(推薦),也可以修改上游的 Kafka Connect 配置,讓它在訊息中包含 schema:
複製程式碼
|
|
|
|
|
故障排除技巧
檢視 Kafka Connect 日誌
要在 Kafka Connect 中查詢錯誤日誌,你需要找到 Kafka Connect 工作程式的輸出。這個位置取決於你是如何啟動 Kafka Connect 的。有幾種方法可用於安裝 Kafka Connect,包括 Docker、Confluent CLI、systemd 和手動下載壓縮包。你可以這樣查詢日誌的位置:
- Docker:docker logs container_name;
- Confluent CLI:confluent log connect;
- systemd:日誌檔案在 /var/log/confluent/kafka-connect;
- 其他:預設情況下,Kafka Connect 將其輸出傳送到 stdout,因此你可以在啟動 Kafka Connect 的終端中找到它們。
檢視 Kafka Connect 配置檔案
- Docker——設定環境變數,例如在 Docker Compose 中:
複製程式碼
|
|
|
|
|
|
|
|
|
|
|
- Confluent CLI——使用配置檔案 etc/schema-registry/connect-avro-distributed.properties;
- systemd(deb/rpm)——使用配置檔案 /etc/kafka/connect-distributed.properties;
- 其他——在啟動 Kafka Connect 時指定工作程式的屬性檔案,例如:
複製程式碼
|
|
|
|
|
檢查 Kafka 主題
假設我們遇到了上述當中的一個錯誤,並且想要解決 Kafka Connect 接收器無法從主題讀取資料的問題。
我們需要檢查正在被讀取的資料,並確保它使用了正確的序列化格式。另外,所有訊息都必須使用這種格式,所以不要假設你現在正在以正確的格式向主題傳送訊息就不會出問題。Kafka Connect 和其他消費者也會從主題上讀取已有的訊息。
下面,我將使用命令列進行故障排除,當然也可以使用其他的一些工具:
- Confluent Control Center 提供了視覺化檢查主題內容的功能;
- KSQL 的 PRINT 命令將主題的內容列印到控制檯;
- Confluent CLI 工具提供了 consume 命令,可用於讀取字串和 Avro 資料。
如果你的資料是字串或 JSON 格式
你可以使用控制檯工具,包括 kafkacat 和 kafka-console-consumer。我個人的偏好是使用 kafkacat:
複製程式碼
|
|
|
|
|
你也可以使用 jq 驗證和格式化 JSON:
複製程式碼
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
如果你得到一些“奇怪的”字元,你檢視的很可能是二進位制資料,這些資料是通過 Avro 或 Protobuf 寫入的:
複製程式碼
|
|
|
|
|
如果你的資料是 Avro 格式
你應該使用專為讀取和反序列化 Avro 資料而設計的控制檯工具。我使用的是 kafka-avro-console-consumer。確保指定了正確的 Schema Registry URL:
複製程式碼
|
|
|
|
|
|
|
|
|
|
|
|
|
|
和之前一樣,如果要格式化,可以使用 jq:
複製程式碼
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
內部轉換器
在分散式模式下執行時,Kafka Connect 使用 Kafka 來儲存有關其操作的元資料,包括聯結器配置、偏移量等。
可以通過 internal.key.converter/internal.value.converter 讓這些 Kafka 使用不同的轉換器。不過這些設定只在內部使用,實際上從 Apache Kafka 2.0 開始就已被棄用。你不應該更改這些配置,從 Apache Kafka 2.0 版開始,如果你這麼做了將會收到警告。
將 schema 應用於沒有 schema 的訊息
很多時候,Kafka Connect 會從已經存在 schema 的地方引入資料,並使用合適的序列化格式(例如 Avro)來保留這些 schema。然後,這些資料的所有下游使用者都可以使用這些 schema。但如果沒有提供顯式的 schema 該怎麼辦?
或許你正在使用 FileSourceConnector 從普通檔案中讀取資料(不建議用於生產環境中,但可用於 PoC),或者正在使用 REST 聯結器從 REST 端點提取資料。由於它們都沒有提供 schema,因此你需要宣告它。
有時候你只想傳遞你從源讀取的位元組,並將它們儲存在一個主題上。但大多數情況下,你需要 schema 來使用這些資料。在攝取時應用一次 schema,而不是將問題推到每個消費者,這才是一種更好的處理方式。
你可以編寫自己的 Kafka Streams 應用程式,將 schema 應用於 Kafka 主題中的資料上,當然你也可以使用 KSQL。下面讓我們來看一下將 schema 應用於某些 CSV 資料的簡單示例。
假設我們有一個 Kafka 主題 testdata-csv,儲存著一些 CSV 資料,看起來像這樣:
複製程式碼
|
|
|
|
|
|
|
|
我們可以猜測它有三個欄位,可能是:
- ID
- Artist
- Song
如果我們將資料保留在這樣的主題中,那麼任何想要使用這些資料的應用程式——無論是 Kafka Connect 接收器還是自定義的 Kafka 應用程式——每次都需要都猜測它們的 schema 是什麼。或者,每個消費應用程式的開發人員都需要向提供資料的團隊確認 schema 是否發生變更。正如 Kafka 可以解耦系統一樣,這種 schema 依賴讓團隊之間也有了硬性耦合,這並不是一件好事。
因此,我們要做的是使用 KSQL 將 schema 應用於資料上,並使用一個新的派生主題來儲存 schema。這樣你就可以通過 KSQL 檢查主題資料:
複製程式碼
|
|
|
|
|
|
|
|
|
|
|
前兩個欄位(11/6/18 2:41:23 PM UTC 和 NULL)分別是 Kafka 訊息的時間戳和鍵。其餘欄位來自 CSV 檔案。現在讓我們用 KSQL 註冊這個主題並宣告 schema:
複製程式碼
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
可以看到,KSQL 現在有一個數據流 schema:
複製程式碼
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
可以通過查詢 KSQL 流來檢查資料是否符合預期。請注意,這個時候我們只是作為現有 Kafka 主題的消費者——並沒有更改或複製任何資料。
複製程式碼
|
|
|
|
|
|
|
|
|
|
|
|
|
|
最後,建立一個新的 Kafka 主題,使用帶有 schema 的資料進行填充。KSQL 查詢是持續的,因此除了將現有的資料從源主題傳送到目標主題之外,KSQL 還將向目標主題傳送未來將生成的資料。
複製程式碼
|
|
|
|
|
|
|
|
|
|
|
|
|
|
使用 Avro 控制檯消費者驗證資料:
複製程式碼
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
你甚至可以在 Schema Registry 中檢視已註冊的 schema:
複製程式碼
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
寫入原始主題(testdata-csv)的任何新訊息都由 KSQL 自動處理,並以 Avro 格式寫入新的 TESTDATA 主題。現在,任何想要使用這些資料的應用程式或團隊都可以使用 TESTDATA 主題。你還可以更改主題的分割槽數、分割槽鍵和複製係數。