
用CNN巧妙解決金字塔滑動視窗,用cnn一邊滑動一遍輸出預測分類
效果如圖:

這是用cnn對一張305*471的影象做分類得到的結果,相當於做了52*93次滑動視窗+分類,卻僅僅耗時0.2672951465708593s。相當於一次視窗分類 ,僅僅耗時 0.00005s。
具體網路+預測如下圖所示:
import numpy as np import cv2 import time from keras.layers import Dense,Conv2D,MaxPooling2D,Flatten,Dropout,Activation,Reshape from keras.models import Sequential,Model from keras.preprocessing.image import ImageDataGenerator from keras.callbacks import ModelCheckpoint from keras import optimizers sgd = optimizers.SGD(lr=0.001, decay=1e-5, momentum=0.99, nesterov=True) model = Sequential() model.add(Conv2D(filters=16,strides=1,kernel_size=(3,3),padding='same',activation='relu',input_shape=(None, None,3))) model.add(Conv2D(filters=16,strides=1,kernel_size=(3,3),padding='same',activation='relu')) model.add(MaxPooling2D((2,2))) model.add(Conv2D(filters=32,strides=1,kernel_size=(3,3),padding='same',activation='relu')) # 32 * 50 * 50 #model.add(Conv2D(filters=64,kernel_size=(3,3),padding='same',activation='relu')) model.add(MaxPooling2D((2,2))) # 32 * 25 *25 #model.add(Flatten()) model.add(Conv2D(filters=3,strides=1,kernel_size=(25,25),padding='valid',activation='softmax',name='mutilCLS')) #model.add(Conv2D(filters=3,kernel_size=(1,1),padding='valid',activation='relu')) #model.add(Reshape([-1,-1,3])) model.add(Reshape([3])) #model.add(Flatten()) model.add(Dropout(0.5)) #model.add(Dense(3)) model.add(Activation('softmax')) #model.add(Dropout(0.5)) #model.add(Dense(3,activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy']) model.load_weights('best_cnn_cla_depthwise.h5') Mutil_layer_model = Model(inputs=model.input, outputs=model.get_layer('mutilCLS').output) a = cv2.imread('./train/0/2118.jpg') #a = cv2.resize(a,(102,102)) b = np.array(a) b = b.reshape((1,)+b.shape) sa = time.clock() cp = Mutil_layer_model.predict(b) cp = cp.reshape((cp.shape[1],cp.shape[2],3)) print(cp) db = time.clock()-sa print(db) for i in range(cp.shape[0]): for j in range(cp.shape[1]): if cp[i][j][1]>0.99: # print(i,j) cv2.rectangle(a,(j*4,i*4),(j*4+100,i*4+100),(255,0,0),1) cv2.imshow('aaa',a)
訓練網路如下:
# -*- coding: utf-8 -*- """ Created on Thu Sep 13 12:29:51 2018 @author: Lenovo """ from keras.layers import Dense,Conv2D,MaxPooling2D,Flatten,Dropout,Activation,Reshape from keras.models import Sequential from keras.preprocessing.image import ImageDataGenerator from keras.callbacks import ModelCheckpoint from keras import optimizers sgd = optimizers.SGD(lr=0.001, decay=1e-5, momentum=0.99, nesterov=True) model = Sequential() model.add(Conv2D(filters=16,strides=1,kernel_size=(3,3),padding='same',activation='relu',input_shape=(None, None,3))) model.add(Conv2D(filters=16,strides=1,kernel_size=(3,3),padding='same',activation='relu')) model.add(MaxPooling2D((2,2))) model.add(Conv2D(filters=32,strides=1,kernel_size=(3,3),padding='same',activation='relu')) # 32 * 50 * 50 #model.add(Conv2D(filters=64,kernel_size=(3,3),padding='same',activation='relu')) model.add(MaxPooling2D((2,2))) # 32 * 25 *25 #model.add(Flatten()) model.add(Conv2D(filters=3,strides=1,kernel_size=(25,25),padding='valid',activation='softmax',name='mutilCLS')) #model.add(Conv2D(filters=3,kernel_size=(1,1),padding='valid',activation='relu')) #model.add(Reshape([-1,-1,3])) model.add(Reshape([3])) #model.add(Flatten()) model.add(Dropout(0.5)) #model.add(Dense(3)) model.add(Activation('softmax')) #model.add(Dropout(0.5)) #model.add(Dense(3,activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy']) print(model.summary()) gen = ImageDataGenerator(rescale=1. / 255) train_gen_data = gen.flow_from_directory('./train',batch_size=300, shuffle=True,target_size=(100, 100),class_mode='categorical') test_gen_data = gen.flow_from_directory('./test',batch_size=43, shuffle=True,target_size=(100, 100),class_mode='categorical') save_best = ModelCheckpoint('best_cnn_cla_depthwise.h5', monitor='val_acc', verbose=1,save_best_only=True) callbacks=[save_best] model.fit_generator(train_gen_data, steps_per_epoch=8, epochs=45, verbose=1, callbacks=callbacks, validation_data=test_gen_data, validation_steps=1, shuffle=True, initial_epoch=0)
換張圖效果依舊很好

對於分出這麼多視窗,接下來需要非極大值抑制NMS來做視窗調優。
原理部分:
1.物件檢測
物件檢測(Object Detection)的目的是”識別物件並給出其在圖中的確切位置”,其內容可解構為三部分:
- 識別某個物件(Classification);
- 給出物件在圖中的位置(Localization);
- 識別圖中所有的目標及其位置(Detection)。
如下圖所示,從左到右分別展示了:某個物件的識別(P(目標)=1,class=car),物件在圖中的定位(給出邊框bounding box–
2.滑窗+CNN
滑動視窗(Sliding Windows,簡稱滑窗)法是進行目標檢測的主流方法。對於某輸入影象,由於其物件尺度形狀等因素的不確定性,導致直接套用預訓練好的模型進行識別效率低下。通過設計滑窗來遍歷影象,將每個視窗對應的區域性影象進行檢測,能有效克服尺度、位置、形變等帶來的輸入異構問題,提升檢測效果。下圖展示了某種大小的滑窗在待檢測影象上滑動的過程:

下圖展示了採用滑窗(size=8×8, stride=2)對圖片(10×10)進行物件檢測的全過程示意。圖示的輸出為2×2的網格,每個格子對應一個輸出標籤向量,給出了原圖對應的視窗區域影象的檢測結果(置信度、邊框位置、各類別概率等)。
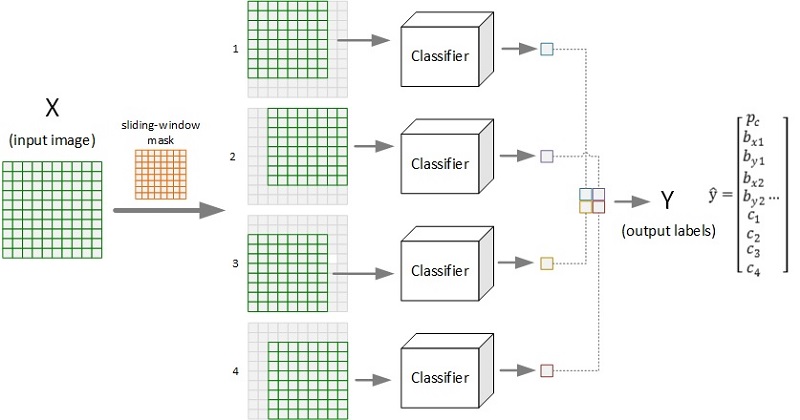
要實現物件檢測,需要有相應的目標識別模型(如上圖中的Classifier),卷積神經網路(CNN)是其中的主流模型之一。但是,按照上圖所示,採用CNN對每個視窗影象進行檢測,會產生大量的重複計算(如卷積操作),為了提高檢測效率,通過合理設計CNN模型,可以僅需一次前向傳播而得出整個影象的滑窗檢測結果。下圖展示了相關的模型設計實現過程:
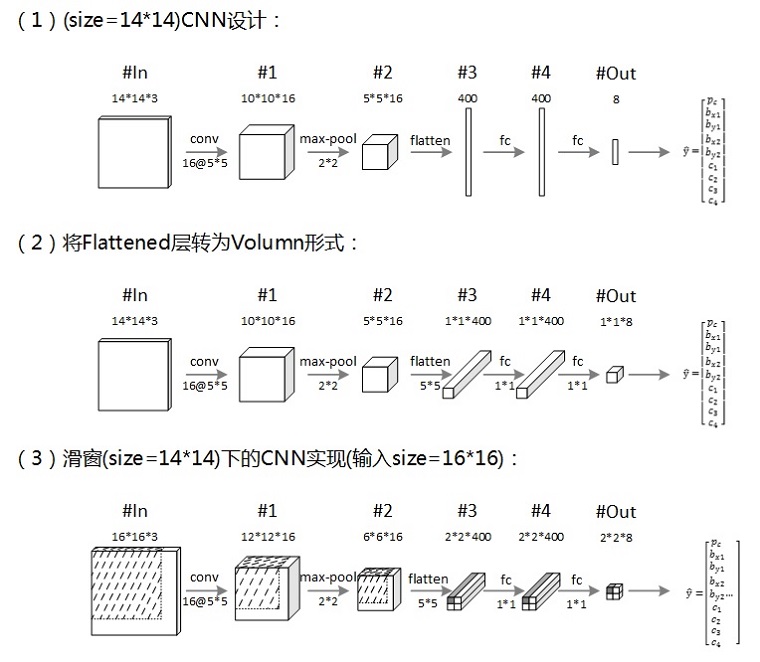
上圖的三步描述了採用14×14大小的視窗進行滑動卷積時的CNN設計實現過程。採用(2)所設計的CNN對(3)中的輸入影象進行檢測,可以一次性得出最終的結果網格,其相應位置的網格映射了滑動視窗在原影象上的相應區域(如圖中輸出2×2網格左上角向量即為第一個視窗的CNN檢測結果,圖中的陰影標註了該視窗資訊在CNN中的流動)。