
併發包非阻塞佇列ConcurrentLinkedQueue
jdk1.7.0_79
佇列是一種非常常用的資料結構,一進一出,先進先出。
在Java併發包中提供了兩種型別的佇列,非阻塞佇列與阻塞佇列,當然它們都是執行緒安全的,無需擔心在多執行緒併發環境所帶來的不可預知的問題。為什麼會有非阻塞和阻塞之分呢?這裡的非阻塞與阻塞在於有界與否,也就是在初始化時有沒有給它一個預設的容量大小,對於阻塞有界佇列來講,如果佇列滿了的話,則任何執行緒都會阻塞不能進行入隊操作,反之佇列為空的話,則任何執行緒都不能進行出隊操作。而對於非阻塞無界佇列來講則不會出現佇列滿或者佇列空的情況。它們倆都保證執行緒的安全性,即不能有一個以上的執行緒同時對佇列進行入隊或者出隊操作。
非阻塞佇列:ConcurrentLinkedQueue
阻塞佇列:ArrayBlockingQueue、LinkedBlockingQueue、……
本文介紹非阻塞佇列——ConcurentLinkedQueue。
首先檢視ConcurrentLinkedQueue預設建構函式,觀察它在初始化時做了什麼操作。
//ConcurrentLinkedQueue
public ConcurrentLinkedQueue() {
head = tail = new Node<E>(null);
}
可以看到ConcurrentLinkedQueue在其內部有一個頭節點和尾節點,在初始化的時候指向一個節點。

對於入隊(插入)操作一共提供了這麼2個方法(實際上是一個):
|
入隊(插入) |
add(e)(其內部呼叫offer方法,) |
offer(e)(插入到佇列尾部,當佇列無界將永遠返回true) |
1 //ConcurrentLinkedQueue#offer
2 public boolean offer(E e) {
3 checkNotNull(e); //入隊元素是否為空,不允許Null值入隊
4 final Node<E> newNode = new Node<E>(e); //將入隊元素構造為Node節點
5 /*tail指向的是佇列尾節點,但有時tail.next才是真正指向的尾節點*/
6 for (Node<E> t = tail, p = t;;) {
7 Node<E> q = p.next;
8 if (q == null) { //此時p指向的就是佇列真正的尾節點
9 if(p.casNext(null, newNode)) { //cas演算法,p.next = newNode
10 if (p != tail) //將tail指向佇列尾節點
11 casTail(t, newNode);
12 return true;
13 }
14 }
15 else if (p == q)
16 p = (t != (t = tail)) ? t : head;
17 else
18 p = (p != t && t != (t = tail)) t : q;
19 }
20 }offer入隊過程如下圖所示: ① 佇列中沒有元素,第一次入隊操作: 進入迴圈體: t = tail; p = tail; q = p.next = null;

判斷尾節點的引用p是否指向的是尾節點(if(q == null))->是: CAS演算法將入隊節點設定成尾節點的next節點(p.casNext(null, newNode)) 判斷tail尾節點指標的引用p是否大於等於1個next節點(if (p != t))->否 返回true

② 佇列中有元素,進行入隊操作:
1) 第一次迴圈: t = tail; p = tail; q = p.next = Node1;
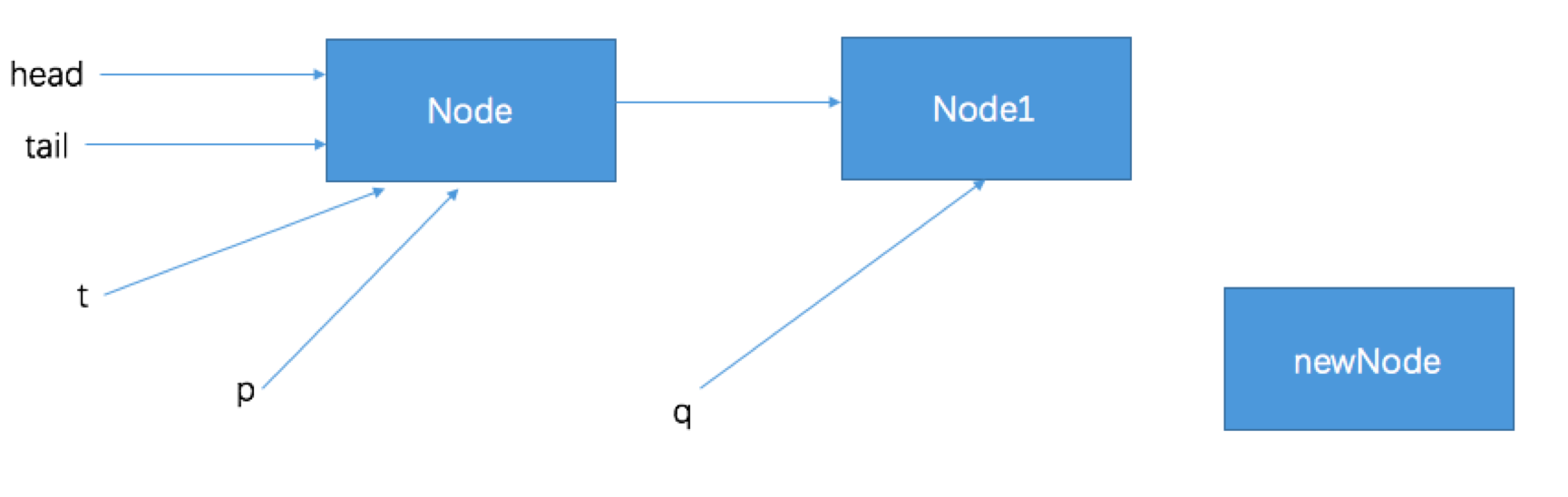
判斷tail尾節點指標的引用p是否指向的是尾節點(if(q == null))->否 判斷tail尾節點指標的引用p是否指向的是尾節點(else if (p == q))->否 將tail尾節點指標的引用p向後移動(p = (p != t && t != (t = tail)) ? t : q;)->p = Node1

2) 第二次迴圈: t = tail; p = Node1; q = p.next = null;

判斷tail尾節點指標的引用p是否指向真正的尾節點(if(q == null))->是: CAS演算法將入隊節點設定成尾節點的next節點(p.casNext(null, newNode)) 判斷tail尾節點指標的引用p是否大於等於1個next節點(if (p != t))->是: 更新tail節點(casTail(t, nextNode)) 返回true

入隊的操作都是由CAS演算法完成,顯然是為了保證其安全性。整個入隊過程首先要定位出尾節點,其次使用CAS演算法將入隊節點設定成尾節點的next節點。整個入隊過程首先要定位佇列的尾節點,如果將tail節點一直指向尾節點豈不是更好嗎?每次即tail->next = newNode;tail = newNode;這樣在單執行緒環境來確實沒問題,但是,在多執行緒併發環境下就不得不要考慮執行緒安全,每次更新tail節點意味著每次都要使用CAS更新tail節點,這樣入隊效率必然降低,所以ConcurrentLinkedQueue的tail節點並不總是指向佇列尾節點的原因就是減少更新tail節點的次數,提高入隊效率。 對於出隊(刪除)操作一共提供了這麼1個方法:

1 //ConcurrentLinkecQueue#poll
2 public E poll() {
3 restartFromHead:
4 for (;;) {
5 for (Node<E> h = head, p = h, q;;) {
6 E item = p.item;
7 if (item != null && p.casItem(item, null)) {
8 if (p != h)
9 updateHead(h, ((q = p.next) != null) ? q : p);
10 return item;
11 }
12 else if ((q = p.next) == null) {
13 updateHead(h, p);
14 return null;
15 }
16 else if (p == q)
17 continue restartFromHead;
18 else
19 p = q;
20 }
21 }
22 }
以上面佇列中有兩個元素為例:(注意,初始時,head指向的是空節點)

出隊(刪除): 1) 第一次迴圈: h = head; p = head; q = null; item = p.item = null;

判斷head節點指標的引用是否不是空節點(if (item != null))->否,即是空節點 判斷(暫略) 判斷(暫略) 將head節點指標的引用p向後移動(p = q)
2) 第二次迴圈: h = head; p = q = Node1; q = Node1; item = p.item = Node1.item;

判斷head節點指標的引用p是否不是空節點(if (item != null))->是,即不是空節點: 判斷head節點指標與p是否指向同一節點(if (p != h))->否: 更新頭節點(updateHead(h, ((q = p.next) != null) ? q : p)) 返回item

實際上繼續出隊會發現,出隊和入隊類似,不會每次出隊都會更新head節點,原理也和tail一樣。 對於ConcurrentLinkedQueue#size方法將會遍歷整個佇列,可想它的效率並不高,如果一定需要呼叫它的size方法,特別是for迴圈時,我建議一下寫法:
for (int i = 0, int size = concurrentLinkedQueue.size(); i < size;i++)
因為這能保證不用每次迴圈都呼叫一次size方法遍歷一遍佇列。