吳恩達機器學習 筆記八 K-means聚類演算法
阿新 • • 發佈:2018-12-10
1. 代價函式
K-means演算法是比較容易理解的,它屬於無監督學習方法,所以訓練樣本資料不再含有標籤。我們假設有樣本資料,我們選擇設定個聚類中心,K-means演算法的代價函式表示式如下
其中表示距離最近的聚類中心。2. 具體演算法
K-means演算法的具體流程如下:
Repeat { for i = 1 to m c(i) := index (form 1 to K) of cluster centroid closest to x(i) for k = 1 to K μk := average (mean) of points assigned to cluster k }
其中,第一個迴圈用於更新每個樣本距離最近的聚類中心,第二個迴圈用於更新聚類中心所處的位置。
3. 隨機初始化
通常我們會隨機選取 個樣本資料作為初始聚類中心,但是這樣可能得到一個區域性最小點。其中一個解決方法是,
多次執行K-均值演算法,每一次都重新進行隨機初始化,最後再比較多次執行K-均值的結果,選擇代價函式最小的結果。
但是,這種方法在,即較小的時候還是可行的,但是如果較大,這麼做也可能不會有明顯地改善。
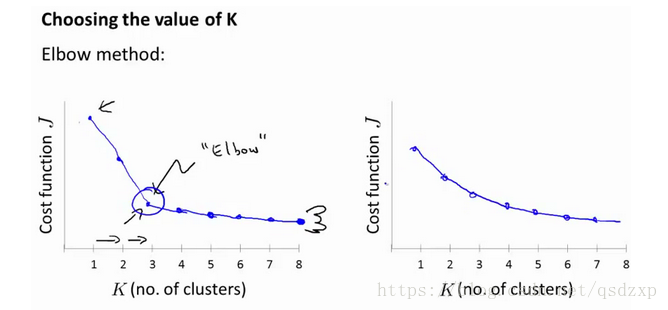
4.聚類數的選取
絕大多數是需要根據資料人工選取的。肘圖的方法可能有所幫助,比如得到左側結果的時候,我們就可以選擇肘的位置的作為聚類數。但肘圖不一定可行,比如得到圖中右側結果的時候。