
資料分析與挖掘day_1
目錄
一、初識資料分析與挖掘
1.1 什麼是資料分析與挖掘技術?
所謂資料分析,即對已知的資料進行分析,然後提取出一些有價值的信 息,比如統計出平均數、標準差等資訊,資料分析的資料量有時可能不會太大,而資料探勘,是指對大量的資料進行分析與挖掘,得到一些未知的,有價值的資訊等,比如從網站的使用者或使用者行為資料中挖掘出使用者的潛在需求資訊,從而對網站進行改善等。資料分析與資料探勘密不可分,資料探勘是資料分析的提升。
1.2 資料分析與挖掘技術能做什麼事情?
資料探勘技術可以幫助我們更好的發現事物之間的規律。所以,我們可以利用資料探勘技術實現資料規律的探索,比如發現竊電使用者、發掘使用者潛在需求(啤酒尿布)、實現資訊的個性化推送、風險防控、發現疾病與症狀甚至疾病與藥物之間的規律……等。
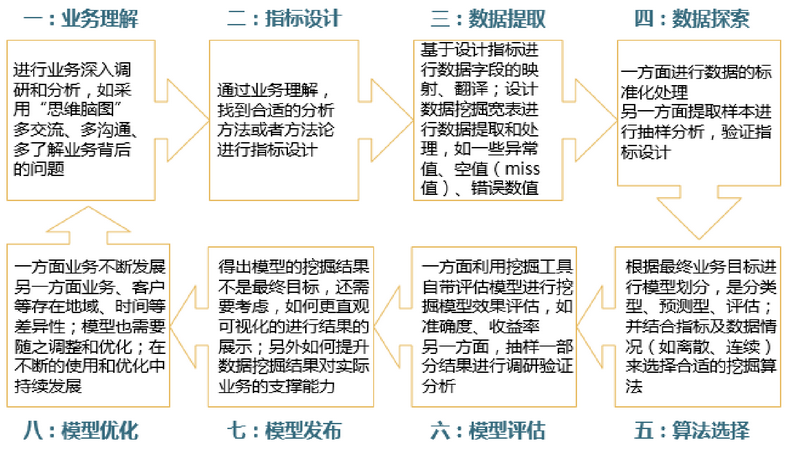
1.3 資料探勘的過程
應用建模的八步法:業務理解、指標設計、資料提取、資料探索、演算法選擇、模型評估、模型釋出、模型優化
二、資料探勘與Python模組功能介紹
2.1 基本模組
Numpy
Python沒有提供陣列,列表(List)可以完成陣列,但不是真正的資料,當資料量增大時,它的速度很慢。所以Numpy擴充套件包提供了陣列支援以及高效的 處理函式,同時很多高階擴充套件包依賴它。
Pandas
Pandas是面板資料(Panel Data)的簡寫。它是Python最強大的資料分析和探索工具,因金融資料分析工具而開發,支援類似SQL的資料增刪改查,支援時間序列分析,靈活處理缺失資料,後面詳細介紹。
Scipy
Scipy提供矩陣支援,以及矩陣相關的數值計算模組。如果說Numpy讓Python有了Matlab的味道,那麼Scipy就讓Python真正地成為二半個Matlib。因為涉及到矩陣內容,而課程中主要使用陣列,所以不再介紹。
scikit-learn
Scikit-Learn是一個基於python的用於資料探勘和資料分析的簡單且有效的工具,它的基本功能主要被分為六個部分:分類(Classification)、迴歸(Regression)、聚類(Clustering)、資料降維(Dimensionality Reduction)、模型選擇(Model Selection)、資料預處理(Preprocessing),前面寫的很多文章演算法都是出自該擴充套件包。
2.2 其他常用模組
Theano
用來定義、優化和模擬數學表示式計算,用於高效地解決多維陣列的計算問題以及深度學、框架。
Keras
基於Theano的深度學習庫,主要用於搭建人工神經網路、自編碼器、卷積神經網路等深度學習模型。
Gensim
是一個python的自然語言處理庫,能夠將文件根據TF-IDF, LDA, LSI 等模型轉化成向量模式,以便進行進一步的處理。此外,gensim還實現了word2vec功能,能夠將單詞轉化為詞向量,用於文字挖掘。
StatsModels
注重資料統計建模分析的資料處理模組,與Pandas結合,強大的資料探勘組合。
NLTK(natural language toolkit)
Python自然語言處理模組,包括一系列的字元處理和語言統計模型。常用於學術研究和教學,應用領域有語言學、認知科學、人工智慧、資訊檢索、機器學習等。
Mlpy
基於NumPy和SciPy的機器學習模組,CPython的拓展應用。
PyBrain
Python機器學習模組,用於處理神經網路、強化學習、無監督學習、進化演算法。
Milk
Python機器學習工具箱,重點提高監督分類法與幾種有效的分類分析:SVMs,kNN,隨機森林和決策樹等。
Pattern
Python的web挖掘模組,綁定了Google、Twitter、Wikipedia API,提供網路爬蟲、HTML解析功能,文字分析包括淺層規則解析、WordNet介面、句法與語義分析、TF-IDF、LSA等,還提供聚類、分類和圖網路視覺化的功能。
Orange
基於元件的資料探勘和機器學習軟體套裝,它功能友好強大,擁有快速而多功能的視覺化程式設計前端,以便瀏覽資料分析和視覺化,且綁定了Python已進行指令碼開發。它包含了完整的一系列的元件以進行資料預處理,並提供了資料賬目、過渡、建模、模式評估和勘探的功能。
MXNet
深度學習最新框架,效能和速度超越Theano。
XGBoost
是一個速度快、效果好的boosting模型,被封裝成了Python模組。該模組能夠自動利用CPU的多執行緒進行並行,同時提高了演算法的精度。