
python 二級考試操作題(一)
一、參照程式碼模板完善程式碼,實現下述功能。從鍵盤輸入一個整數和一個字元,以逗號隔開,在螢幕上顯示輸出一條資訊。
—————————————————————————————–
示例如下:
輸入:10,@ 輸出:@@@@@@@@@@ 10 @@@@@@@@@@
參考答案:
a,x = input().split(',') # 請輸入1個整數和1個符號,逗號隔開
print(x*eval(a),a,x*eval(a))要點: 1. 輸入兩個值組成的字串,要用split()分割開 2.同時賦值給兩個變數 3.利用eval得到數值做運算,給字元做乘法,得到需要的格式
二、參照程式碼模板完善程式碼,實現下述功能。從鍵盤輸入一個由 1 和 0 組成的二進位制字串 s,轉換為八進位制數輸出顯示在螢幕上,示例如下:
—————————————————————————————– 例項如下:
輸入:1100 輸出:轉換成八進位制數是:14
參考答案:
s = input() # 請輸入一個由1和0組成的二進位制數字串
d = 0
while s:
d = d*2 + (ord(s[0]) -ord('0'))
s = s[1:]
print("轉換成八進位制數是:{:o}".format(d))要點: 1.print和format的格式用法,字串的內建處理函式,切片 2.理解資料型別及其轉換
三、參照程式碼模板完善程式碼,實現下述功能。檔案 data.txt 檔案中有多行資料,開啟檔案,讀取資料,並將其轉化為列表。統計讀取的資料,計算每一行的總和、平均值,在螢幕上輸出結果。
—————————————————————————————–
檔案內容示例如下:

螢幕輸出結果示例如下: 總和是:511.0,平均值是:85.17
輸入輸出示例 輸入:從檔案 data.txt 中讀取 輸出:總和是:511.0,平均值是:85.17
參考答案:
fi = open("data.txt", 'r')
for l in fi:
l = l.split(',')
s = 0.0
n = len(l)
for cours in l:
items = cours.split(':')
s += eval(items 四、參照程式碼模板完善程式碼,實現下述功能,不得修改其它程式碼。使用 turtle 庫的 turtle.circle() 函式和 turtle.seth() 函式繪製同心圓套圈,最小的圓圈半徑為 10 畫素,不同圓圈之間的半徑差是 40 畫素,效果如下圖所示。
—————————————————————————————–
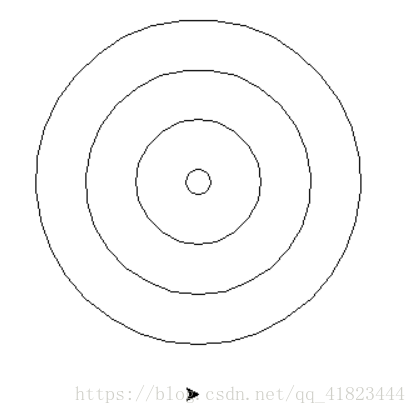
import turtle
r = 10
dr = 40
head = 90
for i in range (4):
turtle.pendown()
turtle.circle(r)
r += dr
turtle.penup()
turtle.seth(-head)
turtle.fd(dr)
turtle.seth(0)
turtle.done()要點: 1. 同心圓主要問題是要挪動畫筆,用到 pendown 和 penup 2. 用迴圈來處理重畫的個數
五、參照程式碼模板完善程式碼,實現下述功能。從鍵盤輸入一箇中文字串變數 s,內部包含中文標點符號。
—————————————————————————————–
問題1:(8分)用 jieba 分詞,計算字串 s 中的中文詞彙個數,不包括中文標點符號。顯示輸出分詞後的結果,用”/ ”分隔,以及中文詞彙個數。示例如下:
輸入: 工業網際網路”實施的方式是通過通訊、控制和計算技術的交叉應用,建造一個資訊物理系統,促進物理系統和數字系統的融合。
輸出: 工業/ 網際網路/實施/ 的/ 方式/是/ 通過/ 通訊/控制/ 和/ 計算技術/的/ 交叉/ 應用/建造/ 一個/ 資訊/物理/ 系統/ 促進/物理/ 系統/ 和/數字/ 系統/ 的/融合/
中文詞語數是:27
問題2:(7分)在問題1的基礎上,統計分詞後的詞彙出現的次數,用字典結構儲存。顯示輸出每個詞彙出現的次數,以及出現次數最多的詞彙。如果有多個詞彙出現次數一樣多,都要顯示出來。示例如下:
繼續輸出:
控制: 1 物理: 2 通訊: 1 交叉: 1 網際網路: 1 和: 2 是: 1 計算技術: 1 一個: 1 的: 3 數字: 1 促進: 1 資訊: 1 方式: 1 建造: 1 應用: 1 系統: 3 通過: 1 實施: 1 融合: 1 工業: 1 出現最多的詞是(的 系統):3 次
參考答案1:
import jieba
#問題一
#s = “工業網際網路”實施的方式是通過通訊、控制和計算技術的交叉應用,
#建造一個資訊物理系統,促進物理系統和數字系統的融合。”
s = input("請輸入一段中文,可以有標點:")
ls = jieba.lcut(s)
sym = ",。:;“”、!"
for each in ls:
if each in sym:
ls.remove(each)
#剔除中文標點符號
str_to_output= "/".join(ls)
print(str_to_output)
print("中文詞語數是:%d\n\n" % len(ls))
print("--------我是兩個問題的分割線------------\n\n")
#問題二
d = {}
for each in ls:
d[each] = d.get(each, 0) + 1
for key in d:
print("{}:{}".format(key,d[key]))
max = 0
lss = []
#尋找出現最多的次數
for key in d:
if max < d[key]:
max = d[key]
#把出現最多的詞語放在lss列表裡
for key in d:
if max == d[key]:
lss.append(key)
str_to_output= " ".join(lss)
print("出現最多的詞是({}):{}次".format(str_to_output,max))參考答案2:
import jieba
# s = '“工業網際網路”實施的方式是通過通訊、控制和計算技術的交叉應用,建造一個資訊物理系統,促進物理系統和數字系統的融合。'
s = input("請輸入一箇中文字串,包含逗號和句號:")
s = s.replace(',','').replace('。','').replace('、','').replace('“','').replace('”','')
k=jieba.lcut(s)
d1 = {}
maxc = 0
wo = ''
for i in k:
print(i, end= "/ ")
d1[i] = d1.get(i,0) + 1
print("\n中文詞語數是:{}".format(len(k)))
for key in d1:
if maxc < d1[key]:
wo = key
maxc = d1[key]
elif maxc == d1[key]:
wo += ' ' + key
print("{}: {}".format(key,d1[key]))
print("出現最多的詞是({}):{} 次".format(wo, maxc))要點: 1. 用 jieba 分詞處理詞彙統計 2. 要處理掉輸入的各種標點符號,用到replace() 3. 用字典儲存各個詞出現次數 4. 要遍歷字典的鍵值對,找到最大的值,及其對應的鍵
六、一個人臉識別研究小組對若干名學生做了人臉識別的測試,將測試結果與被測試者的現場照片組合成檔名,寫到了一個檔案 dir_100.txt 中,每行是一個檔名的資訊,示例如下:
—————————————————————————————– [‘1709020621’, ‘0’]_116.jpg [‘1709020621’]_115.jpg [‘1770603107’, ‘1770603105’, ‘0’, ‘0’]_1273.jpg 檔名各部分含義如下:
[‘識別出學號1’,‘ 識別出學號2’,…,‘0表示檢測到人臉但未識別出人’]_照片的順序編號.jpg
測試過程中,一個學生可能被抓拍到多張照片中,所以會在多個檔名中被識別,學號出現在多個檔名中;一張照片中,可能有多個人臉,但有些解析度不夠而識別不出來,檔名位置用‘0’代替學號。
使用字典和列表型變數進行資料分析,最終獲取實際參加測試的學生人數和人均被測次數。
(1)讀入 dir_300.txt 檔案的內容,處理每一行檔名資訊。將檔名中的學號內容以列表形式儲存,丟掉‘0’的字串;照片的順序編號作為字典的關鍵字,學號列表作為字典的值。轉換後,顯示字典中的每行資訊,示例如下:
116:1709020621
115:1709020621
117:1709020621
1273: 1770603107,1770603105
(2)將該字典中的學號提取出來,構造另一個字典,以學號作為字典的關鍵字,累計學號出現的次數,將累計值作為字典的值。格式示例如下:
1709020621:3 1770603107:1 1770603105:1
(3)累計字典中關鍵字的個數,即為實際參加測試的學生人數;累加每個關鍵字對應的值,即為所有學號測試次數;與實際測試人數之比,即為人均被測次數。將實際參加測試人數和人均被測次數顯示輸出在螢幕上,示例如下:
實際參加測試的人數是:1024 人均被測次數是:2.7
參考答案:
picd = {}
numd = {}
fi = open("dir_50.txt",'r')
for l in fi:
l=l.replace('\n','').split('_')## print(l[1])
if l[0] != '' :
lkey,lvalue = l[1][:-4],eval(l[0])
lval = []
for v in lvalue:
if v != '0':
lval.append(v)
if lval:
lv= ','.join(lval)
print("{}:{}".format( lkey,lv))
picd[lkey] = lv
fi.close()
idd = {}
for key in picd:
ids = picd[key].split(',')
for num in ids:
idd[num] = idd.get(num,0) +1
#print(num,idd[num])
s = 0
for key in idd:
s += int(idd[key])
# print("{}:{}".format(key, idd[key]))
count = len(idd)
print("實際參加測試的人數是:",count)
print("人均被測次數是:{:.1f}".format(s/count))要點: 1. 這是一個實際問題,解決問題的方法有實際的推廣意義。問題的關鍵是要完成資料提取,然後才是分析統計 2. 檔案的讀寫,開啟關閉是基礎 3. 讀入檔案要進行字串的處理,按行,分割成列表 3. 資料提取:先取得檔案裡的有效內容,轉換成列表,利用列表的切片,提取出照片編號和學號,放到字典picd裡 4. 第二步資料分析,需要先從字典裡把學號提取出來,為了便於統計每個學號被測的次數,再建一個字典idd 5. idd字典的鍵是學號,所以字典的len就是參加測試的人數 6. 為了計算平均測試次數,需要累計每個學號被測的次數,最後除以參加測試人數就得到結果
**野生程式設計師一枚,有錯誤的地方希望各位大佬指正! 歡迎在評論區發表您自己的意見和看法**