
sparkCore-RDD詳解
1.1 什麼是RDD
1.1.1 產生背景
當初設計RDD主要是為了解決三個問題:
- Fast: Spark之前的Hadoop用的是MapReduce的程式設計模型,沒有很好的利用分散式記憶體系統,中間結果都需要儲存到external disk,執行效率很低。RDD模型是in-memory computing的,中間結果不需要被物化(materialized),它的persistence機制,可以儲存中間結果重複使用,對需要迭代運算的機器學習應用和互動式資料探勘應用,加速顯著。Spark快還有一個原因是開頭提到過的Delay Scheduling機制,它得益於RDD的Dependency設計。
- General: MapReduce程式設計模型只能提供有限的運算種類(Map和Reduce),RDD希望支援更廣泛更多樣的operators(map,flatMap,filter等等),然後使用者可以任意地組合他們。
The ability of RDDs to accommodate computing needs that were previously met only by introducing new frameworks is, we believe, the most credible evidence of the power of the RDD abstraction.
- Fault tolerance: 其他的in-memory storage on clusters,基本單元是可變的,用細粒度更新(fine-grained updates)方式改變狀態,如改變table/cell裡面的值,這種模型的容錯只能通過複製多個數據copy,需要傳輸大量的資料,容錯效率低下。而RDD是不可變的(immutable),通過粗粒度變換(coarse-grained transformations),比如map,filter和join,可以把相同的運算同時作用在許多資料單元上,這樣的變換隻會產生新的RDD而不改變舊的RDD。這種模型可以讓Spark用Lineage很高效地容錯(後面會有介紹)。
1.1.2 RDD定義
A Resilient Distributed Dataset (RDD), the basic abstraction in Spark. Represents(代表) an immutable(不變的),partitioned collection of elements that can be operated on in parallel
RDD是spark的核心,也是整個spark的架構基礎,RDD是彈性分散式集合(Resilient Distributed Datasets)的簡稱。
1.1.3 RDD特點
-
immutable:只讀,任何操作都不會改變RDD本身,只會創造新的RDD
-
fault-tolerant:容錯,通過Lineage可以高效容錯
-
partitioned:分片,RDD以partition作為最小儲存和計算單元,分佈在cluster的不同nodes上,一個node可以有多個partitions,一個partition只能在一個node上
-
in parallel:並行,一個Task對應一個partition,Tasks之間相互獨立可以平行計算
-
persistence:持久化,使用者可以把會被重複使用的RDDs儲存到storage上(記憶體或者磁碟)
-
partitioning:分割槽,使用者可以選擇RDD元素被partitioned的方式來優化計算,比如兩個需要被join的資料集可以用相同的方式做hash-partitioned,這樣可以減少shuffle提高效能
1.1.4 RDD抽象概念
一個RDD定義了對資料的一個操作過程, 使用者提交的計算任務可以由多個RDD構成。多個RDD可以是對單個/多個數據的多個操作過程。多個RDD之間的關係使用依賴來表達。操作過程就是使用者自定義的函式。
RDD(彈性分散式資料集)去掉形容詞,主體為:資料集。如果認為RDD就是資料集,那就有點理解錯了。個人認為:RDD是定義對partition資料項轉變的高階函式,應用到輸入源資料,輸出轉變後的資料,即:RDD是一個數據集到另外一個數據集的對映,而不是資料本身。 這個概念類似數學裡的函式f(x) = ax^2 + bx + c。這個對映函式可以被序列化,所要被處理的資料被分割槽後分布在不同的機器上,應用一下這個對映函式,得出結果,聚合結果。
這些集合是彈性的,如果資料集一部分丟失,則可以對它們進行重建。具有自動容錯、位置感知排程和可伸縮性,而容錯性是最難實現的,大多數分散式資料集的容錯性有兩種方式:資料檢查點和記錄資料的更新。對於大規模資料分析系統,資料檢查點操作成本高,主要原因是大規模資料在伺服器之間的傳輸帶來的各方面的問題,相比記錄資料的更新,RDD也只支援粗粒度的轉換共享狀態而非細粒度的更新共享狀態,也就是記錄如何從其他RDD轉換而來(即lineage),以便恢復丟失的分割槽。
RDDs 非常適合將相同操作應用在整個資料集的所有的元素上的批處理應用. 在這些場景下, RDDs 可以利用血緣關係圖來高效的記住每一個 transformations 的步驟, 並且不需要記錄大量的資料就可以恢復丟失的分割槽資料. RDDs 不太適合用於需要非同步且細粒度的更新共享狀態的應用, 比如一個 web 應用或者資料遞增的 web 爬蟲應用的儲存系統。
1.2 RDD特點
Internally, each RDD is characterized by five main properties:
- A list of partitions
- A function for computing each split
- A list of dependencies on other RDDs
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
每個特性都對應RDD.scala中的一個方法實現:
-
a list of partition由多個機器裡面的partition組成的 -
a function for computing each split平行計算 -
a list of dependencies on other RDDSrdd間存在依賴關係,記錄資料轉換間的依賴 -
a partitioner for key-vaueRDDS 可進行重新分割槽(只有key value的partition有) -
a list of preferred locations to compute each spilt on用最期望的位置進行計算
1.3 RDD操作
1.3.1 RDD建立
parallelize:從普通Scala集合建立
val data = Array(1, 2, 3, 4, 5)
val distData = sc.parallelize(data)
- 從Hadoop檔案系統或與Hadoop相容的其他持久化儲存系統建立,如Hive、HBase
scala> val distFile = sc.textFile("data.txt")
distFile: org.apache.spark.rdd.RDD[String] = data.txt MapPartitionsRDD[10] at textFile at <console>:26
- 從父RDD轉換得到新的RDD
val fromParent=distFile.map(s=>s.length)
1.3.2 操作方式
RDD在巨集觀來看類似於java中物件的概念,我們在java中對物件上作用一系列操作(方法)得到最終結果。同樣的我們在RDD上進行一系列操作(運算元)將一個RDD轉換為另一個RDD,最終得到我們所需要的RDD。RDD運算元主要包括:
-
Transformation運算元:Transformation操作是延遲計算的,即從一個RDD轉換成另一個RDD的轉換操作不是 馬上執行,需要等到有Action操作時,才真正出發執行,如Map、Filter等操作 -
Action運算元:Action運算元會出發Spark提交作業(Job),並將資料輸出到Spark系統,如collect、count等
RDD操作特點 惰性求值:
transformation運算元作用在RDD時,並不是立即觸發計算,只是記錄需要操作的指令。等到有Action運算元出現時才真正開始觸發計算。
textFile等讀取資料操作和persist和cache快取操作也是惰性的
為什麼要使用惰性求值呢:使用惰性求值可以把一些操作合併到一起來減少資料的計算步驟,提高計算效率。
從惰性求值角度看RDD就是一組spark計算指令的列表
1.3.4 快取策略
RDD的快取策略在StorageLevel中實現,通過對是否序列化,是否儲存多個副本等條件的組合形成了多種快取方式。例如:MEMORY_ONLY_SER儲存在記憶體中並進行序列化,當記憶體不足時,不進行本地化;MEMORY_AND_DISK_2優先儲存記憶體中,記憶體中無空間時,儲存在本地磁碟,並有兩個副本。
class StorageLevel private(
// 快取方式
private var _useDisk: Boolean, // 是否使用磁碟
private var _useMemory: Boolean, // 是否使用記憶體
private var _useOffHeap: Boolean, // 是否使用堆外記憶體
private var _deserialized: Boolean, // 是否序列化
private var _replication: Int = 1) // 儲存副本,預設一個
extends Externalizable {
// 條件組合結果
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
策略選擇順序:
-
預設選擇
MEMORY_ONLY -
如果記憶體不足,選擇
MEMORY_ONLY_SER -
如果需要做容錯,選擇
MEMORY_ONLY_SER_2 -
如果中間計算RDD的代價比較大時,選擇
MEMORY_AND_DISK
控制操作:
persist操作,可以將RDD持久化到不同層次的儲存介質,以便後續操作重複使用。
1)cache:RDD[T] 預設使用MEMORY_ONLY
2)persist:RDD[T] 預設使用MEMORY_ONLY
3)Persist(level:StorageLevel):RDD[T] eg: myRdd.persist(StorageLevels.MEMORY_ONLY_SER)
checkpoint
將RDD持久化到HDFS中,與persist操作不同的是checkpoint會切斷此RDD之前的依賴關係,而persist依然保留RDD的依賴關係。
1.3.5 RDD回收
Spark automatically monitors cache usage on each node and drops out old data partitions in a least-recently-used (LRU) fashion. If you would like to manually remove an RDD instead of waiting for it to fall out of the cache, use the `RDD.unpersist()` method.
spark有一個監控執行緒去檢測記憶體使用情況,當記憶體不足時使用LRU進行淘汰old data,也可以通過RDD.unpersist()方法手動移除快取。
1.3.6 RDD儲存
saveAsTextFile()將RDD中的元素儲存在指定目錄中,這個目錄位於任何Hadoop支援的儲存系統中saveAsObjectFile()將原RDD中的元素序列化成Java物件,儲存在指定目錄中saveAsSequenceFile()將鍵值對型RDD以SequenceFile的格式儲存。鍵值對型RDD也可以以文字形式儲存
需要注意的是,上面的方法都把一個目錄名字作為入參,然後在這個目錄為每個RDD分割槽建立一個資料夾。這種設計不僅可以高效而且可容錯。因為每個分割槽被存成一個檔案,所以Spark在儲存RDD的時候可以啟動多個任務,並行執行,將資料寫入檔案系統中,這樣也保證了寫入資料的過程中可容錯,一旦有一個分割槽寫入檔案的任務失敗了,Spark可以在重啟一個任務,重寫剛才失敗任務建立的檔案。
2. RDD詳解
2.1 RDD分割槽
RDD 表示平行計算的計算單元是使用分割槽(Partition)。
2.1.1 分割槽實現
RDD 內部的資料集合在邏輯上和物理上被劃分成多個小子集合,這樣的每一個子集合我們將其稱為分割槽,分割槽的個數會決定平行計算的粒度,而每一個分割槽數值的計算都是在一個單獨的任務中進行,因此並行任務的個數,也是由 RDD(實際上是一個階段的末 RDD,排程章節會介紹)分割槽的個數決定的。
RDD 只是資料集的抽象,分割槽內部並不會儲存具體的資料。Partition 類內包含一個 index 成員,表示該分割槽在 RDD 內的編號,通過 RDD 編號 + 分割槽編號可以唯一確定該分割槽對應的塊編號,利用底層資料儲存層提供的介面,就能從儲存介質(如:HDFS、Memory)中提取出分割槽對應的資料
怎麼切分是Partitioner定義的, Partitioner有兩個介面: numPartitions分割槽數, getPartition(key: Any): Int根據傳入的引數確定分割槽號。實現了Partitioner的有:
- HashPartitioner
- RangePartitioner
- GridPartitioner
- PythonPartitioner
一個RDD有了Partitioner, 就可以對當前RDD持有的資料進行劃分
2.1.2 分割槽個數
RDD 分割槽的一個分配原則是:儘可能使得分割槽的個數等於叢集的CPU核數。
RDD 可以通過建立操作或者轉換操作得到。轉換操作中,分割槽的個數會根據轉換操作對應多個 RDD 之間的依賴關係確定,窄依賴子 RDD 由父 RDD 分割槽個數決定,Shuffle 依賴由子 RDD 分割槽器決定。
建立操作中,程式開發者可以手動指定分割槽的個數,例如 sc.parallelize (Array(1, 2, 3, 4, 5), 2) 表示建立得到的 RDD 分割槽個數為 2,在沒有指定分割槽個數的情況下,Spark 會根據叢集部署模式,來確定一個分割槽個數預設值。
對於 parallelize 方法,預設情況下,分割槽的個數會受 Apache Spark 配置引數 spark.default.parallelism 的影響,無論是以本地模式、Standalone 模式、Yarn 模式或者是 Mesos 模式來執行 Apache Spark,分割槽的默認個數等於對 spark.default.parallelism 的指定值,若該值未設定,則 Apache Spark 會根據不同叢集模式的特徵,來確定這個值。
本地模式,預設分割槽個數等於本地機器的 CPU 核心總數(或者是使用者通過 local[N] 引數指定分配給 Apache Spark 的核心數目),叢集模式(Standalone 或者 Yarn)預設分割槽個數等於叢集中所有核心數目的總和,或者 2,取兩者中的較大值(conf.getInt("spark.default.parallelism", math.max(totalCoreCount.get(), 2)))
對於 textFile 方法,預設分割槽個數等於 min(defaultParallelism, 2)
2.1.3 分割槽內部記錄個數
分割槽分配的另一個分配原則是:儘可能使同一 RDD 不同分割槽內的記錄的數量一致。
對於轉換操作得到的 RDD,如果是窄依賴,則分割槽記錄數量依賴於父 RDD 中相同編號分割槽是如何進行資料分配的,如果是 Shuffle 依賴,則分割槽記錄數量依賴於選擇的分割槽器,分割槽器有雜湊分割槽和範圍分割槽。雜湊分割槽器無法保證資料被平均分配到各個分割槽,而範圍分割槽器則能做到這一點
對於textFile 方法分割槽內資料的大小則是由 Hadoop API 介面 FileInputFormat.getSplits 方法決定(見 HadoopRDD 類),得到的每一個分片即為 RDD 的一個分割槽,分片內資料的大小會受檔案大小、檔案是否可分割、HDFS 中塊大小等因素的影響,但總體而言會是比較均衡的分配
2.2 RDD依賴
2.2.1 依賴與 RDD
RDD 的容錯機制是通過記錄更新來實現的,且記錄的是粗粒度的轉換操作。在外部,我們將記錄的資訊稱為血統(Lineage)關係,而到了原始碼級別,Apache Spark 記錄的則是 RDD 之間的**依賴(Dependency)**關係。在一次轉換操作中,建立得到的新 RDD 稱為子 RDD,提供資料的 RDD 稱為父 RDD,父 RDD 可能會存在多個,我們把子 RDD 與父 RDD 之間的關係稱為依賴關係,或者可以說是子 RDD 依賴於父 RDD。
依賴只儲存父 RDD 資訊,轉換操作的其他資訊,如資料處理函式,會在建立 RDD 時候,儲存在新的 RDD 內。依賴在 Apache Spark 原始碼中的對應實現是 Dependency 抽象類,每個 Dependency 子類內部都會儲存一個 RDD 物件,對應一個父 RDD,如果一次轉換轉換操作有多個父 RDD,就會對應產生多個 Dependency 物件,所有的 Dependency 物件儲存在子 RDD 內部,通過遍歷 RDD 內部的 Dependency 物件,就能獲取該 RDD 所有依賴的父 RDD。
2.2.2 依賴分類
Apache Spark 將依賴進一步分為兩類,分別是**窄依賴(Narrow Dependency)**和 Shuffle 依賴(Shuffle Dependency,在部分文獻中也被稱為 Wide Dependency,即寬依賴)。
窄依賴中,父 RDD 中的一個分割槽最多隻會被子 RDD 中的一個分割槽使用,換句話說,父 RDD 中,一個分割槽內的資料是不能被分割的,必須整個交付給子 RDD 中的一個分割槽。
窄依賴可進一步分類成一對一依賴和範圍依賴,對應實現分別是 OneToOneDependency 類和RangeDependency 類。一對一依賴表示子 RDD 分割槽的編號與父 RDD 分割槽的編號完全一致的情況,若兩個 RDD 之間存在著一對一依賴,則子 RDD 的分割槽個數、分割槽內記錄的個數都將繼承自父 RDD。範圍依賴是依賴關係中的一個特例,只被用於表示 UnionRDD 與父 RDD 之間的依賴關係。相比一對一依賴,除了第一個父 RDD,其他父 RDD 和子 RDD 的分割槽編號不再一致,Apache Spark 統一將unionRDD與父 RDD 之間(包含第一個 RDD)的關係都叫做範圍依賴。
依賴類圖:
graph TD
A[Dependency<br>依賴關係基類]--- B[NarrowDependency<br>窄依賴]
A---C[ShuffleDenpendency<br>shuffle依賴]
B---D[OneToOneDependency<br>一對一依賴]
B---E[RangeDependency<br>範圍依賴]
下圖展示了幾類常見的窄依賴及其對應的轉換操作。
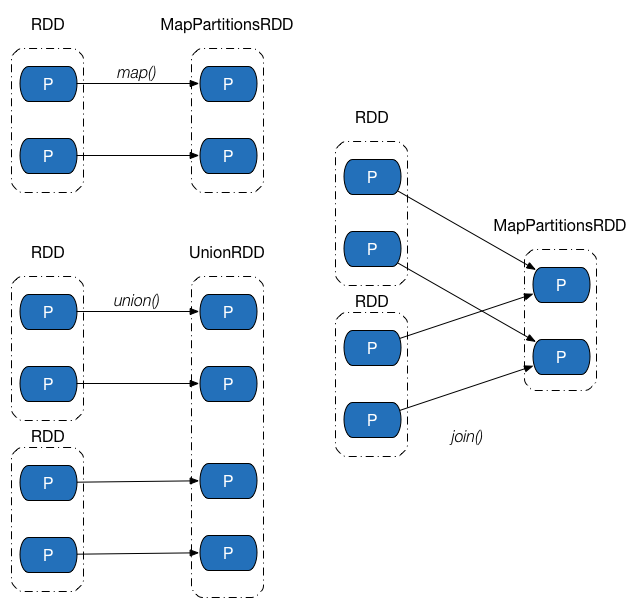
Shuffle 依賴中,父 RDD 中的分割槽可能會被多個子 RDD 分割槽使用。因為父 RDD 中一個分割槽內的資料會被分割,傳送給子 RDD 的所有分割槽,因此 Shuffle 依賴也意味著父 RDD 與子 RDD 之間存在著 Shuffle 過程。下圖展示了幾類常見的Shuffle依賴及其對應的轉換操作。
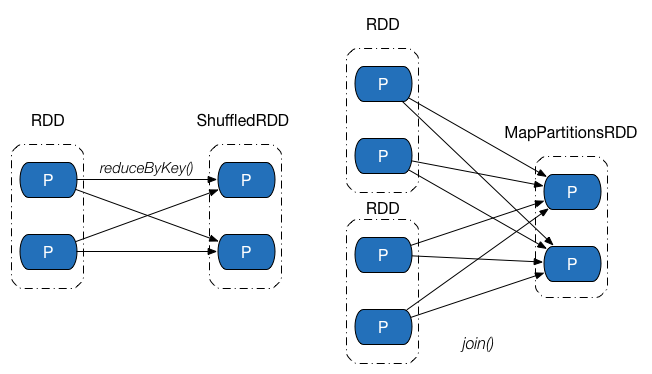
Shuffle 依賴的對應實現為ShuffleDependency 類,其實現比較複雜,主要通過以下成員完成:
rdd:用於表示 Shuffle 依賴中,子 RDD 所依賴的父 RDD。shuffleId:Shuffle 的 ID 編號,在一個 Spark 應用程式中,每個 Shuffle 的編號都是唯一的。shuffleHandle:Shuffle 控制代碼,ShuffleHandle內部一般包含 Shuffle ID、Mapper 的個數以及對應的 Shuffle 依賴,在執行ShuffleMapTask時候,任務可以通過ShuffleManager獲取得到該控制代碼,並進一步得到 Shuffle 相關資訊。partitioner:分割槽器,用於決定 Shuffle 過程中 Reducer 的個數(實際上是子 RDD 的分割槽個數)以及 Map 端的一條資料記錄應該分配給哪一個 Reducer,也可以被用在CoGroupedRDD中,確定父 RDD 與子 RDD 之間的依賴關係型別。serializer:序列化器。用於 Shuffle 過程中 Map 端資料的序列化和 Reduce 端資料的反序列化。KeyOrdering:鍵值排序策略,用於決定子 RDD 的一個分割槽內,如何根據鍵值對 型別資料記錄進行排序。Aggregator:聚合器,內部包含了多個聚合函式,比較重要的函式有createCombiner:V => C,mergeValue: (C, V) => C以及mergeCombiners: (C, C) => C。例如,對於groupByKey操作,createCombiner表示把第一個元素放入到集合中,mergeValue表示一個元素新增到集合中,mergeCombiners表示把兩個集合進行合併。這些函式被用於 Shuffle 過程中資料的聚合。mapSideCombine:用於指定 Shuffle 過程中是否需要在 map 端進行 combine 操作。如果指定該值為true,由於 combine 操作需要用到聚合器中的相關聚合函式,因此Aggregator不能為空,否則 Apache Spark 會丟擲異常。例如:groupByKey轉換操作對應的ShuffleDependency中,mapSideCombine = false,而reduceByKey轉換操作中,mapSideCombine = true。
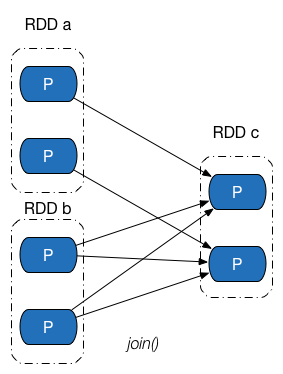
依賴關係是兩個 RDD 之間的依賴,因此若一次轉換操作中父 RDD 有多個,則可能會同時包含窄依賴和 Shuffle 依賴,下圖所示的 Join 操作,RDD a 和 RDD c 採用了相同的分割槽器,兩個 RDD 之間是窄依賴,Rdd b 的分割槽器與 RDD c 不同,因此它們之間是 Shuffle 依賴,具體實現可參見 CoGroupedRDD 類的 getDependencies 方法。這裡能夠再次發現:一個依賴對應的是兩個 RDD,而不是一次轉換操作。
2.2.3 依賴與容錯機制
介紹完依賴的類別和實現之後,回過頭來,從分割槽的角度繼續探究 Apache Spark 是如何通過依賴關係來實現容錯機制的。下圖給出了一張依賴關係圖,fileRDD 經歷了 map、reduce 以及filter 三次轉換操作,得到了最終的 RDD,其中,map、filter 操作對應的依賴為窄依賴,reduce 操作對應的是 Shuffle 依賴。
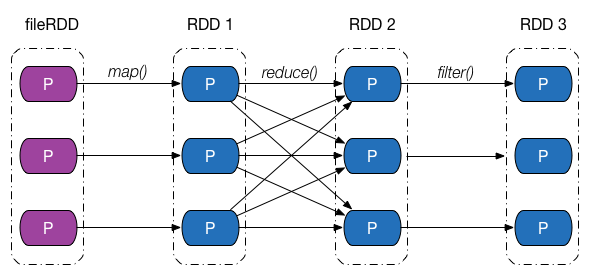
假設最終 RDD 第一塊分割槽內的資料因為某些原因丟失了,由於 RDD 內的每一個分割槽都會記錄其對應的父 RDD 分割槽的資訊,因此沿著下圖所示的依賴關係往回走,我們就能找到該分割槽資料最終來源於 fileRDD 的所有分割槽,再沿著依賴關係往後計算路徑中的每一個分割槽資料,即可得到丟失的分割槽資料。
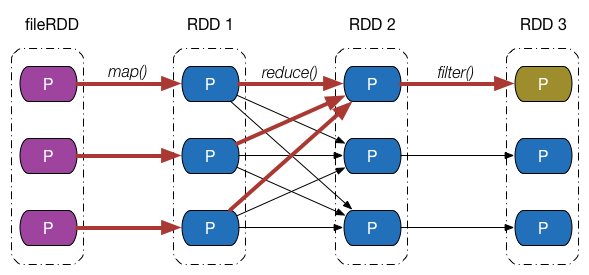
這個例子並不是特別嚴謹,按照我們的思維,只有執行了持久化,儲存在儲存介質中的 RDD 分割槽才會出現數據丟失的情況,但是上例中最終的 RDD 並沒有執行持久化操作。事實上,Apache Spark 將沒有被持久化資料重新被計算,以及持久化的資料第一次被計算,也等價視為資料“丟失”,在 1.7 節中我們會看到這一點。
2.2.4 依賴與平行計算
在上一節中我們看到,在 RDD 中,可以通過**計算鏈(Computing Chain)**來計算某個 RDD 分割槽內的資料,我們也知道分割槽是平行計算的基本單位,這時候可能會有一種想法:能否把 RDD 每個分割槽內資料的計算當成一個並行任務,每個並行任務包含一個計算鏈,將一個計算鏈交付給一個 CPU 核心去執行,叢集中的 CPU 核心一起把 RDD 內的所有分割槽計算出來。
答案是可以,這得益於 RDD 內部分割槽的資料依賴相互之間並不會干擾,而 Apache Spark 也是這麼做的,但在實現過程中,仍有很多實際問題需要去考慮。進一步觀察窄依賴、Shuffle 依賴在做平行計算時候的異同點。
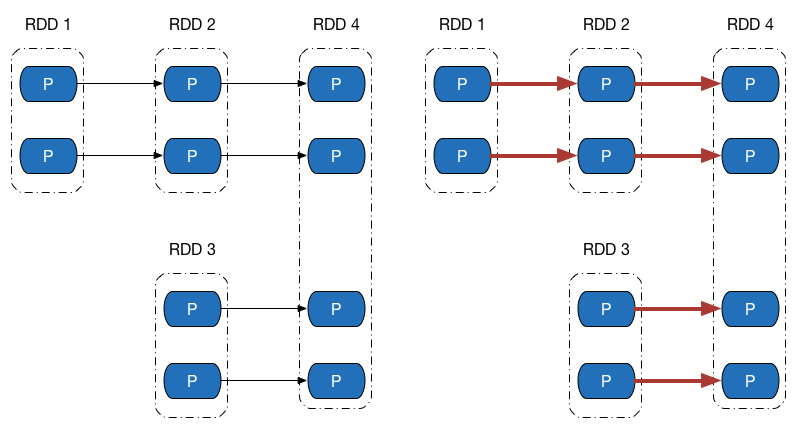
先來看下方左側的依賴圖,依賴圖中所有的依賴關係都是窄依賴(包括一對一依賴和範圍依賴),可以看到,不僅計算鏈是獨立不干擾的(所以可以平行計算),所有計算鏈內的每個分割槽單元的計算工作也不會發生重複,如右側的圖所示。這意味著除非執行了持久化操作,否則計算過程中產生的中間資料我們沒有必要保留 —— 因為當前分割槽的資料只會給計算鏈中的下一個分割槽使用,而不用專門保留給其他計算鏈使用。
再來觀察 Shuffle 依賴的計算鏈,如圖下方左側的圖中,既有窄依賴,又有 Shuffle 依賴,由於 Shuffle 依賴中,子 RDD 一個分割槽的資料依賴於父 RDD 內所有分割槽的資料,當我們想計算末 RDD 中一個分割槽的資料時,Shuffle 依賴處需要把父 RDD 所有分割槽的資料計算出來,如右側的圖所示(紫色表示最後兩個分割槽計算鏈共同經過的地方) —— 而這些資料,在計算末 RDD 另外一個分割槽的資料時候,同樣會被用到。
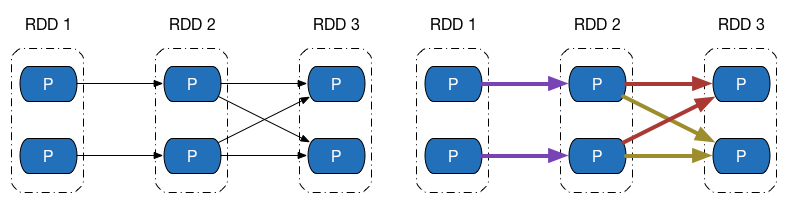
如果我們做到計算鏈的平行計算的話,這就意味著,要麼 Shuffle 依賴處父 RDD 的資料在每次需要使用的時候都重複計算一遍,要麼想辦法把父 RDD 資料儲存起來,提供給其餘分割槽的資料計算使用。
Apache Spark 採用的是第二種辦法,但儲存資料的方法可能與想象中的會有所不同,Spark 把計算鏈從 Shuffle 依賴處斷開,劃分成不同的階段(Stage),階段之間存在依賴關係(其實就是 Shuffle 依賴),從而可以構建一張不同階段之間的有向無環圖(DAG)。
2.3 RDD 計算函式
todo compute
2.4 RDD 分割槽器
todo partiner
2.5 RDD 血緣
todo lineage
參考
https://spark.apache.org/docs/latest/rdd-programming-guide.html#rdd-operations
https://ihainan.gitbooks.io/spark-source-code/content/section1/rddPartitions.html