
四種檢測異常值的常用技術簡述
摘要: 本文介紹了異常值檢測的常見四種方法,分別為Numeric Outlier、Z-Score、DBSCAN以及Isolation Forest
在訓練機器學習演算法或應用統計技術時,錯誤值或異常值可能是一個嚴重的問題,它們通常會造成測量誤差或異常系統條件的結果,因此不具有描述底層系統的特徵。實際上,最佳做法是在進行下一步分析之前,就應該進行異常值去除處理。
在某些情況下,異常值可以提供有關整個系統中區域性異常的資訊;因此,檢測異常值是一個有價值的過程,因為在這個工程中,可以提供有關資料集的附加資訊。
目前有許多技術可以檢測異常值,並且可以自主選擇是否從資料集中刪除。在這篇博文中,將展示KNIME分析平臺中四種最常用的異常值檢測的技術。
資料集和異常值檢測問題
本文用於測試和比較建議的離群值檢測技術的資料集來源於航空公司資料集,該資料集包括2007年至2012年間美國國內航班的資訊,例如出發時間、到達時間、起飛機場、目的地機場、播出時間、出發延誤、航班延誤、航班號等。其中一些列可能包含異常值。
從原始資料集中,隨機提取了2007年和2008年從芝加哥奧黑爾機場(ORD)出發的1500次航班樣本。
為了展示所選擇的離群值檢測技術是如何工作的,將專注於找出機場平均到達延誤的異常值,這些異常值是在給定機場降落的所有航班上計算的。我們正在尋找那些顯示不尋常的平均到達延遲時間的機場。
四種異常值檢測技術
數字異常值|Numeric Outlier
數字異常值方法是一維特徵空間中最簡單的非引數異常值檢測方法,異常值是通過IQR(InterQuartile Range)計算得的。
計算第一和第三四分位數(Q1、Q3),異常值是位於四分位數範圍之外的資料點x i:
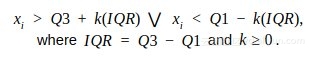
使用四分位數乘數值k=1.5,範圍限制是典型的上下晶須的盒子圖。這種技術是使用KNIME Analytics Platform內建的工作流程中的Numeric Outliers節點實現的(見圖1)。
Z-score
Z-score是一維或低維特徵空間中的引數異常檢測方法。該技術假定資料是高斯分佈,異常值是分佈尾部的資料點,因此遠離資料的平均值。距離的遠近取決於使用公式計算的歸一化資料點z i的設定閾值Zthr:
![]()
其中xi是一個數據點,μ是所有點xi的平均值,δ是所有點xi的標準偏差。
然後經過標準化處理後,異常值也進行標準化處理,其絕對值大於Zthr:
![]()
Zthr值一般設定為2.5、3.0和3.5。該技術是使用KNIME工作流中的行過濾器節點實現的(見圖1)。
DBSCAN
該技術基於DBSCAN聚類方法,DBSCAN是一維或多維特徵空間中的非引數,基於密度的離群值檢測方法。
在DBSCAN聚類技術中,所有資料點都被定義為核心點(Core Points)、邊界點(Border Points)或噪聲點(Noise Points)。
- 核心點是在距離ℇ內至少具有最小包含點數(minPTs)的資料點;
- 邊界點是核心點的距離ℇ內鄰近點,但包含的點數小於最小包含點數(minPTs);
- 所有的其他資料點都是噪聲點,也被標識為異常值;
從而,異常檢測取決於所要求的最小包含點數、距離ℇ和所選擇的距離度量,比如歐幾里得或曼哈頓距離。該技術是使用圖1中KNIME工作流中的DBSCAN節點實現的。
孤立森林|Isolation Forest
該方法是一維或多維特徵空間中大資料集的非引數方法,其中的一個重要概念是孤立數。
孤立數是孤立資料點所需的拆分數。通過以下步驟確定此分割數:
- 隨機選擇要分離的點“a”;
- 選擇在最小值和最大值之間的隨機資料點“b”,並且與“a”不同;
- 如果“b”的值低於“a”的值,則“b”的值變為新的下限;
- 如果“b”的值大於“a”的值,則“b”的值變為新的上限;
- 只要在上限和下限之間存在除“a”之外的資料點,就重複該過程;
與孤立非異常值相比,它需要更少的分裂來孤立異常值,即異常值與非異常點相比具有更低的孤立數。因此,如果資料點的孤立數低於閾值,則將資料點定義為異常值。
閾值是基於資料中異常值的估計百分比來定義的,這是異常值檢測演算法的起點。有關孤立森林技術影象的解釋,可以在此找到詳細資料。
通過在Python Script中使用幾行Python程式碼就可以實現該技術。
from sklearn.ensemble import IsolationForest
import pandas as pd
clf = IsolationForest(max_samples=100, random_state=42)
table = pd.concat([input_table['Mean(ArrDelay)']], axis=1)
clf.fit(table)
output_table = pd.DataFrame(clf.predict(table))```python
Python Script節點是KNIME Python Integration的一部分,它允許我們將Python程式碼編寫/匯入到KNIME工作流程。
在KNIME工作流程中實施
KNIME Analytics Platform是一個用於資料科學的開源軟體,涵蓋從資料攝取和資料混合、資料視覺化的所有資料需求,從機器學習演算法到資料應用,從報告到部署等等。它基於用於視覺化程式設計的圖形使用者介面,使其非常直觀且易於使用,大大減少了學習時間。
此外,它被設計為對不同的資料格式、資料型別、資料來源、資料平臺以及外部工具(例如R和Python)開放,還包括許多用於分析非結構化資料的擴充套件,如文字、影象或圖形。
KNIME Analytics Platform中的計算單元是小彩色塊,名為“節點”。一個接一個地組裝管道中的節點,實現資料處理應用程式。管道也被稱為“工作流程”。
鑑於所有這些特性,本文選擇它來實現上述的四種異常值檢測技術。圖1中展示了異常值檢測技術的工作流程。工作流程:
- 1.讀取Read data metanode中的資料樣本;
- 2.進行資料預處理並計算Preproc元節點內每個機場的平均到達延遲;
- 3.在下一個名為密度延遲的元節點中,對資料進行標準化,並將標準化平均到達延遲的密度與標準正態分佈的密度進行對比;
- 4.使用四種選定的技術檢測異常值;
- 5.使用KNIME與Open Street Maps的整合,在MapViz元節點中顯示美國地圖中的異常值機場。
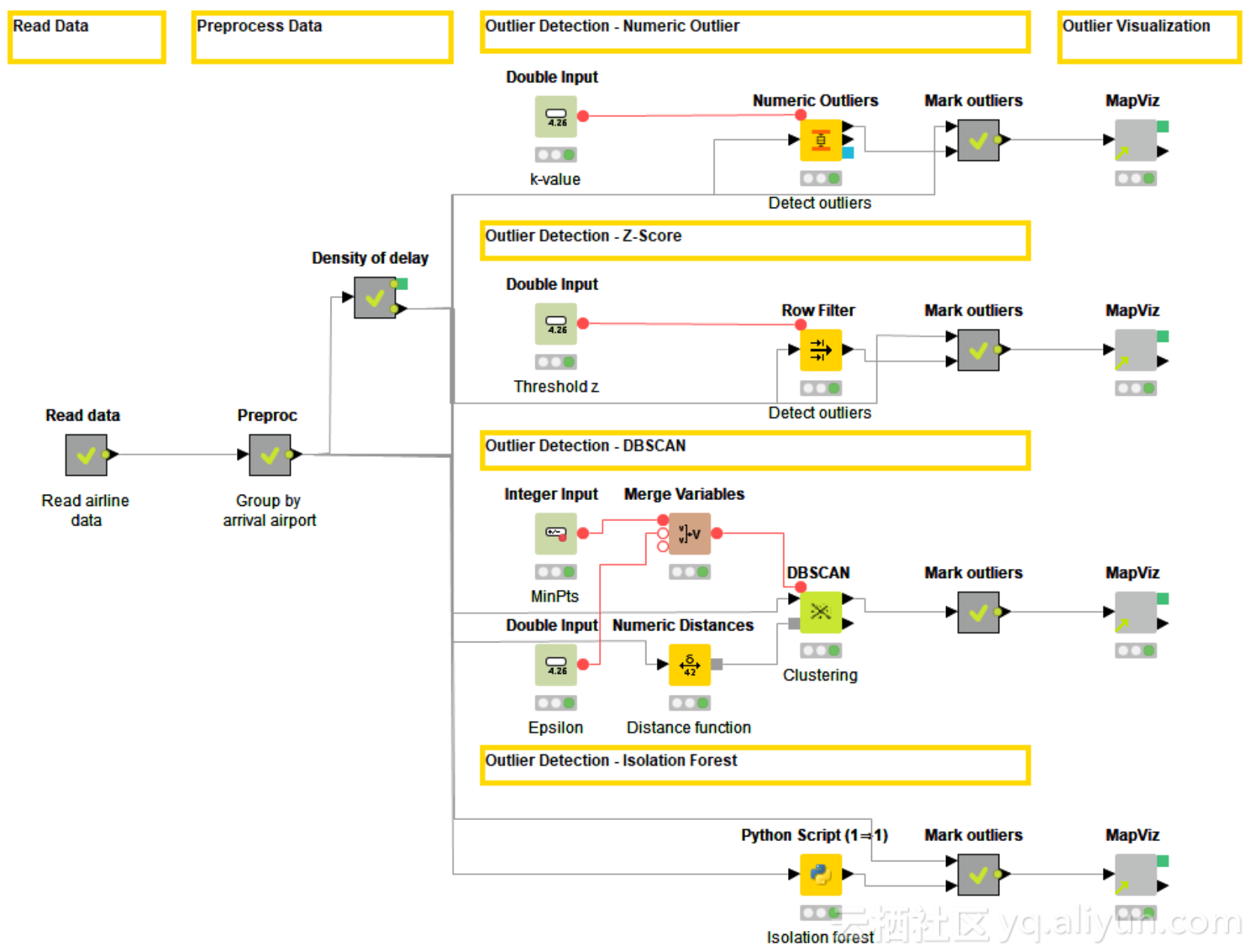
圖1:實施四種離群值檢測技術的工作流程:數字異常值、Z-score、DBSCAN以及孤立森林
檢測到的異常值
在圖2-5中,可以看到通過不同技術檢測到的異常值機場。其中。藍色圓圈表示沒有異常行為的機場,而紅色方塊表示具有異常行為的機場。平均到達延遲時間定義的大小了記。
一些機場一直被四種技術確定為異常值:斯波坎國際機場(GEG)、伊利諾伊大學威拉德機場(CMI)和哥倫比亞大都會機場(CAE)。斯波坎國際機場(GEG)具有最大的異常值,平均到達時間非常長(180分鐘)。然而,其他一些機場僅能通過一些技術來識別、例如路易斯阿姆斯特朗新奧爾良國際機場(MSY)僅被孤立森林和DBSCAN技術所發現。
對於此特定問題,Z-Score技術僅能識別最少數量的異常值,而DBSCAN技術能夠識別最大數量的異常值機場。且只有DBSCAN方法(MinPts = 3/ℇ= 1.5,歐幾里德距離測量)和孤立森林技術(異常值的估計百分比為10%)在早期到達方向發現異常值。

圖2:通過數字異常值技術檢測到的異常值機場
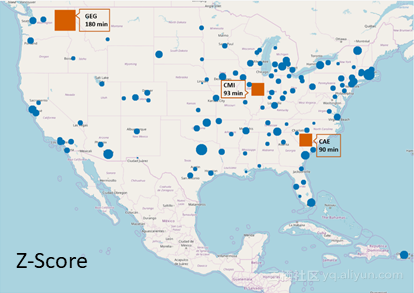
圖3:通過z-score技術檢測到的異常機場
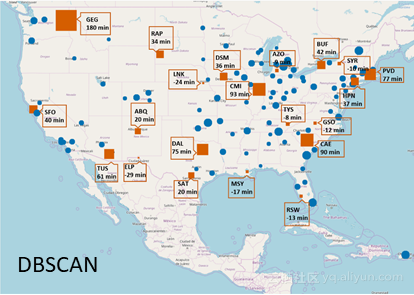
圖4:DBSCAN技術檢測到的異常機場
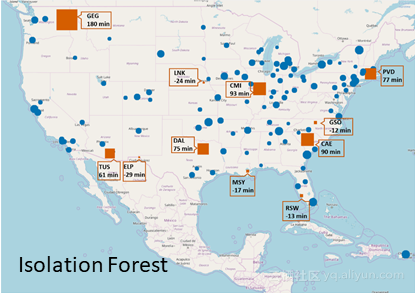
圖5:孤立森林技術檢測到的異常機場
總結
本文在一維空間中描述並實施了四種不同的離群值檢測技術:2007年至2008年間所有美國機場的平均到達延遲。研究的四種技術分別是Numeric Outlier、Z-Score、DBSCAN和Isolation Forest方法。其中一些用於一維特徵空間、一些用於低維空間、一些用於高維空間、一些技術需要標準化和檢查維度的高斯分佈。而有些需要距離測量,有些需要計算平均值和標準偏差。有三個機場,所有異常值檢測技術都能將其識別為異常值。但是,只有部分技術(比如,DBSCAN和孤立森林)可以識別分佈左尾的異常值,即平均航班早於預定到達時間到達的那些機場。因此,應該根據具體問題選擇合適的檢測技術。