
GC調優二:調優基本概念
一、核心概念
首先,我們來觀察一條工廠的生產線,該生產線主要用於將自行車各個元件拼裝成一輛完整的自行車。通過觀察我們發現一輛自行車從車架上生產線開始裝配,直到拼裝成完整自行車後下線的整個耗時為4小時,如下圖所示。
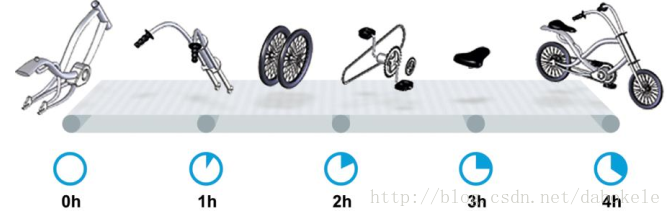
並且,我們還觀察到這條生產線上每分鐘就會有一輛組裝好的自行車下線,該生產線每天24小時不間斷執行。如果忽略掉例如生產線維護等時間成本,可以算出,該生產線在一個小時的時間內可以組裝60輛自行車下線。
通過上面的觀察,我們提煉出該工廠的兩個指標:工廠的延遲(Latency)和工廠的吞吐量(Throughput)。
工廠的延遲:4小時
工廠的吞吐量:60輛自行車每小時
對於一個系統來說,其延遲可以是從納秒到千年的任意值,吞吐量表示一個系統在單位時間內完成的操作。
假設該生產線已經以這裡提到的延遲和吞吐量穩定運行了幾個月。現在隨著市場需求的增長,我們需要讓工廠能夠生產出兩倍的自行車。即原來每天能生產60 * 24 = 1440輛,現在需要每天生產1440 * 2 = 2880輛才能滿足市場需求。以該工廠目前的效能來看,是無法滿足這一需求的,這就需要我們想辦法對生產線進行調優。
可能首先想到的是擴充套件整個工廠的容量(Capacity),即增加投入資金,新建一條相同的生產線,新生產線的延遲和吞吐量和現有生產線保持一致,這樣就能夠滿足每天生產2880輛自行車的需求了。如下圖所示,
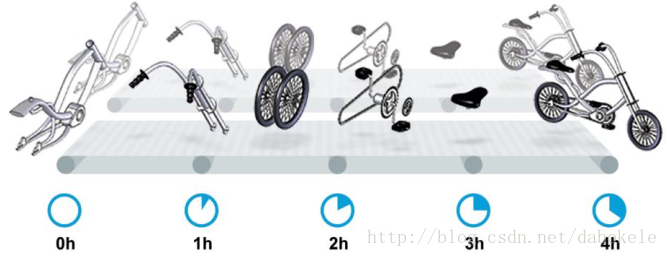
工廠容量擴充一倍後,整個工廠的吞吐量也由原來的60輛每小時變成了120輛每小時,而延遲並沒有變化。在本次調節過程中,我們只是提高了吞吐量,而沒有對延遲進行任何優化。這種調整由於新增了一條生產線,無形中也提高了工廠的硬體成本的投入。
那麼,假如我們換一個角度來考慮,如果將每輛自行車的裝配時間由4小時縮短到2小時,那麼整個工廠的吞吐量也能翻倍。這種效能上的調節比直接投入一條新的生產線更能讓人接受。
其實類似於自行車生產線,在軟體工程領域如果需要提高一個系統的吞吐量,也是從這兩個角度來考慮的,要麼投入更多的硬體成本,要麼提高系統性能,縮短延遲時間。
從上面的生產線的例子中我們也提煉出了三個重要概念,延遲(Latency),吞吐量(Throughput),系統容量(Capacity)。接下來會從這三個方面進行分析。
1、延遲(Latency)
正常來說,我們談到一個系統的延遲時,一般會提出類似於如下的要求:
(1)所有使用者的交易必須在10秒內得到響應
(2)90%的訂單必須在3秒內處理完成
(3)推薦的商品必須在100ms內展示在使用者面前
當遇到如上這種效能調優要求時,我們需要保證整個系統執行時由於GC導致的交易暫停時間不能過長,因為系統不可避免的還會有一些其他開銷,比如外部資料來源的互動時間,鎖競爭以及其他安全驗證等操作。這就要求我們儘量壓縮GC的暫停時間。
假設某個系統要求90%的交易需要在1秒內完成,並且交易最長處理時間不能超過10秒。由於整個系統的延遲不僅只是由於GC導致的暫停,所以我們需要GC導致的系統延遲不能超過10%。基於這個要求,那麼我們需要確保90%的GC暫停時間需要在100毫秒內完成,並且不允許任何GC暫停時間超過1秒鐘。為了簡單起見,我們不考慮在一次交易過程中發生多次GC的情況。
當確定好上述調優需求後,我們下一步就需要去計算GC暫停時間了。我們可以使用多種工具來獲取這些指標,有關這些工具可以參考《六、GC調優工具》。在本節中,我們使用GC日誌來獲取GC暫停時間。看下面這段日誌示例
2015-06-04T13:34:16.974-0200: 2.578: [Full GC (Ergonomics) [PSYoungGen: 93677K-
>70109K(254976K)] [ParOldGen: 499597K->511230K(761856K)] 593275K->581339K(1016832K),
[Metaspace: 2936K->2936K(1056768K)], 0.0713174 secs] [Times: user=0.21 sys=0.02,
real=0.07 secs上面這一日誌片段反應了在2015年6月4日13:34:16,在該JVM啟動2578毫秒後觸發的一次GC動作。這一GC動作導致了應用中斷了0.0713174秒。雖然在多個CPU核上導致了總共210毫秒的時間,但是由於本例是在一臺多核伺服器上進行的並行GC,所以我們只需要考慮整個應用執行緒被暫停的總時間,所以實際暫停時間約為70毫秒。滿足效能調優要求中提到的100毫秒的要求。
繼續分析更多的GC暫停日誌,就可以統計出該系統的GC是否滿足調優要求。
2、吞吐量(Throughput)
系統的吞吐量的要求與上面提到的延遲要求是不同的。對於系統的吞吐量,一般會提出類似如下的需求:
(1)系統必須能每天處理100萬條交易
(2)系統必須能夠支援1000個使用者同時線上,在5~10秒的時間內同時進行A,B或C操作
(3)系統必須每週在不超過6個小時的時間內對所有消費者的消費記錄進行分析統計,這個時間視窗定在每週日晚上12點到6點
系統延遲關注於單次操作的效能,而系統吞吐量則關注系統的整體效能。所以在調節系統吞吐量時,我們需要關注系統總的GC時間。由於之前提到的相同原因,我們仍然規定GC時間不能超過總耗時的10%。
假設某個系統每分鐘需要處理1000次交易,那麼按照10%的要求,我們的系統在這一分鐘內能夠進行GC的總時間應該不能超過6秒鐘。
基於上面這一要求,我們下一步就來分析系統的GC時間消耗。我們仍然看以下這一份GC日誌:
2015-06-04T13:34:16.974-0200: 2.578: [Full GC (Ergonomics) [PSYoungGen: 93677K-
>70109K(254976K)] [ParOldGen: 499597K->511230K(761856K)] 593275K->581339K(1016832K),
[Metaspace: 2936K->2936K(1056768K)], 0.0713174 secs] [Times: user=0.21 sys=0.02,
real=0.07 secs這次我們主要關注user和sys時間,而不是real時間。那麼我們可以得到,在這次GC暫停過程中這兩部分的總耗時為0.23秒。由於系統執行在多核伺服器上,這裡的0.23秒是所有核上的總暫停時間,整個系統的暫停時間為0.0713174秒,這個數值在後面的計算中會用到。
獲得了上面這些資訊後,我們接下來需要統計的是在這一分鐘內每次GC導致的總暫停時間。看看在這一分鐘內的總GC時間是否超過了規定的6秒鐘。
3、系統容量(Capacity)
系統容量是在上面提到的延遲需求以及吞吐量之外的硬體限制。這些硬體限制可以是如下形式,例如:
(1)系統必須部署在記憶體不超過512MB的安卓裝置上
(2)系統必須部署在Amazon EC2上。並且硬體效能不能超過(8G, 4核)
(3)花費在Amazon EC2上的月開支不能超過$12000
我們總是希望對給定的硬體環境充分利用,在給定的硬體環境基礎上實現最優效能。
所以,綜合上面這三部分,一般來說,對一個系統提出的完整效能要求如下,下面這一段基本上就是我們日常生活中耳熟能詳的了。
(1)系統必須部署在記憶體不超過512MB的安卓裝置上
(2)系統必須部署在Amazon EC2上。並且硬體效能不能超過(8G, 4核)
(3)花費在Amazon EC2上的月開支不能超過$12000
(4)所有使用者的交易必須在10秒內得到響應
(5)90%的訂單必須在3秒內處理完成
(6)推薦的商品必須在100ms內展示在使用者面前
(7)系統必須能每天處理100萬條交易
(8)系統必須能夠支援1000個使用者同時線上,在5~10秒的時間內同時進行A,B或C操作
(9)系統必須每週在不超過6個小時的時間內對所有消費者的消費記錄進行分析統計,這個時間視窗定在每週日晚上12點到6點
二、示例
到這裡,我們已經知道了效能調優時的三個衡量維度了。接下來我們以例項形式來實現對系統性能的調節。
示例程式碼如下:
public class Producer implements Runnable {
private static ScheduledExecutorService executorService =
Executors. newScheduledThreadPool( 2) ;
private Deque< byte []> deque ;
private int objectSize ;
private int queueSize ;
public Producer( int objectSize, int ttl) {
this . deque = new ArrayDeque<byte []>() ;
this. objectSize = objectSize;
this. queueSize = ttl * 1000 ;
}
@Override
public void run () {
for ( int i = 0 ; i < 100 ; i++) {
deque .add( new byte[ objectSize ]);
if ( deque .size() > queueSize ) {
deque.poll() ;
}
}
}
public static void main (String[] args) throws InterruptedException {
executorService.scheduleAtFixedRate (new Producer( 200 * 1024 * 1024 / 1000 , 5 ) , 0 ,
100, TimeUnit. MILLISECONDS) ;
executorService.scheduleAtFixedRate (new Producer( 50 * 1024 * 1024 / 1000, 120 ), 0 ,
100, TimeUnit. MILLISECONDS) ;
TimeUnit. MINUTES .sleep(10 ) ;
executorService.shutdownNow() ;
}
}上面這段程式碼每隔100毫秒會提交併執行兩個job,每隔job模擬特定的生命週期:建立物件,在一定時間內對該物件進行釋放,讓GC對這些記憶體空間進行回收。
執行時設定如下JVM引數
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps執行後可以看到如下格式的日誌資訊
2017-03-02T23:39:05.852+0800: 0.376: [GC [PSYoungGen: 98618K->15860K(114688K)] 98618K->91364K(375296K), 0.0512823 secs] [Times: user=0.09 sys=0.00, real=0.05 secs]
2017-03-02T23:39:06.251+0800: 0.775: [GC [PSYoungGen: 114650K->15838K(213504K)] 190154K->187102K(474112K), 0.0241185 secs] [Times: user=0.02 sys=0.03, real=0.02 secs]
2017-03-02T23:39:06.275+0800: 0.799: [Full GC [PSYoungGen: 15838K->0K(213504K)] [ParOldGen: 171264K->186865K(420864K)] 187102K->186865K(634368K) [PSPermGen: 3236K->3235K(21504K)], 0.0414808 secs] [Times: user=0.22 sys=0.00, real=0.04 secs]
2017-03-02T23:39:06.955+0800: 1.479: [GC [PSYoungGen: 197560K->15868K(213504K)] 384425K->388821K(634368K), 0.0381355 secs] [Times: user=0.05 sys=0.08, real=0.04 secs] 基於上面這些日誌資訊,我們可以從以下三個方面來進行優化
(1)確保GC暫停的最長時間不超過設定的某個閾值
(2)確保GC暫停總時間不超過設定的某個閾值
(3)在達到延長和吞吐量目標要求的情況下,儘可能少的使用硬體資源
首先,在不考慮系統延遲和吞吐量的情況下統計應用程式在不同堆記憶體和不同GC演算法情況下執行10分鐘的統計資訊,統計資訊包括可用率,最長暫停時間。
| 堆大小 | GC演算法 | 系統可用率 | 最長暫停時間 |
|---|---|---|---|
| -Xmx12g | -XX:UseConcMarkSweepGC | 89.8% | 560ms |
| -Xmx12g | -XX:UseParallelGC | 91.5% | 1104ms |
| -Xmx8g | -XX:UseConcMarkSweepGC | 66.3% | 1610ms |
1、Latency調優
現在我們給系統設定一個延遲閾值,所有job必須在1000毫秒內執行完成。如果我們知道job實際執行時間只要100毫秒,那麼我們的GC暫停時間就不能超過900毫秒了。我們只需要統計每次GC的最長暫停時間就可以得到結論了。
在上表中僅僅只有第一種引數設定情況達到了要求,最長暫停時間為560毫秒。那麼,我們在執行Producer應用時,就需要使用如下命令
java -Xmx12g -XX:UseConcMarkSweepGC Producer2、Throughput調優
現在假設我們需要每小時能處理13000000次操作。還是看一下上面的統計資訊。其中第二條,GC的暫停時間佔總執行時間的8.5%。基於以下條件我們進行計算,
(1)一個job在一個核上的執行時間為100毫秒
(2)那麼一個核在一分鐘內就能執行60000次操作(程式碼中每個job完成100次操作)
(3)一個小時內,一個核就能執行3600000次操作
(4)在有4個core的情況下,每小時就能執行14400000次操作
那麼如果按照應用可用時間為91.5%來計算的話,在
java -Xmx12g -XX:+UseParallelGC Producer情況下,一個小時可用執行13176000操作。
達到了吞吐量調優的要求,又不滿足延遲調優的要求了。在這裡最大暫停時間為1104毫秒,是最大暫停時間閾值的兩倍多。
3、Capacity調優
加入我們需要將應用部署在4核,可用記憶體不超過10G的機器上,那麼我們就只能選擇第三種JVM引數情況,使用8GB的記憶體了。在上表中,第三種情況的執行命令為
java -Xmx8g -XX:UseConcMarkSweepGC Producer 但是在這種情況下,Latency和Throughput的要求都得不到滿足了。
(1)在這種情況下CPU只有66.3%的時間可用,這樣的話,每小時能進行的運算元就會降到9547200
(2)延遲時間從560毫秒增加到1610毫秒
通過以上分析可以看到,對系統進行調優時是需要同時考慮三個維度的,在實際調優時,需要在這三個維度上選擇一個相對好的方案。