
debug-DMLIR-CVPR2017
python == 3.6.4
keras == 2.1.0
backend == 'theano'
VGG16_sequential.py
1.print()
2.
import os
os.environ['KERAS_BACKEND']='theano'
gllim.py
3.from sklearn.mixture import GMM GaussianMixture
test.py
4.import cPickle as pickle
PCA_init.py
5.
import os os.environ['KERAS_BACKEND']='theano'
deepMLIR.py
6.L166:def predict(self, (generator, n_predict)):
def predict(self,input):
(generator, n_predict)=input
7.L181:def evaluate(self, (generator, n_eval), l=WIDTH, pbFlag=PB_FLAG,printError=False):
def evaluate(self, input, l=WIDTH, pbFlag=PB_FLAG,printError=False): (generator, n_eval)=input
8.L24:
import os
os.environ['KERAS_BACKEND']='theano'
9.L15:ROOTPATH =str(sys.argv[1]) ‘dataSyn/’
10.L45:JOB = str(sys.argv[4]) ‘16’
11.VGG16_sequential.py L73:
tf的維度順序是(224,224,3)
theano的維度順序是(3,224,224)
- vgg16_weights.h5: KeyError: “Can’t open attribute (can’t locate attribute: ‘layer_names’)”
- vgg16_weights_th_dim_ordering_th_kernels.h5: train_txt = sys.argv[2] IndexError: list index out of range √√√√√√√√√√
- vgg16_weights_tf_dim_ordering_tf_kernels.h5 train_txt = sys.argv[2] IndexError: list index out of range
- vgg16_weights_th_dim_ordering_th_kernels_notop.h5 ValueError: You are trying to load a weight file containing 13 layers into amodel with 16 layers.
- vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5 ValueError: You are trying to load a weight file containing 13 layers into amodel with 16 layers.
12.L209:train_txt = sys.argv[2] test_txt = sys.argv[3]
train_txt = 'Annotations.txt'
test_txt = 'AnnotationsExtrem.txt'
13.data_generator.py
L280:Y.append(np.asarray(map(lambda x: float(x),currentline[1:])))
y = np.asarray(currentline[1:])
y = y.astype(np.float)
Y.append(y)
- ValueError: Error when checking : expected zero_padding2d_1_input to have shape (None, 224, 224, 3) but got array with shape (128, 3, 224,224)
14.VGG16_sequential.py L73:
tf的維度順序是(224,224,3)
theano的維度順序是(3,224,224)
- vgg16_weights.h5: KeyError: “Can’t open attribute (can’t locate attribute: ‘layer_names’)”
- vgg16_weights_th_dim_ordering_th_kernels.h5: ValueError: Error when checking : expected zero_padding2d_1_input to have shape (None, 224, 224, 3) but got array with shape (128, 3, 224, 224)
- vgg16_weights_tf_dim_ordering_tf_kernels.h5 ValueError: Error when checking : expected zero_padding2d_1_input to have shape (None, 224, 224, 3) but got array with shape (128, 3, 224, 224)
tensorflow不支援Python2.7…
pip install keras==1.1.0
15.修改os:VGG16_sequential.py,PCA_init.py,deepMLIR.py
backend == ‘tensorflow’
- vgg16_weights.h5: AttributeError: module ‘tensorflow’ has no attribute ‘pack’
16.tensorflow_beckend.py
L823:x = tf.reshape(x, tf.pack stack([-1, prod(shape(x)[1:])]))
AttributeError: module ‘tensorflow’ has no attribute ‘python’
放棄
17.pip install keras==2.1.0
backend==‘tensorflow’:
- vgg16_weights.h5: KeyError: “Can’t open attribute (can’t locate attribute: ‘layer_names’)”
- vgg16_weights_th_dim_ordering_th_kernels.h5: ValueError: Dimension 2 in both shapes must be equal, but are 3 and 64 for ‘Assign’ (op: ‘Assign’) with input shapes: [3,3,3,64], [3,3,64,3].
- vgg16_weights_tf_dim_ordering_tf_kernels.h5:ValueError: Error when checking : expected zero_padding2d_1_input to have shape (None, 224, 224, 3) but got array with shape (128, 3, 224, 224)
- vgg16_weights_in.h5 ValueError: Dimension 2 in both shapes must be equal, but are 3 and 64 for ‘Assign’ (op: ‘Assign’) with input shapes: [3,3,3,64], [3,3,64,3].
18.backend==‘theano’:
- vgg16_weights.h5: KeyError: “Can’t open attribute (can’t locate attribute: ‘layer_names’)”
- vgg16_weights_th_dim_ordering_th_kernels.h5: ValueError: Error when checking : expected zero_padding2d_1_input to have shape (None, 224, 224, 3) but got array with shape (128, 3, 224, 224)
- vgg16_weights_tf_dim_ordering_tf_kernels.h5 ValueError: Error when checking : expected zero_padding2d_1_input to have shape (None, 224, 224, 3) but got array with shape (128, 3, 224, 224)
- vgg16_weights_in.h5 ValueError: Error when checking : expected zero_padding2d_1_input to have shape (None, 224, 224, 3) but got array with shape (128, 3, 224, 224)
tf的維度順序是(224,224,3)
theano的維度順序是(3,224,224)
電腦崩了…中間記錄沒儲存…回顧一下,可能有遺漏…:
19.backend==‘tensorflow’ , 最後VGG16_sequential.py L73 用 vgg16_weights_in.h5
修改:VGG16_sequential.py,PCA_init.py,deepMLIR.py
import keras
keras.backend.set_image_data_format('channels_first')
- AttributeError:‘Session’object has no attribute ‘list_devices’
20.pip install keras==2.0.7
- 不報錯就跳出程式了:
- Process finished with exit code -1073740791 (0xC0000409)
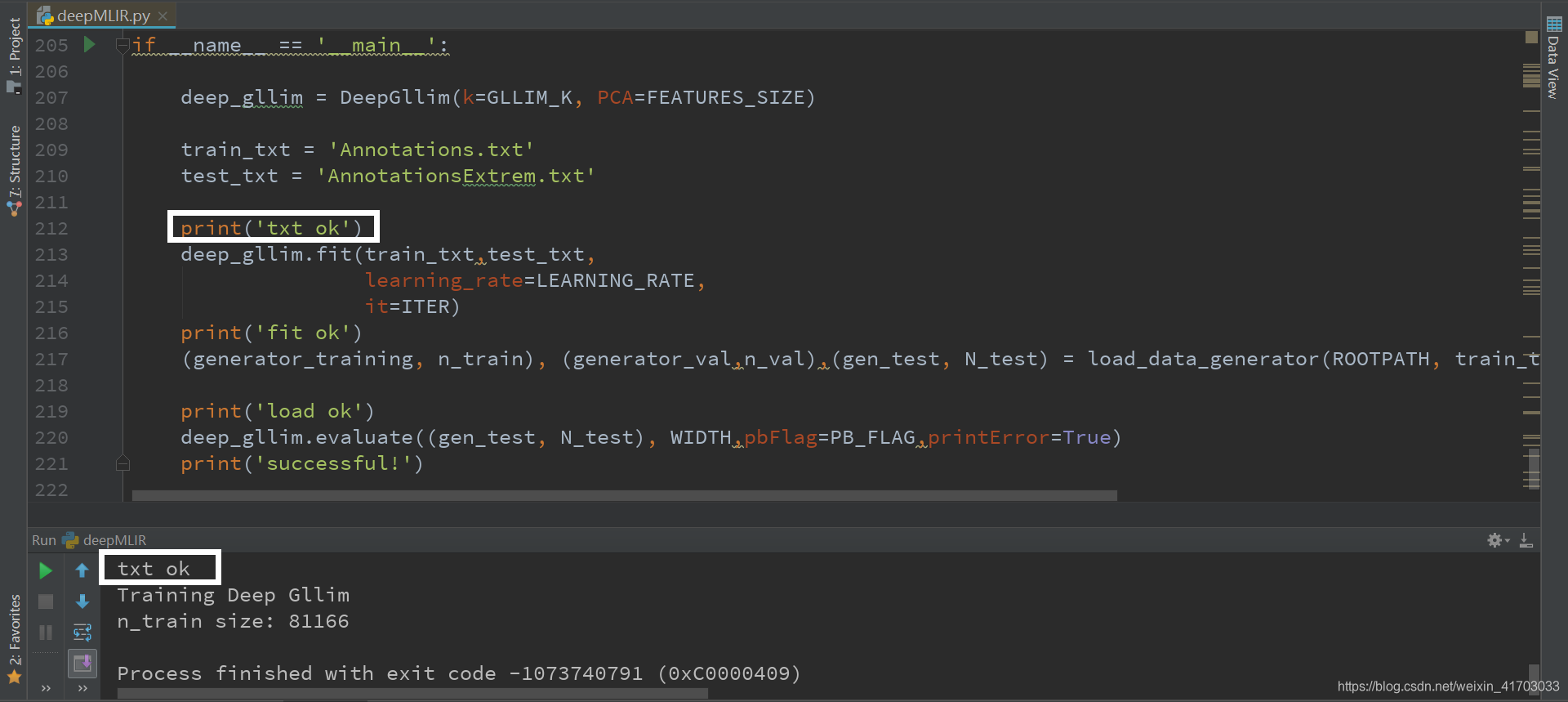
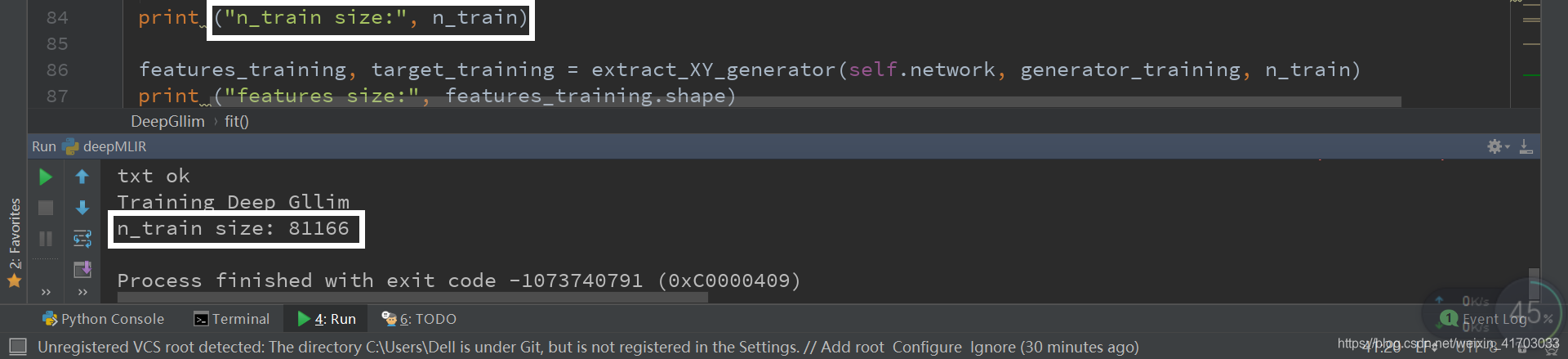
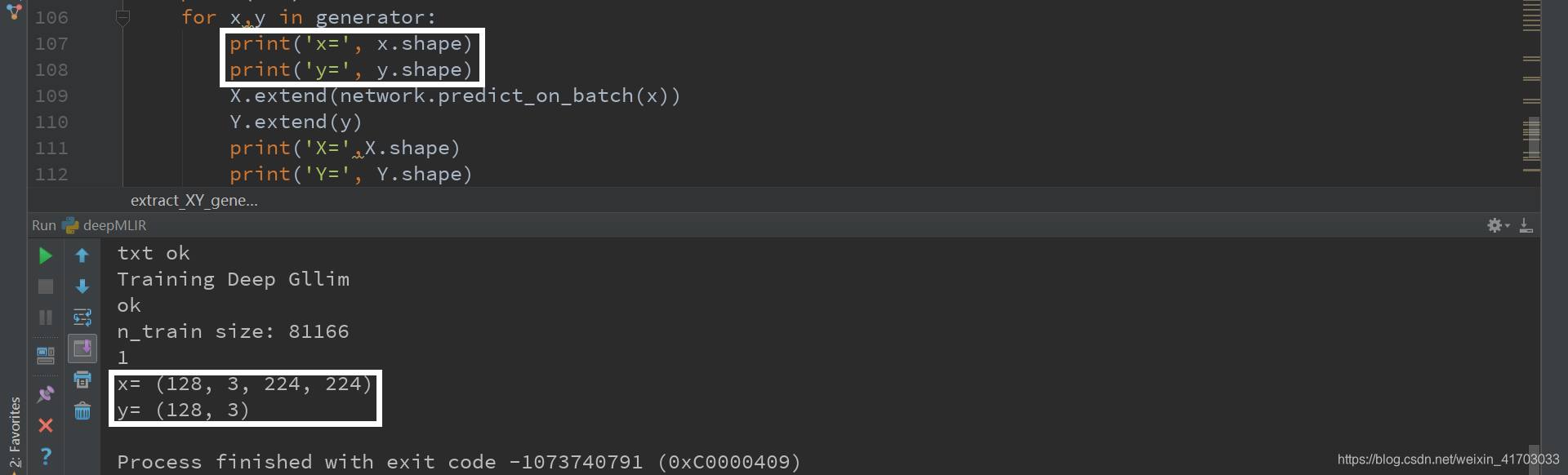
21.列印看看
天吶 原來的程式都變成其他東西了…

22.列印並trace
deepMLIR.py —— main()
deepMLIR.py —— deep_gllim.fit()
VGG16_sequential.py —— extract_XY_generator()
VGG16_sequential.py 
deepMLIR.py

deepMLIR.py 沒有predict_on_batch()???
23.VGG16_sequential.py L111:network.predict_on_batch (x)
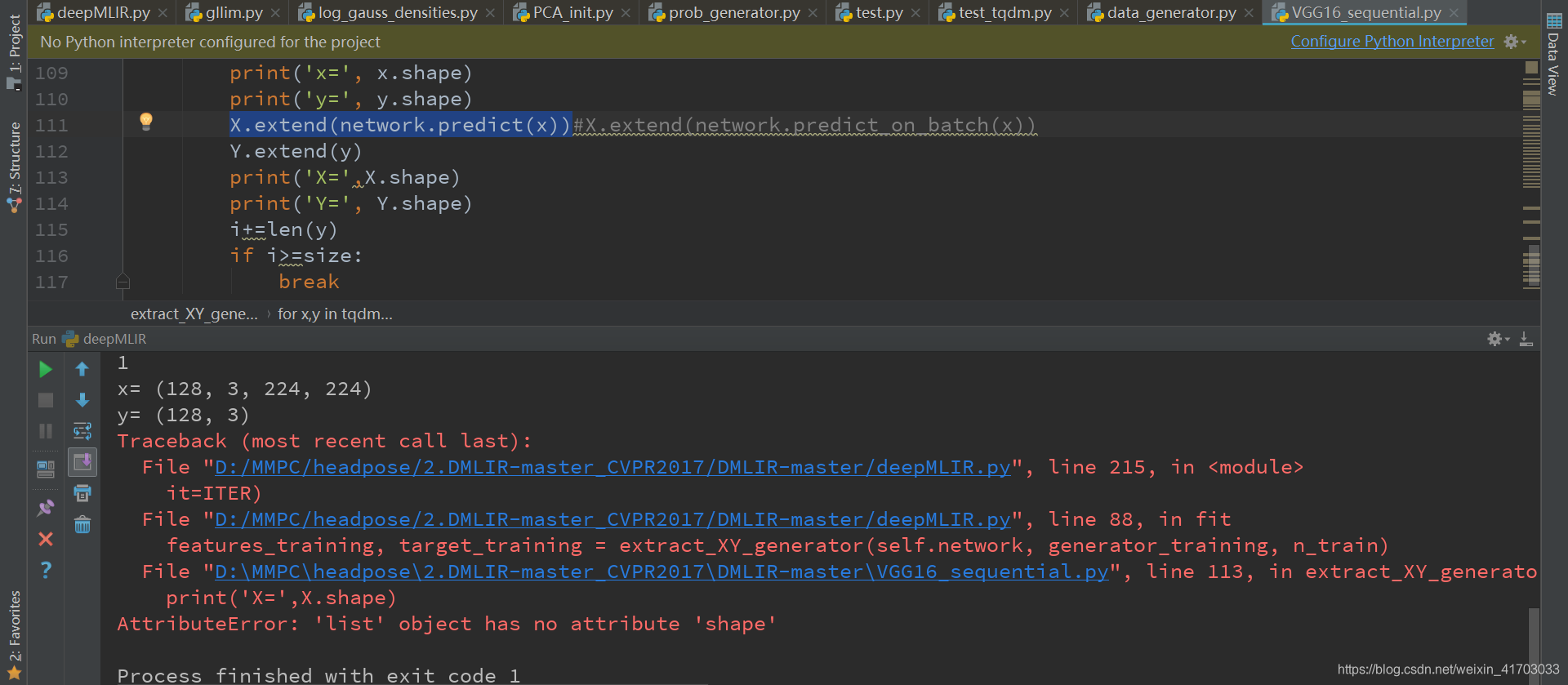
23.VGG16_sequential.py
import time
import pqdm
L108:for x,y in tqdm.tqdm(generator):
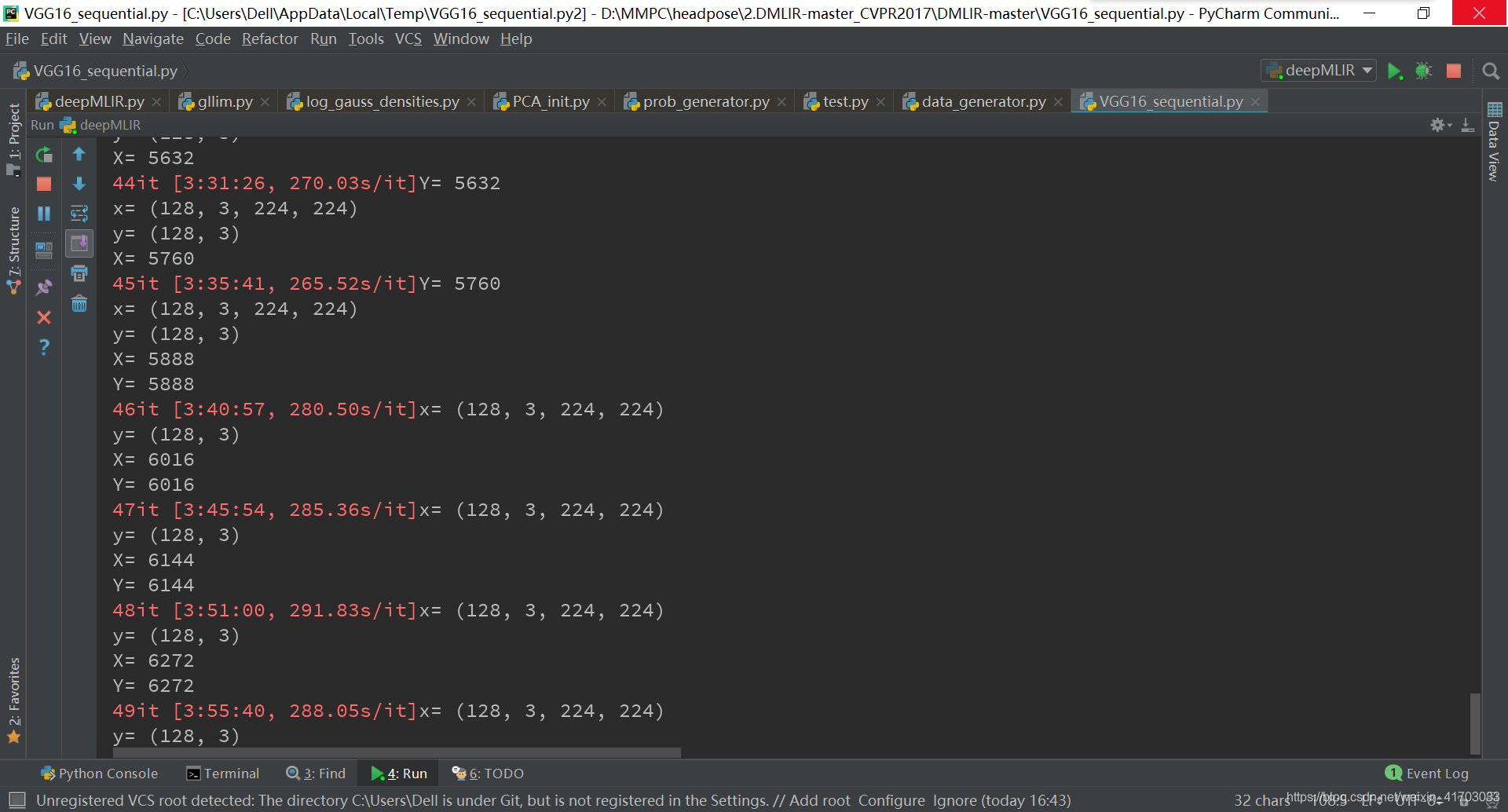
已經跑了4h了…問了學姐說vgg16訓練5w張圖要一個月…

23.那就先取一小部分跑一跑看看發生什麼吧~
deepMLIR.py L209
train_txt = 'Annotations_train.txt'
test_txt = 'Annotations_test.txt'
Annotations_train.txt:取Annotations.txt中的前128個數據
Annotations_test.txt:取Annotations.txt中的前10個數據+129~139個數據
- ValueError: n_components=512 must be between 0 and min(n_samples,
n_features)=102 with svd_solver=‘full’
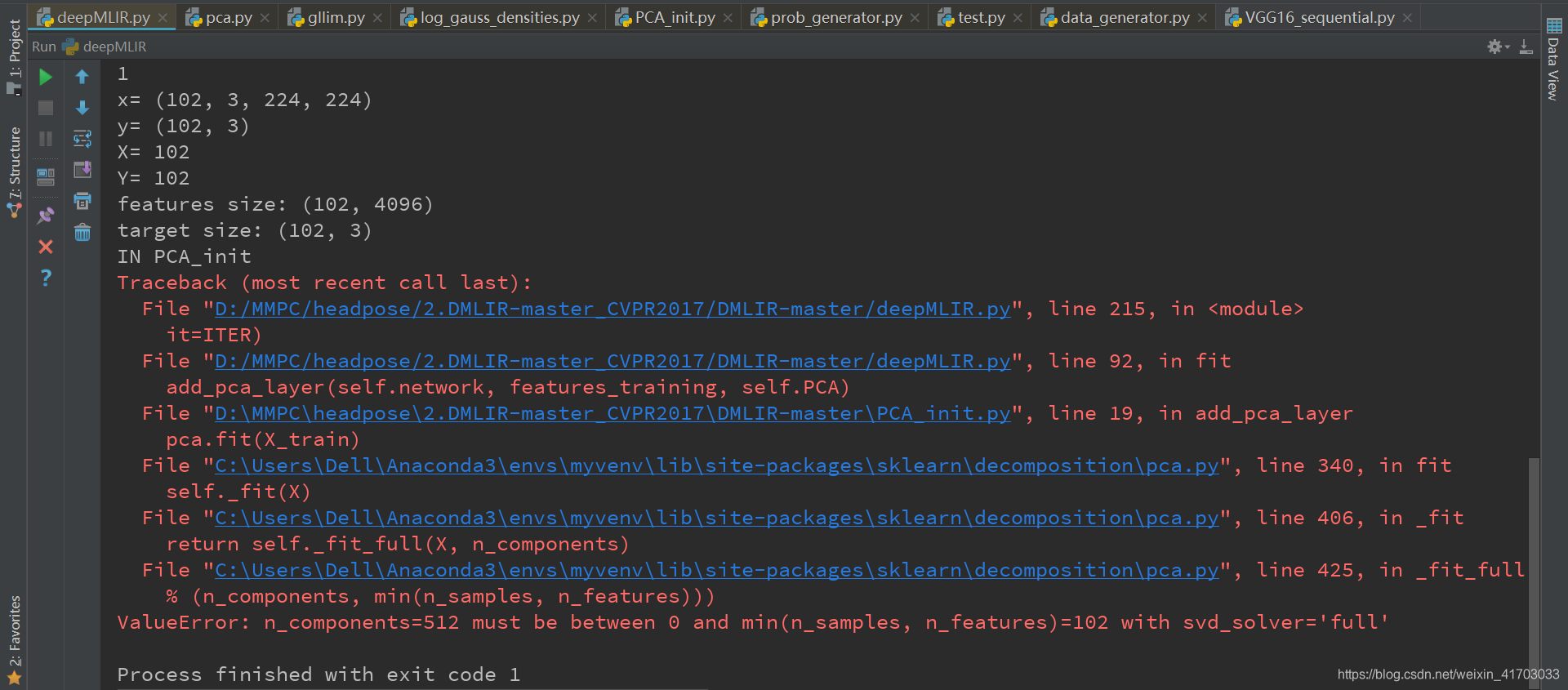
24.Annotations_train.txt:取Annotations.txt中的前384個數據
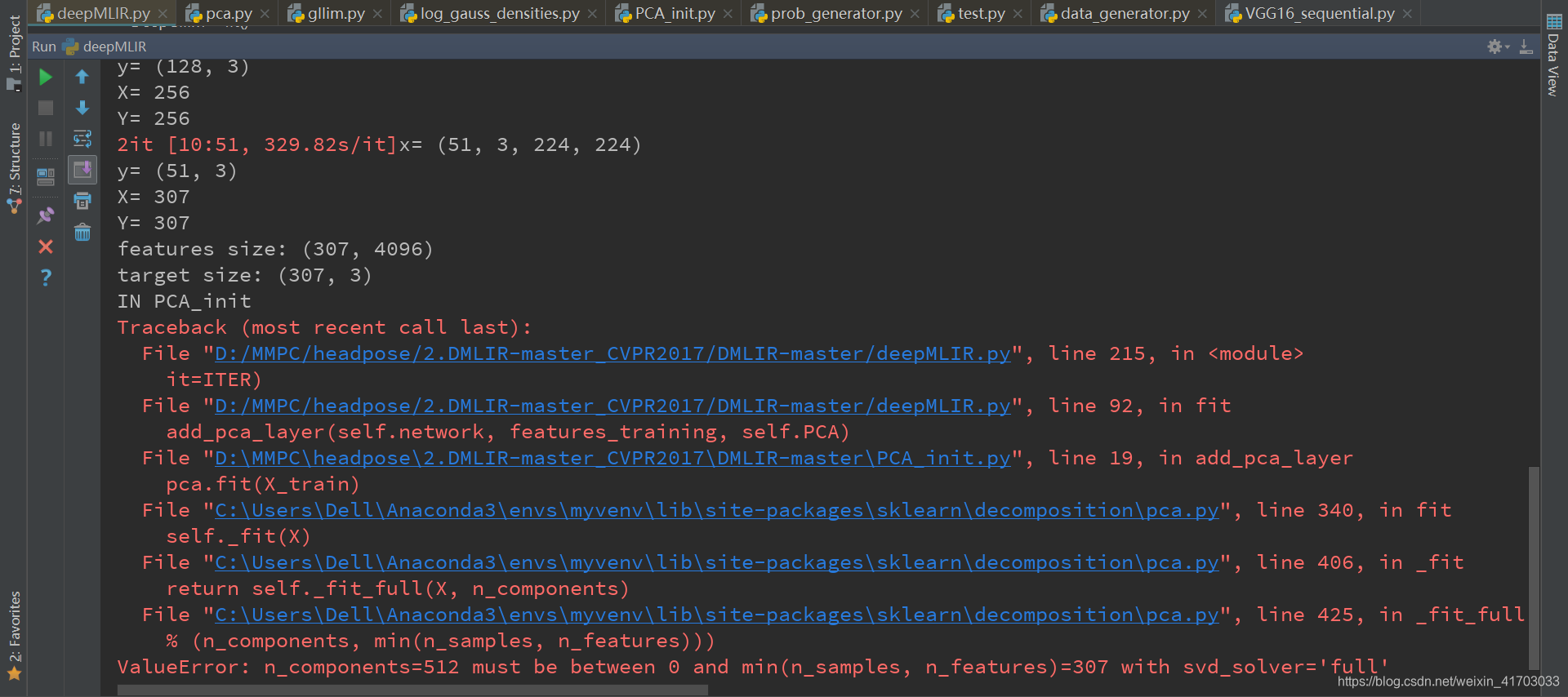
25.Annotations_train.txt:取Annotations.txt中的前1920個數據
Annotations_test.txt:取Annotations.txt中的前10個數據 + 129~ 139 + 1921~1941
2018.11.4
26.
- TypeError: init() got an unexpected keyword argument ‘min_covar’
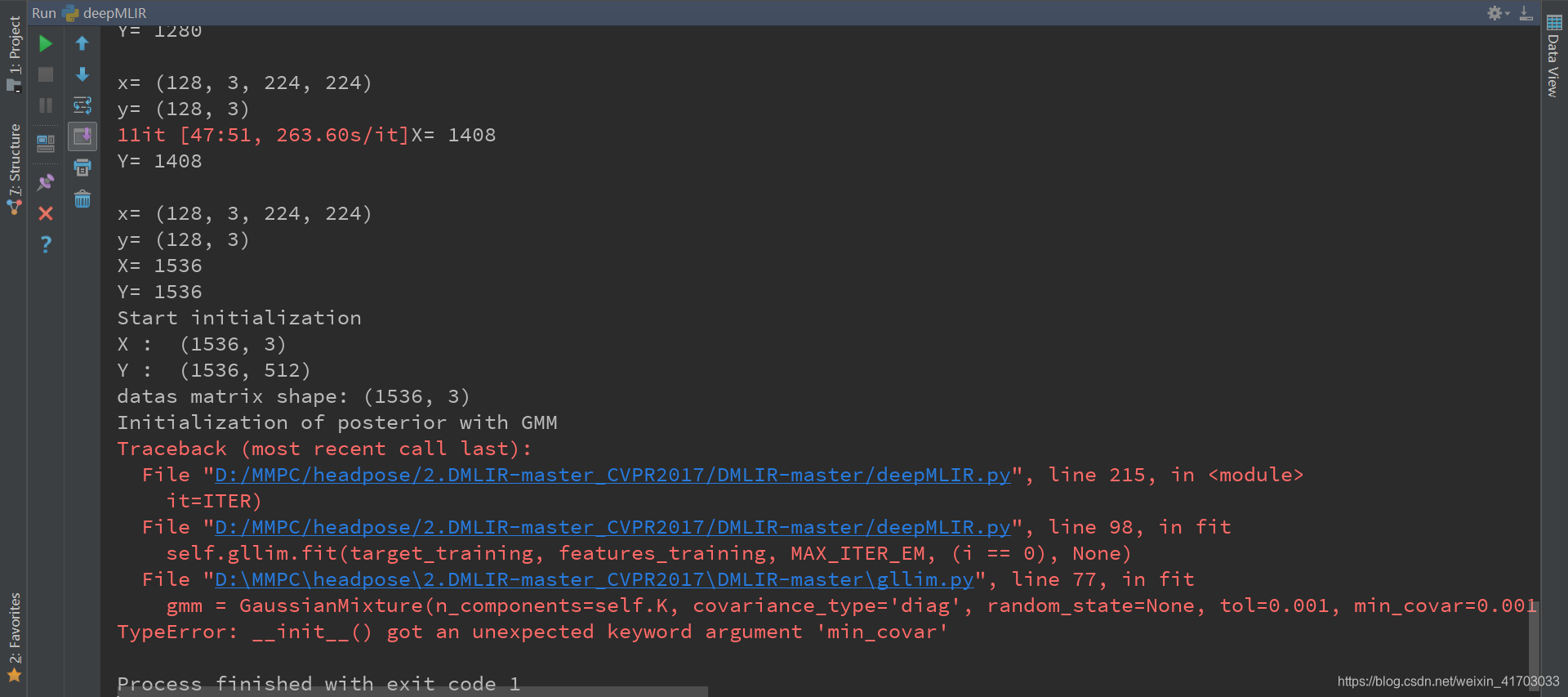
gllim.py L78:gmm=GaussianMixture(n_components=self.K,covariance_type=‘diag’,random_state=None,tol=0.001, reg_covar == 0.001, n_iter=100, n_init=3, params=‘wmc’, init_params=‘wmc’, verbose=1)
gmm=GaussianMixture(n_components=self.K,covariance_type=‘diag’,tol=0.001,reg_covar=0.001,max_iter=100,n_init=3,init_params=‘wmc’,weights_init=None,means_init=None,precisions_init=None,random_state=None, warm_start=False, verbose=0, verbose_interval=10)
為縮短時間:
Annotations_train.txt:取Annotations.txt中的前640個數據
Annotations_test.txt:取Annotations.txt中的前10個數據 + 129~ 139 + 1921~1941
gllim.py L81:n_init=3 1
deepMLIR.py L66: def fit(self, train_txt, test_txt, learning_rate=0.1, it=2 1)
27.
- ValueError: Unimplemented initialization method ‘wmc’
gmm = GaussianMixture(n_components=self.K, covariance_type=‘diag’, random_state=None, tol=0.001,reg_covar == 0.001, n_iter=100, n_init=3, params=‘wmc’, init_params=‘wmc’, verbose=1)
class sklearn.mixture.GMM(n_components=1, covariance_type=‘diag’, random_state=None, thresh=0.01, min_covar=0.001)
class sklearn.mixture.GaussianMixture(n_components=1, covariance_type=’full’, tol=0.001, reg_covar=1e-06, max_iter=100, n_init=1, init_params=‘wmc’, weights_init=None, means_init=None, precisions_init=None, random_state=None, warm_start=False, verbose=0, verbose_interval=10)
GMM : init_params : string, optional
Controls which parameters are updated in the initialization process. Can contain any combination of ‘w’ for weights, ‘m’ for means, and ‘c’ for covars. Defaults to ‘wmc’.
GaussianMixture : init_params : {‘kmeans’, ‘random’}, defaults to ‘kmeans’.
gllim.py L81: init_params= ‘wmc’ ’kmeans’
Annotations_train.txt:取Annotations.txt中的前512個數據
28.
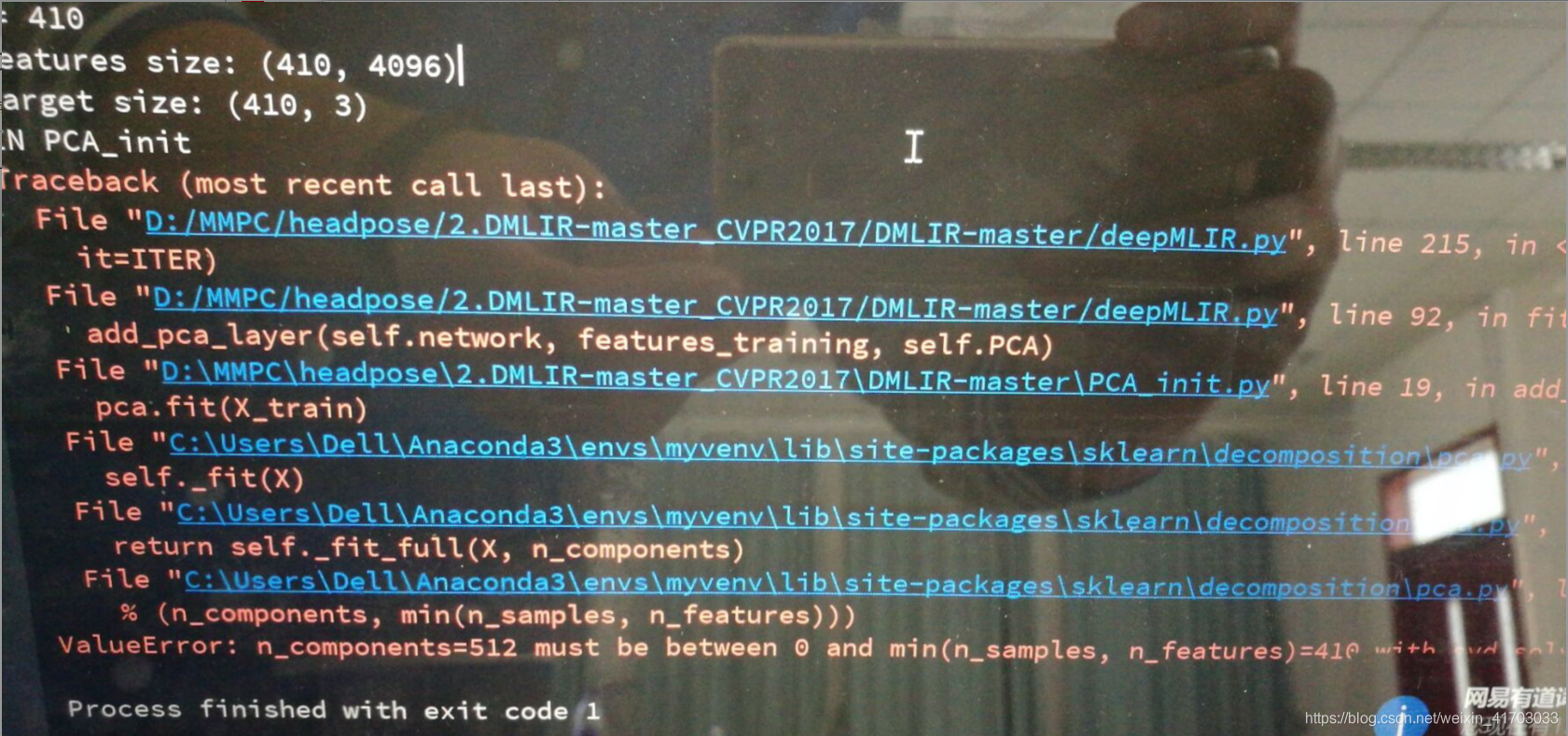
Annotations_train.txt:取Annotations.txt中的前1024個數據
29.
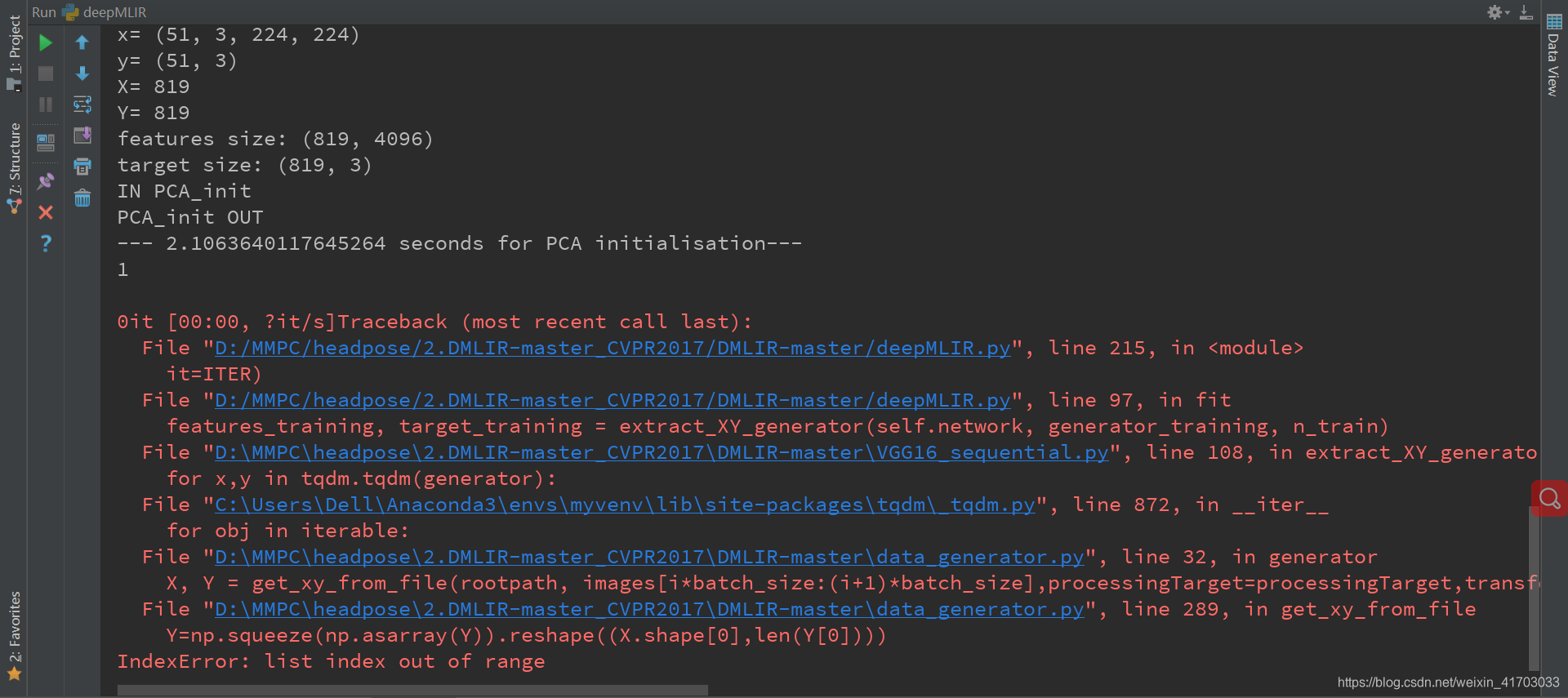
gllim.py L81:n_init=3
deepMLIR.py L66: def fit(self, train_txt, test_txt, learning_rate=0.1, it=2
30.
和上面同樣的錯誤
Annotations_train.txt:取Annotations.txt中的前1920個數據
2018.11.5
把這部分刪了,換成原來的,嘗試換一種方式, 而不是強制轉換map到numpy
print('X.shape',X.shape)
print ('type(X):',type(X))
print('mu:',mu)
X_np = []
for i in X:
X_np.append(i)
X_np = np.array(X_np)
print('X_np.shape:',X_np.shape)
print ('type(X_np):',type(X_np))
print('mu.shape:',mu.shape)
print('mu:',mu)
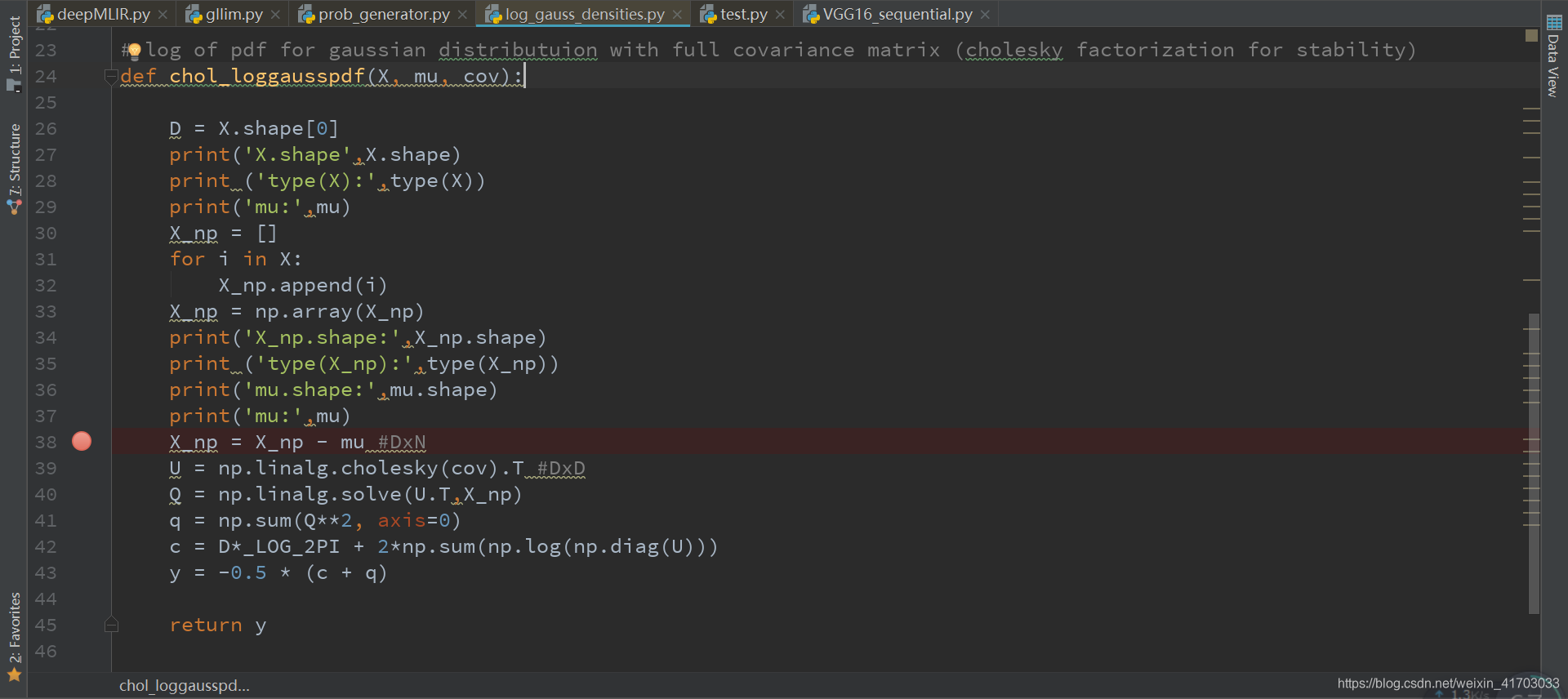
改成這樣
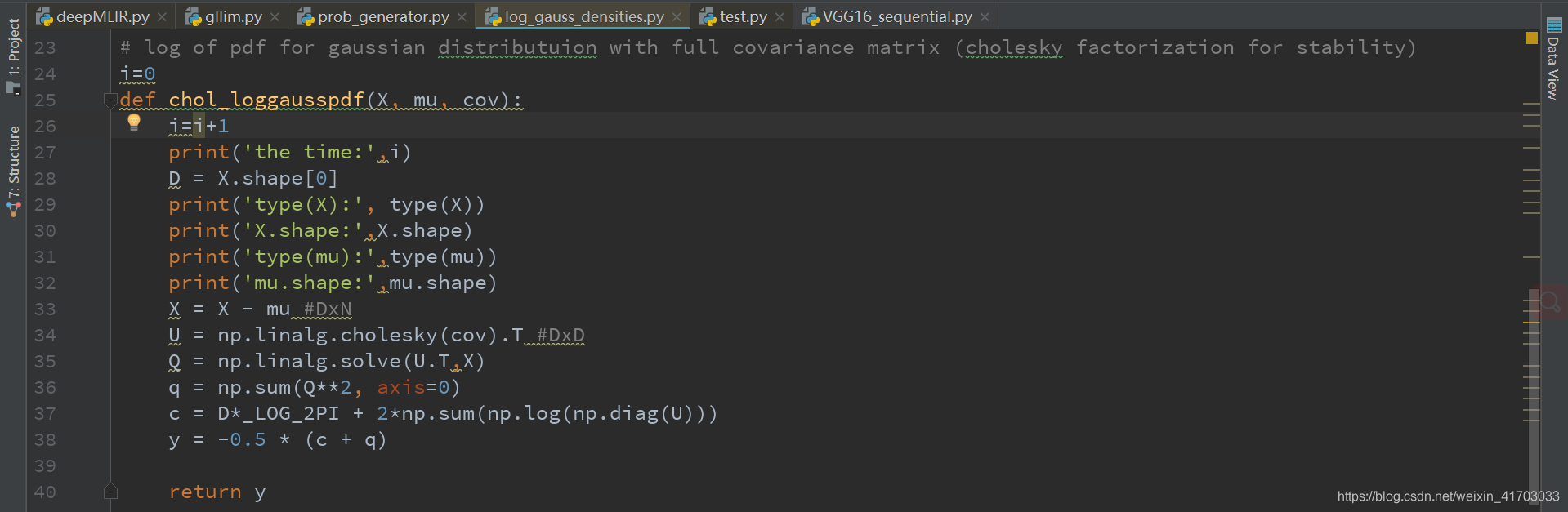
def chol_loggausspdf(X, mu, cov):
i=i+1
print('the time:',i)
D = X.shape[0]
print('type(X):', type(X))
print('X.shape:',X.shape)
print('type(mu):',type(mu))
print('mu.shape:',mu.shape)
X = X - mu #DxN
U = np.linalg.cholesky(cov).T #DxD
Q = np.linalg.solve(U.T,X)
q = np.sum(Q**2, axis=0)
c = D*_LOG_2PI + 2*np.sum(np.log(np.diag(U)))
y = -0.5 * (c + q)
return y
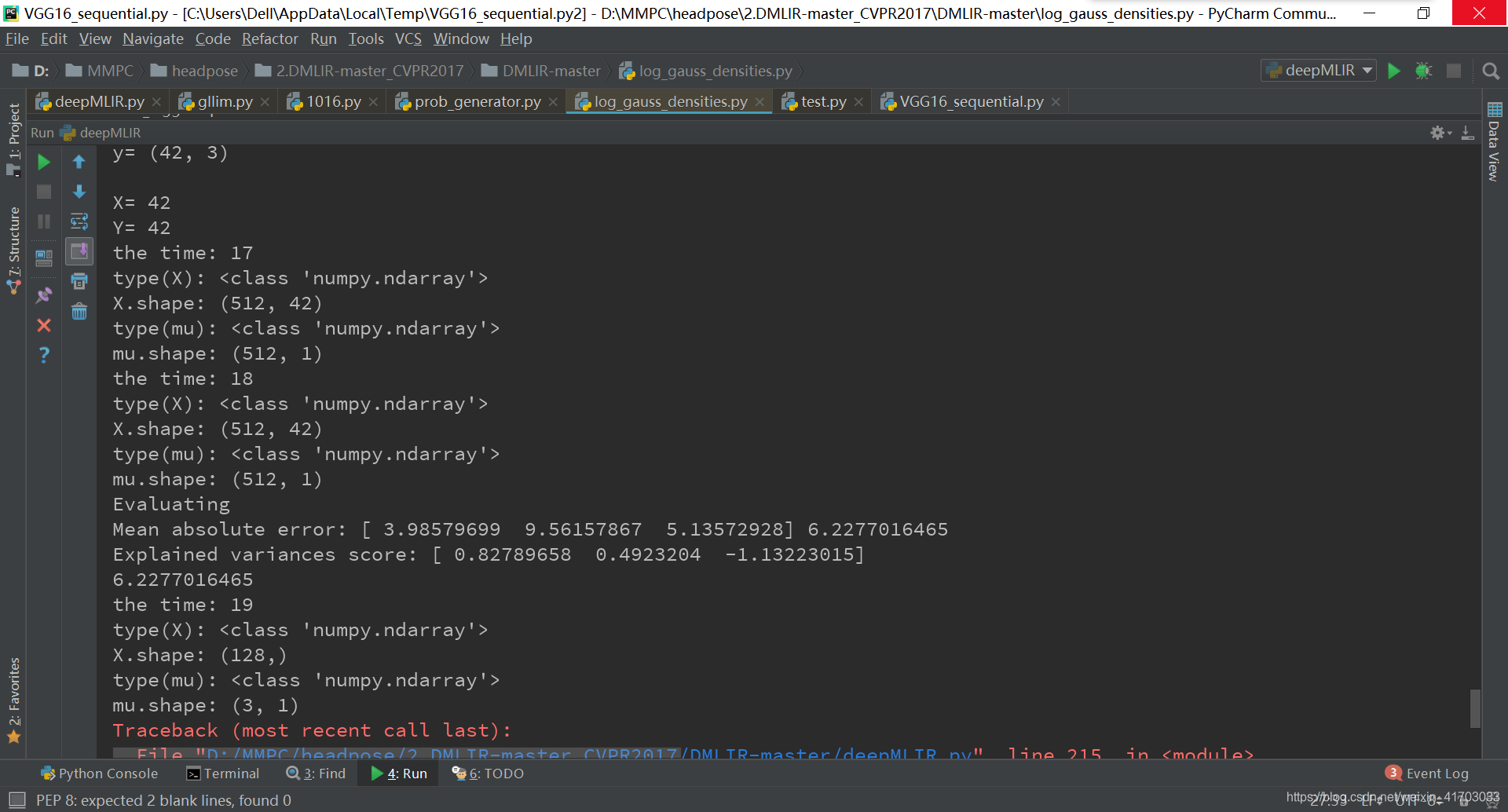
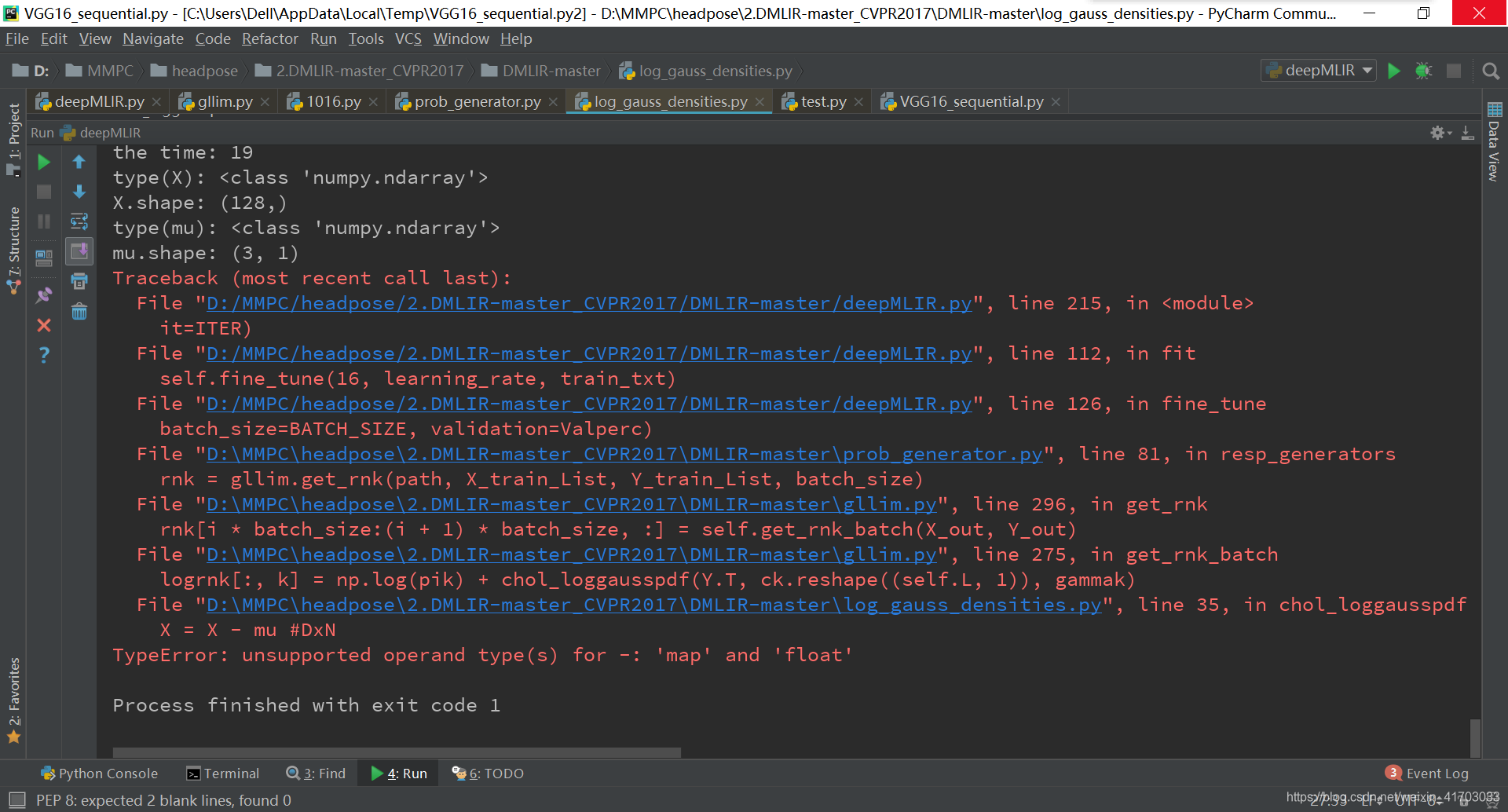
31.
prob_generator.py L59
原:
def get_list(path, f):
''' get lists of data from file '''
imagesLi = open(path+f, 'r').readlines()
X=[]
Y=[]
for currentline in imagesLi:
i=currentline.split()
X.append(i[0])
Y.append(map(lambda x: float(x),i[1:]))
return X, Y
改成:
def get_list(path, f):
''' get lists of data from file '''
imagesLi = open(path+f, 'r').readlines()
X=[]
Y=[]
for currentline in imagesLi:
i=currentline.split()
X.append(i[0])
print('get_list:len(X)=',len(X))
for a in i[1:]:
Y.append(float(a))
print('get_list:len(Y)=', len(Y))
#Y.append(map(lambda x: float(x),i[1:]))
return X, Y
2018.11.7
32.
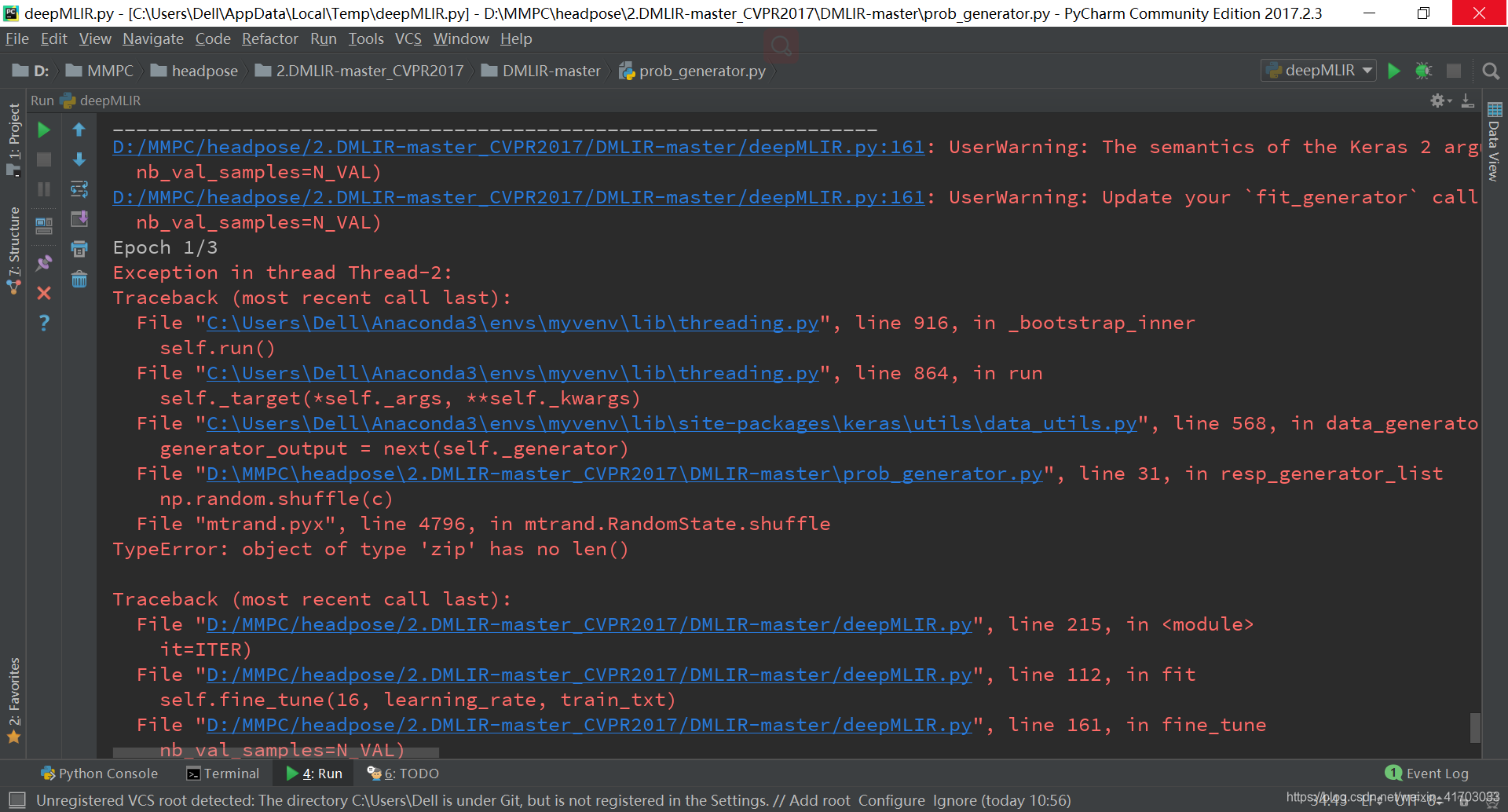
zip 方法在 Python 2 和 Python 3 中的不同:在 Python 3.x 中為了減少記憶體,zip() 返回的是一個物件。如需展示列表,需手動 list() 轉換。
prob_generator.py L31:新增:c=list(c)
33.
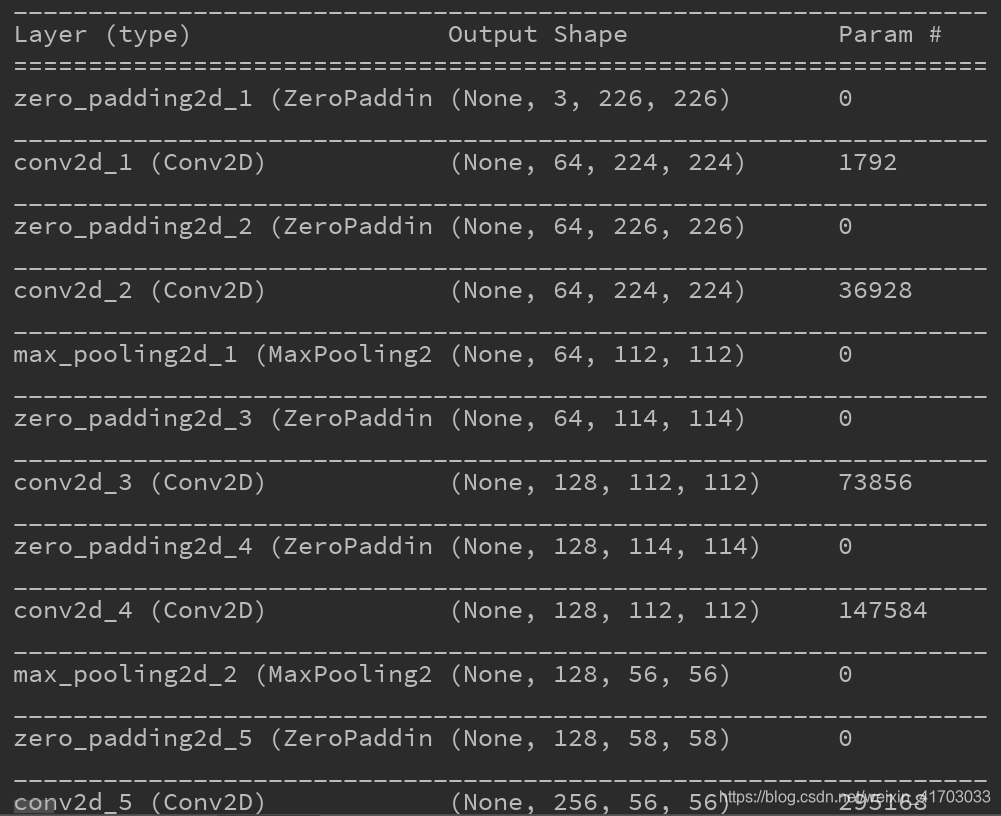
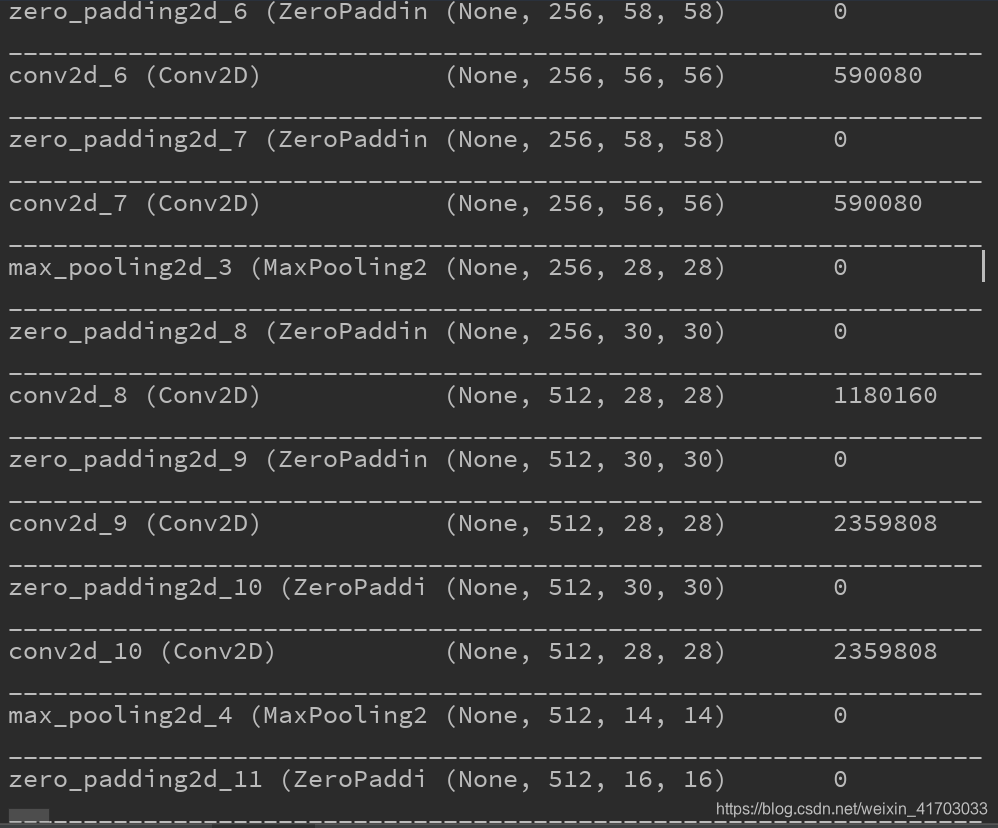
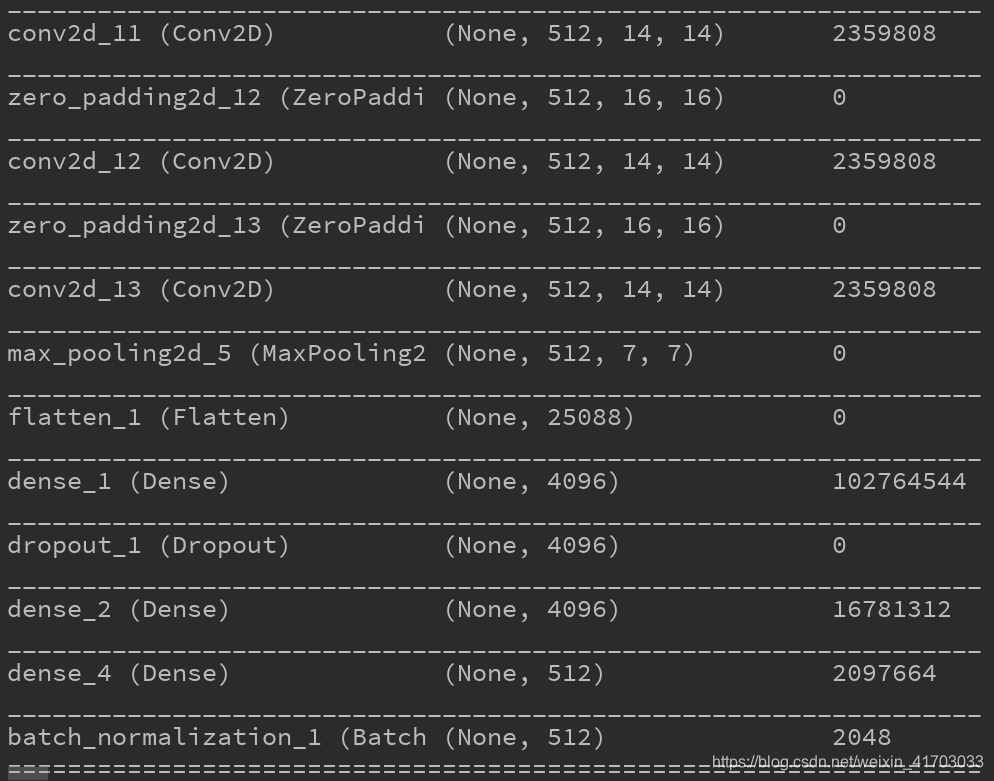
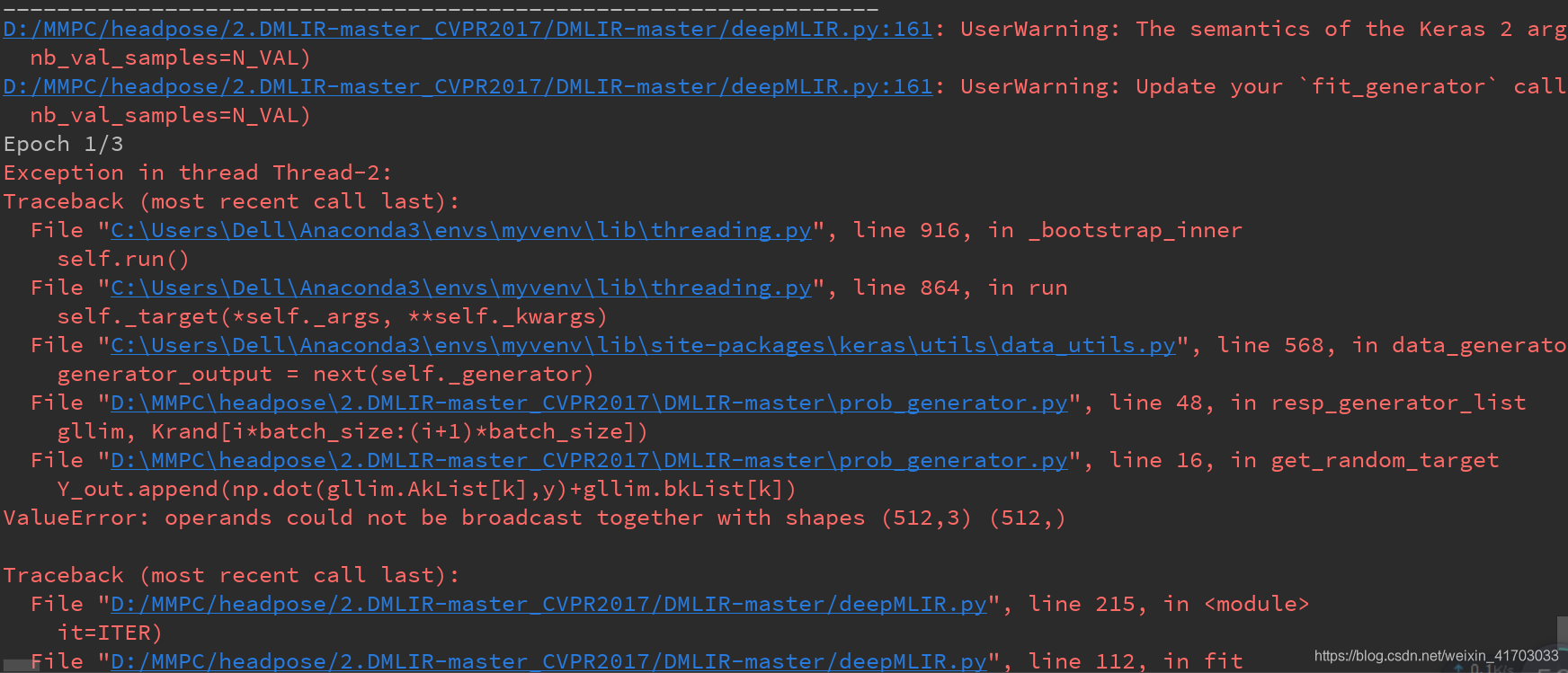
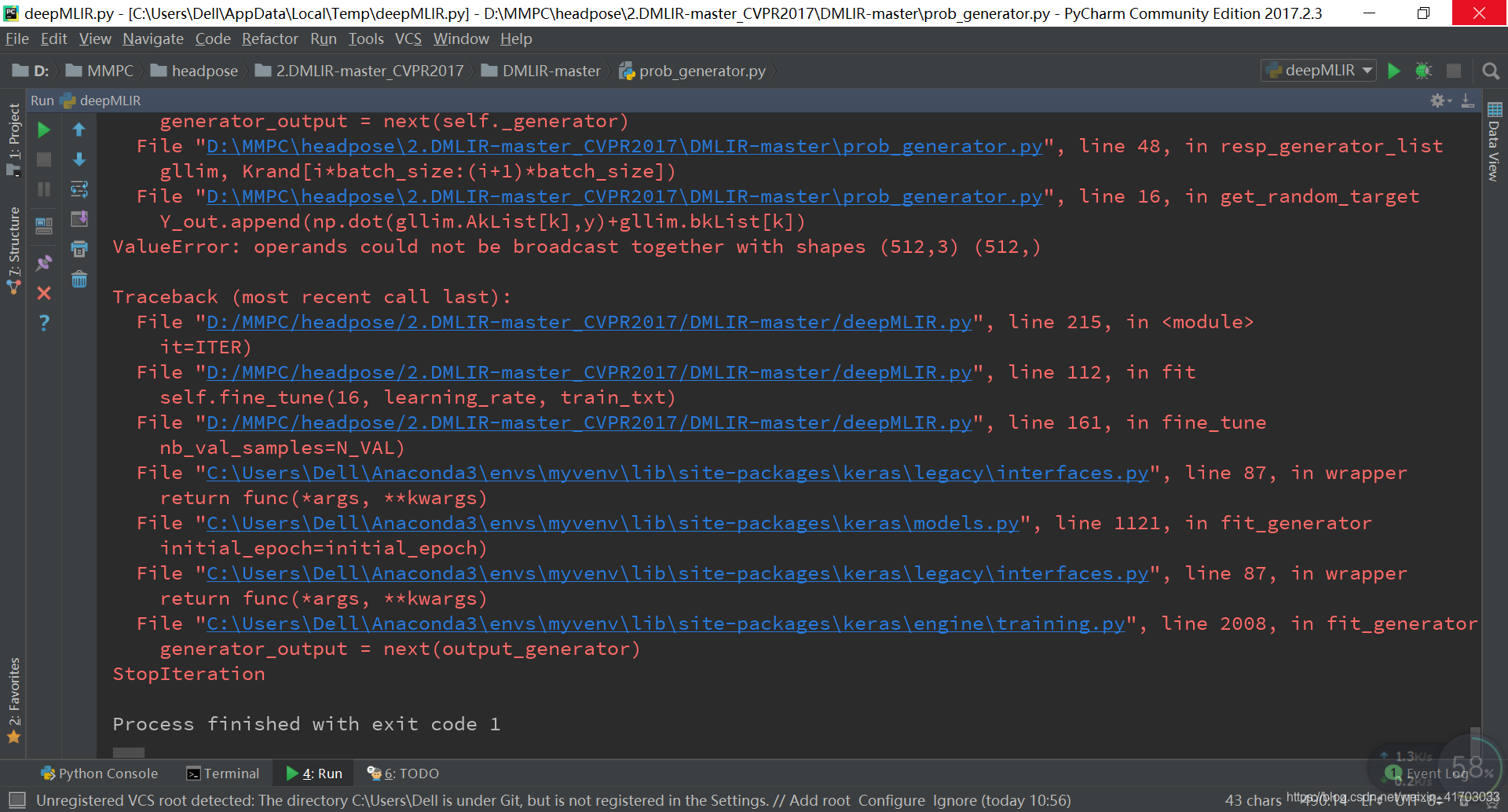
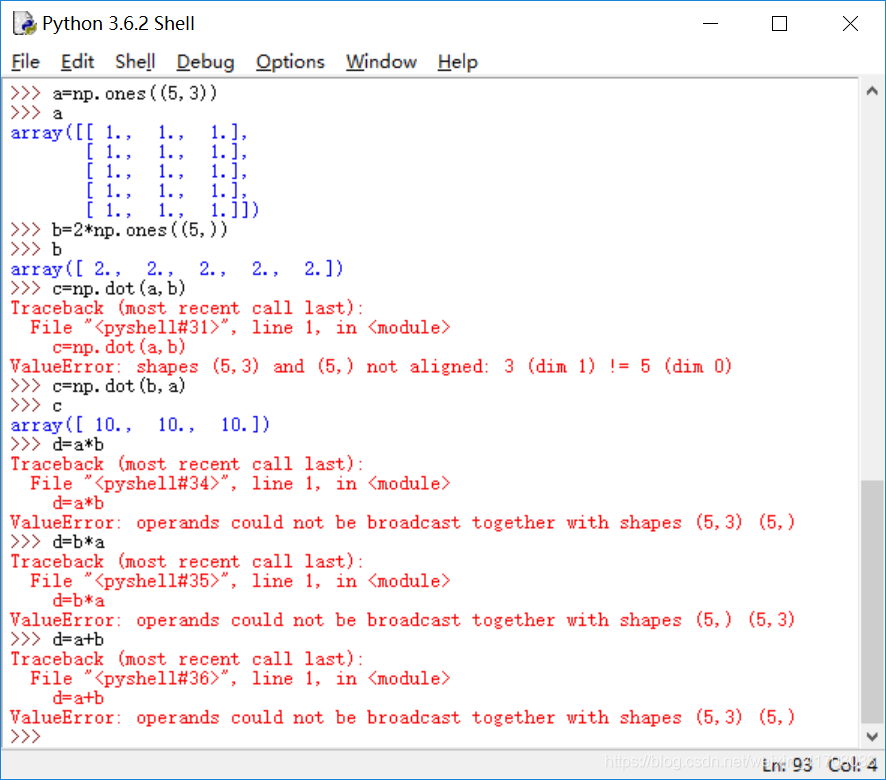

prob_generator.py L16:
Y_out.append(np.dot(gllim.AkList[k],y)+gllim.bkList[k])
改成
Y_out.append(np.dot(gllim.AkList[k],y)+np.mat(gllim.bkList[k]).T)