
kafka效能優化詳解
KAFKA Cluster模式最大的優點:可擴充套件性和容錯性。下圖是關於Kafka叢集的結構圖:
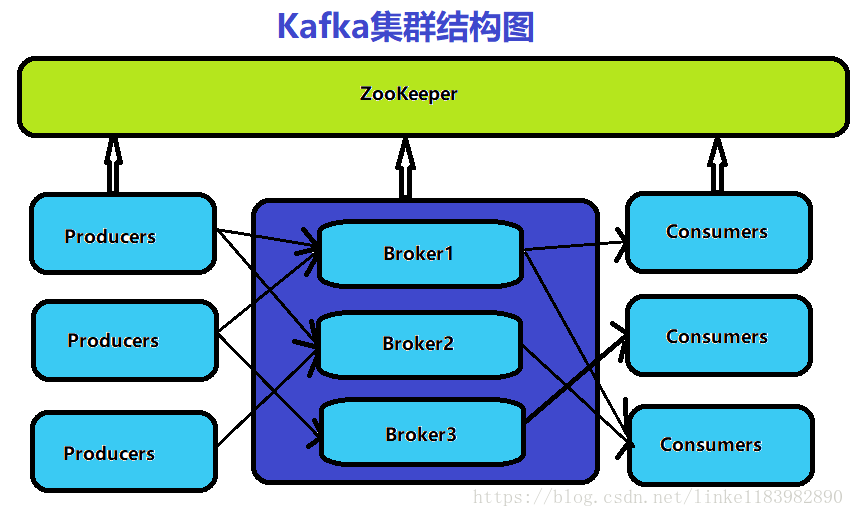


三、Kafka叢集穩定
1、GC調優
調GC是門手藝活,幸虧Java 7引進了G1 垃圾回收,使得GC調優變的沒那麼難。G1主要有兩個配置選項來調優:MaxGCPauseMillis 和 InitiatingHeapOccupancyPercent,具體引數設定可以參考Google,這裡不贅述。
Kafka broker能夠有效的利用堆記憶體和物件回收,所以這些值可以調小點。對於 64Gb記憶體,Kafka執行堆記憶體5Gb,MaxGCPauseMillis 和 InitiatingHeapOccupancyPercent 分別設定為 20毫秒和 35。Kafka的啟動指令碼使用的不是 G1回收,需要在環境變數中加入:

Kafka效能調優.
一、partition數量配置
partition數量由topic的併發決定,併發少則1個分割槽就可以,併發越高,分割槽數越多,可以提高吞吐量







