
【搞定Java併發程式設計】第13篇:重排序
上一篇:happens-before:https://blog.csdn.net/pcwl1206/article/details/84929752
目 錄:
重排序:指編譯器和處理器為了優化程式效能而對指令序列進行重新排序的一種手段。
1、資料依賴性
如果兩個操作訪問同一個變數,且這兩個操作中有一個為寫操作,此時這兩個操作之間就存在資料依賴性。
| 名稱 | 程式碼示例 | 說明 |
|---|---|---|
| 寫後讀 | a = 1; b = a; |
寫一個變數之後,再讀這個位置 |
| 寫後寫 | a = 1; a = 2; |
寫一個變數之後,再寫這個變數 |
| 讀後寫 | a = b; b = 1; |
讀一個變數之後,再寫這個變數 |
上面三種情況,只要重排序兩個操作的執行順序,程式的執行結果將會被改變。編譯器和處理器在重排序時,會遵守資料依賴性,編譯器和處理器不會改變存在資料依賴關係的兩個操作的執行順序。
注意,這裡所說的資料依賴性僅針對單個處理器中執行的指令序列和單個執行緒中執行的操作,不同處理器之間和不同執行緒之間的資料依賴性不被編譯器和處理器考慮。
2、as-if-serial語義
as-if-serial語義的意思指:不管怎麼重排序(編譯器和處理器為了提高並行度),(單執行緒)程式的執行結果不能被改變。
為了遵守as-if-serial語義,編譯器和處理器不會對存在資料依賴關係的操作做重排序,因為這種重排序會改變執行結果。但是,如果操作之間不存在資料依賴關係,這些操作可能被編譯器和處理器重排序。
比如之前講過的計算圓面積的案例:
double pi = 3.14; // A
double r = 1.0; // B
double area = pi * r * r; // C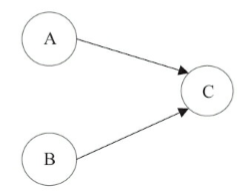
從上圖可以看出來,A和C以及B和C之間存在資料依賴關係,但是A和B之間並不存在資料依賴關係。因此,編譯器和處理器可以重排序A和B之間的執行順序。
as-if-serial語義把單執行緒程式保護了起來,遵守as-if-serial語義的編譯器、runtime和處理器共同為編寫單執行緒程式的程式設計師建立了一個幻覺:單執行緒程式是按照程式的順序來執行的。as-if-serial語義使單執行緒程式設計師無需擔心重排序會干擾他們,也無需擔心記憶體可見性問題。
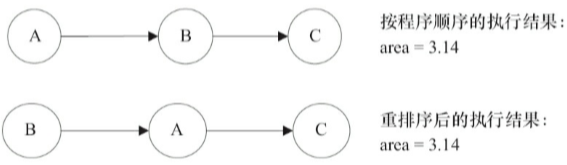
3、程式順序規則
按照happens-before的程式順序規則,上面計算圓面積的程式碼存在3個happens-before關係:
1、A happens-before B;
2、B happens-before C;
3、A happens-before C;
A happens-before C是根據傳遞性推匯出來的。這裡的A happens-before B,但是實際執行時B卻可以排在A之前執行,JMM並不不要求A一定在B之前執行,因為它們之間沒有資料依賴關係,因此如果1和2發生了重排序,也不會影響計算結果的正確性。JMM允許這種重排序。
在計算機中,軟體技術和硬體技術有一個共同的目標:在不改變程式執行結果的前提下,儘可能提高並行度。編譯器和處理器遵從這一目標,從happens-before的定義我們可以看出,JMM同樣遵從這一目標。
4、重排序對多執行緒的影響
重排序是否會改變多執行緒程式的執行結果呢?看下面這個案例:
class ReorderExample{
int a = 0;
boolean flag = false;
public void writer(){
a = 1; // 1
flag = true; // 2
}
public void reader(){
if(flag){ // 3
int i = a * a; // 4
......
}
}
}flag是個變數,用來標識變數a是否已被寫入。假設有兩個執行緒A和B,A首先執行writer()方法,隨後B執行緒接著執行rader()方法。那麼B在執行操作4時,能否看見操作A在操作1對共享變數的寫入呢?
答案是:不一定能看到。
由於操作1和操作2沒有資料依賴關係,編譯器和處理器可以對這兩個操作重排序。

如上圖所示:操作1和操作2做了重排序。程式執行時,執行緒A首先寫標記變數flag,隨後執行緒B讀這個變數。由於條件判斷為真,執行緒B將讀取變數a。此時,變數a還沒有被執行緒A寫入,在這裡多執行緒程式的語義被重排序破壞了。
實際上,操作3和操作4也可能傳送重排序,那我們就來看看操作3和操作4發生了重排序後會有什麼情況發生?

操作3和操作4存在控制依賴關係。當代碼中存在控制依賴時,會影響指令序列執行的並行度。為此,編譯器和處理器會採用猜測(Speculation)執行來克服控制相關性對並行度的影響。
從圖中可以看出,猜測執行實際上對操作3和操作4進行了重排序,無需判斷flag是否為true時,就可以讀取a的值了,顯然破壞了多執行緒程式的語義。
5、指令重排的案例講解
下文的內容在Java記憶體模型中已經講解過,這裡再複述一遍。
5.1、指令重排
計算機在執行程式時,為了提高效能,編譯器和處理器的常常會對指令做重排,一般分以下3種:
1、編譯器優化的重排
編譯器在不改變單執行緒程式語義的前提下,可以重新安排語句的執行順序。
2、指令並行的重排
現代處理器採用了指令級並行技術來將多條指令重疊執行。如果不存在資料依賴性(即後一個執行的語句無需依賴前面執行的語句的結果),處理器可以改變語句對應的機器指令的執行順序。
3、記憶體系統的重排
由於處理器使用快取和讀寫快取衝區,這使得載入(load)和儲存(store)操作看上去可能是在亂序執行,因為三級快取的存在,導致記憶體與快取的資料同步存在時間差。
其中編譯器優化的重排屬於編譯期重排,指令並行的重排和記憶體系統的重排屬於處理器重排。從Java原始碼到最終實際執行的指令序列,會分別經歷下面三種重排序。

在多執行緒環境中,這些重排優化可能會導致程式出現記憶體可見性問題,下面分別闡明這兩種重排優化可能帶來的問題。
5.1.1、編譯器重排
下面我們簡單看一個編譯器重排的例子:
執行緒 1 執行緒 2
1:x2 = a ; 3: x1 = b ;
2:b = 1; 4: a = 2 ;
兩個執行緒同時執行,分別有1、2、3、4四段執行程式碼,其中1、2屬於執行緒1 , 3、4屬於執行緒2 ,從程式的執行順序上看,似乎不太可能出現x1 = 1 和x2 = 2 的情況,但實際上這種情況是有可能發現的,因為如果編譯器對這段程式程式碼執行重排優化後,可能出現下列情況:
執行緒 1 執行緒 2
2:b = 1; 4: a = 2 ;
1:x2 = a ; 3: x1 = b ;
這種執行順序下就有可能出現x1 = 1 和x2 = 2 的情況,這也就說明在多執行緒環境下,由於編譯器優化重排的存在,兩個執行緒中使用的變數能否保證一致性是無法確定的。
5.1.2、處理器指令重排
先了解一下指令重排的概念,處理器指令重排是對CPU的效能優化,從指令的執行角度來說一條指令可以分為多個步驟完成,如下:
- 取指 IF;
- 譯碼和取暫存器運算元 ID;
- 執行或者有效地址計算 EX;
- 儲存器訪問 MEM;
- 寫回 WB。
CPU在工作時,需要將上述指令分為多個步驟依次執行(注意硬體不同有可能不一樣),由於每一步會使用到不同的硬體操作,比如取指時會用到PC暫存器和儲存器、譯碼時會執行到指令暫存器組、執行時會執行ALU(算術邏輯單元)、寫回時使用到暫存器組。為了提高硬體利用率,CPU指令是按流水線技術來執行的,如下:

從圖中可以看出當指令1還未執行完成時,第2條指令便利用空閒的硬體開始執行,這樣做是有好處的。如果每個步驟花費1ms,那麼如果第2條指令需要等待第1條指令執行完成後再執行的話,則需要等待5ms,但如果使用流水線技術的話,指令2只需等待1ms就可以開始執行了,這樣就能大大提升CPU的執行效能。
雖然流水線技術可以大大提升CPU的效能,但不幸的是一旦出現流水中斷,所有硬體裝置將會進入一輪停頓期,當再次彌補中斷點可能需要幾個週期,這樣效能損失也會很大,就好比工廠組裝手機的流水線,一旦某個零件組裝中斷,那麼該零件往後的工人都有可能進入一輪或者幾輪等待組裝零件的過程。因此我們需要儘量阻止指令中斷的情況,指令重排就是其中一種優化中斷的手段,我們通過一個例子來闡明指令重排是如何阻止流水線技術中斷的。
a = b + c ;
d = e + f ;
下面通過彙編指令展示了上述程式碼在CPU執行的處理過程:

- LW指令表示 load,其中LW R1,b表示把 b 的值載入到暫存器R1中;
- LW R2,c 表示把 c 的值載入到暫存器R2中;
- ADD 指令表示加法,把R1 、R2的值相加,並存入R3暫存器中。
- SW 表示 store, 即:將 R3暫存器的值儲存到變數a中;
- LW R4,e 表示把 e 的值載入到暫存器R4中;
- LW R5,f 表示把 f 的值載入到暫存器R5中;
- SUB 指令表示減法,把R4 、R5的值相減,並存入R6暫存器中。
- SW d,R6 表示將R6暫存器的值儲存到變數d中。
上述便是彙編指令的執行過程,在某些指令上存在X的標誌,X代表中斷的含義,也就是隻要有 X 的地方就會導致指令流水線技術停頓,同時也會影響後續指令的執行,可能需要經過1個或幾個指令週期才可能恢復正常,那為什麼停頓呢?這是因為部分資料還沒準備好,如執行ADD指令時,需要使用到前面指令的資料R1,R2,而此時R2的MEM操作沒有完成,即未拷貝到儲存器中,這樣加法計算就無法進行,必須等到MEM操作完成後才能執行,也就因此而停頓了,其他指令也是類似的情況。
前面闡述過,停頓會造成CPU效能下降,因此我們應該想辦法消除這些停頓,這時就需要使用到指令重排了。如下圖,既然ADD指令需要等待,那我們就利用等待的時間做些別的事情,如把LW R4,e 和 LW R5,f 移動到前面執行,畢竟LW R4,e 和 LW R5,f 執行並沒有資料依賴關係,對它們有資料依賴關係的 SUB R6,R5,R4 指令在 R4,R5 載入完成後才執行的,沒有影響。過程如下:

正如上圖所示,所有的停頓都完美消除了,指令流水線也無需中斷了,這樣CPU的效能也能帶來很好的提升,這就是處理器指令重排的作用。關於編譯器重排以及指令重排(這兩種重排我們後面統一稱為指令重排)相關內容已闡述清晰了,我們必須意識到對於單執行緒而言指令重排幾乎不會帶來任何影響,比竟重排的前提是保證序列語義執行的一致性,但對於多執行緒環境而言,指令重排就可能導致嚴重的程式輪序執行問題,如下:
class MixedOrder{
int a = 0;
boolean flag = false;
public void writer(){
a = 1;
flag = true;
}
public void read(){
if(flag){
int i = a + 1;
}
}
}如上述程式碼,同時存線上程A和執行緒B對該例項物件進行操作,其中A執行緒呼叫寫入方法,而B執行緒呼叫讀取方法,由於指令重排等原因,可能導致程式執行順序變為如下:

由於指令重排的原因,執行緒A的flag置為true被提前執行了,而a賦值為1的程式還未執行完。此時執行緒B,恰好讀取flag的值為true,直接獲取a的值(此時B執行緒並不知道a為0)並執行 i 賦值操作,結果 i 的值為1,而不是預期的2,這就是多執行緒環境下,指令重排導致的程式亂序執行的結果。因此,請記住,指令重排只會保證單執行緒中序列語義的執行的一致性,但並不會關心多執行緒間的語義一致性。
上一篇:happens-before:https://blog.csdn.net/pcwl1206/article/details/84929752