
Class 14 - 2 解析庫 -- Beautiful Soup
Beautiful Soup是 Python 的一個 HTML 或 XML 的解析庫,庫藉助網頁的結構和屬性等特性來解析網頁
- 解析器
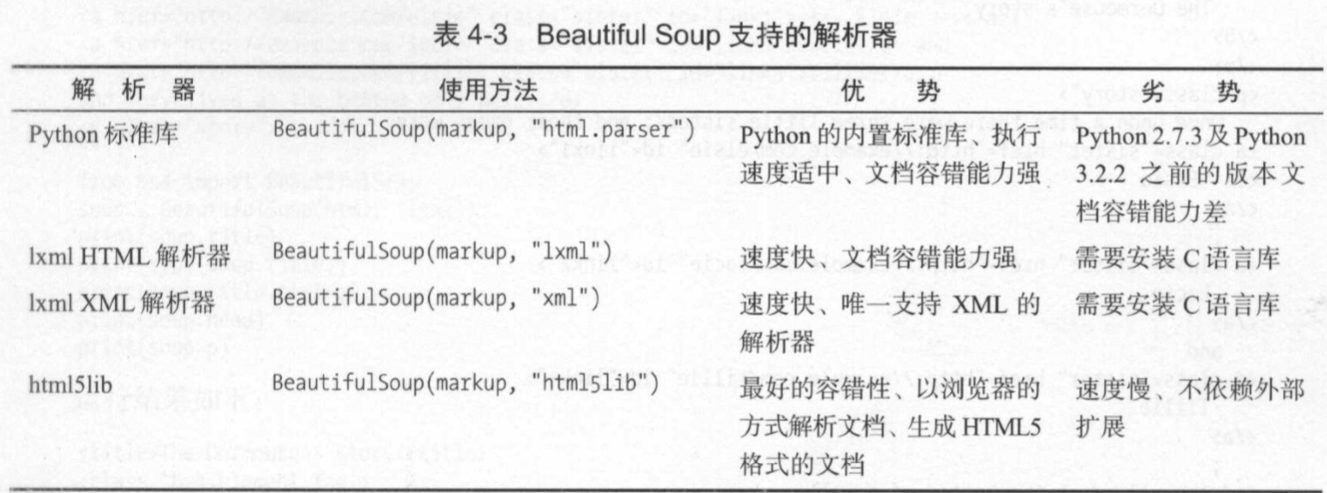
- Beautiful Soup在解析時依賴解析器,除了支援 Python 標準庫中的 HTML 解析器外,還支援一些第三方解析器(比如 lxml )。
-
以上對比,lxml 解析器有解析 HTML 和 XML 的功能,速度’快,容錯能力強,所以推薦使用它。
-
如果使用 lxml,那麼在初始化 Beautiful Soup 時,可以把第二個引數改為 lxml。例:
from bs4 import
BeautifulSoup Soup = BeautifulSoup('<p>Hello</p>','lxml') print(Soup.p.string)
- Beautiful Soup在解析時依賴解析器,除了支援 Python 標準庫中的 HTML 解析器外,還支援一些第三方解析器(比如 lxml )。
- 基本用法
-
html = ''' <html><head><title>The Dormouse's story</title></head> <body> <p class ='title' name='dromouse'><b>The Dormouse's story</p></p> <p class = 'story'>Once upon a time there were three little sisters; and their names were <a href='http://example.com/elsie' class='sister' id='link1'><!--Elsie--></a>, <a href='http://example.com/lacie' class='sister' id='link2'>Lacie</a> and <a href='http://example.com/tillie'class='sister' id='link3'>Tillie</a>; and they lived at the bottom of a well.</p> <p class='story'>...</p>
''' from bs4 import BeautifulSoup soup=BeautifulSoup(html,'lxml') print(soup.prettify()) print(soup.title.string)
輸出: <html> <head> <title> The Dormouse's story </title> </head> <body> <p class="title" name="dromouse
View Code"> <b> The Dormouse's story </b> </p> <p class="story"> Once upon a time there were three little sisters; and their names were <a class="sister" href="http://example.com/elsie" id="link1"> <!--Elsie--> </a> , <a class="sister" href="http://example.com/lacie" id="link2"> Lacie </a> and <a class="sister" href="http://example.com/tillie" id="link3"> Tillie </a> ; and they lived at the bottom of a well. </p> <p class="story"> ... </p> </body> </html> The Dormouse's story-
首先宣告變數 html,它是一個 HTML 字串。需要注意的是,它並不是一個完整的 HTML 字串,因為 body 和 html 節點都沒有閉合。 接著,將它當作第一個引數傳給 BeautifulSoup 對 象,物件的第二個引數為解析器的型別(這裡使用 lxml ),此時就完成了 BeaufulSoup 物件的初始化。 然後,將這個物件賦值給 soup 變數。
-
接下來,呼叫 soup 的各個方法和屬性解析HTML 程式碼。
-
首先,呼叫 prettify()方法可以把要解析的字串以標準的縮排格式輸出。 注意:輸出結果裡面包含 body 和 html 節點,也就是說對於不標準的 HTML 字串 Beautifol Soup , 可以自動更正格式。 這一步不是由 prettify()方法做的,而是在初始化 Beautifol Soup 時就完成了。
-
然後呼叫 soup.title.string,這實際上是輸出 HTML 中 title 節點的文字內容。所以,soup.title 可以選出 HTML 中的 title 節點,再呼叫 string 屬性就可以得到裡面的文字了,所以我們可以通過 簡單呼叫幾個屬性完成文字提取。
-
-
-
節點選擇器
-
直接呼叫節點的名稱就可以選擇節點元素,再呼叫 string 屬性就可以得到節點內的文字。 如果單個節點結構層次非常清晰,可以選用這種方式來解析。
-
選擇元素
-
html = ''' --snip-- ''' from bs4 import BeautifulSoup soup=BeautifulSoup(html,'lxml') print(soup.title) print(type(soup.title)) print(soup.title.string) print(soup.head) print(soup.p)
輸出: <title>The Dormouse's story</title> <class 'bs4.element.Tag'> The Dormouse's story <head><title>The Dormouse's story</title></head> <p class="title" name="dromouse"><b>The Dormouse's story</b></p>
-
首先輸出 title 節點的選擇結果,輸出結果正是 title 節 點加里面的文字內容。
-
接下來,輸出它的型別,是 bs4.element.Tag 型別,這是 Beautiful Soup 中一個 重要的資料結構。 經過選擇器選擇後,選擇結果都是這種 Tag 型別。 Tag 具有一些屬性,比如 呼叫string 屬性可以得到節點的文字內容,所以接下來的輸出結果正是節點的文字內容。嘗試選擇了 head 節點,也是節點加其內部的所有內容。
-
選擇了 p 節點。 不過這次情況比較特殊,我們發現結果是第一個 p 節點的內容,後面的幾個 p 節點並沒有選到。 也就是說,當有多個節點時,這種選擇方式只會選擇到第一個匹配的節點,其他的後面節點都會忽略
-
-
-
提取資訊
-
獲取名稱
-
利用 name 屬性獲取節點的名稱,選取 title 節點,然後呼叫 name屬性就可以得到節點名稱:
print(soup.title.name) 輸出: title
-
-
獲取屬性
- 每個節點可能有多個屬性,如 id class 等,選擇這個節點元素後,可以呼叫 attrs 獲取所有屬性:
print(soup.p.attrs) print(soup.p.attrs['name']) 輸出: {'class':['title'], 'name':'dromouse'} dromouse
attrs 的返回結果是字典形式,把選擇的節點的所有屬性和屬性值組合成一個字典。 如果要獲取 name 屬性,就相當於從字典中獲取某個鍵值,只需要用中括號加屬性名就可以 比如,要獲取 name 屬性,就可以通過 attrs['name'] 來得到
- 可以不用寫 attrs ,直接在節點元素後面加中 括號,傳入屬性名就可以獲取屬性值了。示例:
print(soup.p['name']) print(soup.p['class']) 輸出: dromouse ['title']
注意:有的返回結果是字串,有的返回結果是字串組成的列表。比如, name 屬性的值是唯一的,返回的結果就是單個字串。而對於 class 一個節點元素可能有多個 class 所以 返回的是列表。
- 每個節點可能有多個屬性,如 id class 等,選擇這個節點元素後,可以呼叫 attrs 獲取所有屬性:
- 獲取內容
- 可以利用 string 屬性獲取節點元素包含的文字內容,如獲取第一個 p 節點的文字:
print(soup.p.string) 輸出: The Dormouse's story
注意:這裡選擇到的 p 節點是第一個 p 節點,獲取的文字也是第一個 p 節點裡面的文字。
- 可以利用 string 屬性獲取節點元素包含的文字內容,如獲取第一個 p 節點的文字:
-
-
巢狀選擇
-
以上例子,每個返回結果都是 bs4 element.Tag 型別,同樣可以繼續呼叫節點進行下一步的選擇。如:獲取了 head 節點元素,可以繼續呼叫 head 來選取內部的 head 節點元素:
html = ''' <html><head><title>The Dormouse's story</title></head> <body> ''' from bs4 import BeautifulSoup soup=BeautifulSoup(html,'lxml') print(soup.head.title.string) print(type(soup.head.title)) 輸出: The Dormouse's story <class 'bs4.element.Tag'>
第一行結果是呼叫 head 之後再次呼叫 title 而選擇的 title 節點元素。輸出型別仍然是 bs4.element.Tag 型別。在 Tag 型別的基礎上再次選擇得到的依然還是 Tag 型別,每次返回的結果都相同。所以這樣就可以做巢狀選擇了。 最後,輸出它的 string 屬性,也就是節點裡的文字內容。
-
-
關聯選擇
-

-
-
-
子節點和子孫節點
-
-
-
-
-
-
選取節點元素之後,如果想要獲取它的直接子節點,可以呼叫 contents 屬性。示例:
html = ''' <html> <head> <title>The Dormouse's story</title> </head> <body> <p class='story'> Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1"> <span>Elsie</span> </a> <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a> and they lived at the bottom of a well. <p class="story">...</p> ''' from bs4 import BeautifulSoup soup=BeautifulSoup(html,'lxml') print(soup.p.contents) 輸出:
['\n Once upon a time there were three little sisters; and their names were\n ', <a class="sister" href="http://example.com/elsie" id="link1"> <span>Elsie</span> </a>, '\n', <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, '\nand\n', <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>, '\nand they lived at the bottom of a well.\n']
View Code返回結果是列表形式。p 節點裡既包含文字,又含節點,最後會將它們以列表形式 統一返回
注意:列表中的每個元素都是 p 節點的直接子節點。 如第一個a節點裡包含一層 span 節點,這相當於孫子節點了,但是返回結果並沒有單獨把 span 節點選出來。所以, contents 屬性得到的結果是直接子節點的列表
同樣,可以呼叫 children 屬性得到相應的結果:
from bs4 import BeautifulSoup soup=BeautifulSoup(html,'lxml') print(soup.p.children) for i,child in enumerate(soup.p.children):
"""enumerate() 函式用於將一個可遍歷的資料物件(如列表、元組或字串)組合為一個索引序列,同時列出資料和資料下標,一般用在 for 迴圈當中""" print(i,child) 輸出:
<list_iterator object at 0x000002192389F630> 0 Once upon a time there were three little sisters; and their names were 1 <a class="sister" href="http://example.com/elsie" id="link1"> <span>Elsie</span> </a> 2 3 <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> 4 and 5 <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a> 6 and they lived at the bottom of a well.
View Code呼叫了 children 屬性來選擇,返回結果是生成器型別。再使用 for 迴圈輸出相應的內容。
如果要得到所有的子孫節點的話,可以呼叫 descendants 屬性:
from bs4 import BeautifulSoup soup=BeautifulSoup(html,'lxml') print(soup.p.descendants) for i,child in enumerate(soup.p.descendants): print(i,child) 輸出:
<generator object descendants at 0x0000022B542F9410> 0 Once upon a time there were three little sisters; and their names were 1 <a class="sister" href="http://example.com/elsie" id="link1"> <span>Elsie</span> </a> 2 3 <span>Elsie</span> 4 Elsie 5 6 7 <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> 8 Lacie 9 and 10 <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a> 11 Tillie 12 and they lived at the bottom of a well.
View Code返回結果是生成器。遍歷輸出可以看到,輸出結果包含了 span 節點。descendants 會遞迴查詢所有子節點,得到所有的子孫節點
-
-
父節點和祖先節點
-
如果要獲取某個節點元素的父節點,可以呼叫 parent 屬性:
from bs4 import BeautifulSoup soup=BeautifulSoup(html,'lxml') print(soup.a.parent) 輸出:
<p class="story"> Once upon a time there were three little sisters; and their names were <a class="sister" href="http://example.com/elsie" id="link1"> <span>Elsie</span> </a> <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a> and they lived at the bottom of a well. </p>
View Code這裡我們選擇的是第一個 a節點的父節點元素。它的父節點是 p節點,輸出結果便是p節點及其內部的內容。
注意:這裡輸出的僅僅是 a 節點的直接父節點,而沒有再向外尋找父節點的祖先節點。如果想獲取所有的祖先節點,呼叫 parents 屬性:
html = ''' <html> <body> <p class='story'> <a href="http://example.com/elsie" class="sister" id="link1"> <span>Elsie</span> </a> </p> ''' from bs4 import BeautifulSoup soup=BeautifulSoup(html,'lxml') print(soup.a.parents) print(list(enumerate(soup.a.parents))) 輸出:
<generator object parents at 0x0000011701B69410> [(0, <p class="story"> <a class="sister" href="http://example.com/elsie" id="link1"> <span>Elsie</span> </a> </p>), (1, <body> <p class="story"> <a class="sister" href="http://example.com/elsie" id="link1"> <span>Elsie</span> </a> </p> </body>), (2, <html> <body> <p class="story"> <a class="sister" href="http://example.com/elsie" id="link1"> <span>Elsie</span> </a> </p> </body></html>), (3, <html> <body> <p class="story"> <a class="sister" href="http://example.com/elsie" id="link1"> <span>Elsie</span> </a> </p> </body></html>)]
View Code返回結果是生成器型別。用列表輸出了它的索引和內容,而列表中的元素就是 a 節點的祖先節點。
-
-
兄弟節點
-
html = ''' <html> <body> <p class="story"> Once upon a time there were three sisters;and their names were <a href="http://example.com/elsie" class="sister" id="link1"> <span>Elsie</span> </a> Hello <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a> and they lived at the bottom of a well. </p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml') print('Next Sibling', soup.a.next_sibling) print('Prev Sibling', soup.a.previous_sibling) print('Next Sibling', list(enumerate(soup.a.next_siblings))) print('Prev Sibling', list(enumerate(soup.a.previous_siblings))) 輸出:
Next Sibling Hello Prev Sibling Once upon a time there were three sisters;and their names were Next Sibling [(0, '\n Hello\n'), (1, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>), (2, '\n and\n'), (3, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>), (4, '\n and they lived at the bottom of a well.\n')] Prev Sibling [(0, '\n Once upon a time there were three sisters;and their names were \n')]
View Code這裡呼叫了4 個屬性,其中 next_sibling和previous_sibling 獲取節點的下一個 上一個兄弟元素, next_siblings和 previous_siblings 則分別返回所有前面和後面 兄弟節點的生成器
-
- 資訊提取
-
html = ''' <html> <body> <p class="story"> Once upon a time there were three sisters;and their names were <a href="http://example.com/elsie" class="sister" id="link1">BOb</a><a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> </p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml') print('Next Sibling:') print(type(soup.a.previous_sibling)) print(soup.a.next_sibling) print(soup.a.next_sibling.string) print('Parent:') print(type(soup.a.parents)) print(list(soup.a.parents)[0]) print(list(soup.a.parents)[0].attrs['class']) 輸出:
Next Sibling: <class 'bs4.element.NavigableString'> <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> Lacie Parent: <class 'generator'> <p class="story"> Once upon a time there were three sisters;and their names were <a class="sister" href="http://example.com/elsie" id="link1">BOb</a><a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> </p> ['story']
View Code如果返回結果是單個節點,可以直接呼叫 string attrs 等屬性獲得其文字和屬性;如果返回結果是多個節點的生成器,則可以轉為列表後取出某個元素,然後再呼叫 string attrs 等屬性獲 取其對應節點的文字和屬性。
-
-
方法選擇器
-
前面所講選擇方法是通過屬性來選擇的,這種方法非常快,但是如果進行比較複雜的選擇的話,它就比較煩瑣,不夠靈活。
-
find_all()
-
是查詢所有符合條件的元素給它傳入一些屬性或文字,就可以得到符合條件的元素。API 如下:
find_all(name,attrs,recursive,text,**kwargs)
- name
- 可以更加節點來查詢元素,示例:
html = ''' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element">Foo</li> <li cass= "element">Bar</li> <li cass= "element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class= "element">Foo</li> <li class="element">Bar</li> </ul> </div> </div> ''' from bs4 import BeautifulSoup soup=BeautifulSoup(html,'lxml') print(soup.find_all(name='ul')) print(type(soup.find_all(name='ul')[0])) 輸出:
[<ul class="list" id="list-1"> <li class="element">Foo</li> <li cass="element">Bar</li> <li cass="element">Jay</li> </ul>, <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <li class="element">Bar</li> </ul>] <class 'bs4.element.Tag'>
View Code呼叫了 find_all()方法,傳入 name 引數,其引數值為 ul。也就是說,想要查詢所有 ul 節點,返回結果是列表型別,長度為2,每個元素依然都是 bs4.element.Tag型別。
因為都是 Tag 型別,所以依然可以進行巢狀查詢 還是同樣的文字,這裡查詢出所有 節點後, 再繼續查詢其內部的 li 節點:for ul in soup.find_all(name='ul'): print(ul.find_all(name='li')) 輸出: [<li class="element">Foo</li>, <li cass="element">Bar</li>, <li cass="element">Jay</li>] [<li class="element">Foo</li>, <li class="element">Bar</li>]
返回結果是列表型別,列表中的每個元素依然還是 ag 型別。
接下來,可以遍歷每個 li ,獲取它的文字了:for ul in soup.find_all(name='ul'): print(ul.find_all(name='li')) for li in ul.find_all(name='li'): print(li.string) 輸出:
[<li class="element">Foo</li>, <li cass="element">Bar</li>, <li cass="element">Jay</li>] Foo Bar Jay [<li class="element">Foo</li>, <li class="element">Bar</li>] Foo Bar
View Code
- 可以更加節點來查詢元素,示例:
-
atrrs
-
除了根據節點名查詢,我們也可以傳入一些屬性來查詢,示例:
html = ''' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1" name="elements"> <li class="element">Foo</li> <li cass= "element">Bar</li> <li cass= "element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class= "element">Foo</li> <li class="element">Bar</li> </ul> </div> </div> ''' from bs4 import BeautifulSoup soup=BeautifulSoup(html,'lxml') print(soup.find_all(attrs={'id':'list-1'})) print(soup.find_all(attrs={'name':'elements'})) 輸出:
[<ul class="list" id="list-1" name="elements"> <li class="element">Foo</li> <li cass="element">Bar</li> <li cass="element">Jay</li> </ul>] [<ul class="list" id="list-1" name="elements"> <li class="element">Foo</li> <li cass="element">Bar</li> <li cass="element">Jay</li> </ul>]
View Code查詢的時候傳入的是 attrs 引數,引數的型別是字典型別,如要查詢 id為 list-1 的節 點,可以傳入 attrs ={'id' :' list-1'}查詢條件,得到的結果是列表形式,包含的內容就是符合id為 list-1 的所有節點。以上示例,符合條件的元素個數是1,所以結果是長度為 1 的列表。
一些常用的屬性,比如 id 和 class 等,可以不用 attrs 來傳遞。如,要查詢 id為 list-1 的節點,可以直接傳人 id 這個引數。換種方式查詢:
html = ''' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1" name="elements"> <li class="element">Foo</li> <li cass= "element">Bar</li> <li cass= "element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class= "element">Foo</li> <li class="element">Bar</li> </ul> </div> </div> ''' from bs4 import BeautifulSoup soup=BeautifulSoup(html,'lxml') print(soup.find_all(id='list-1')) print(soup.find_all(class_ ='element')) 輸出:
[<ul class="list" id="list-1" name="elements"> <li class="element">Foo</li> <li cass="element">Bar</li> <li cass="element">Jay</li> </ul>] [<li class="element">Foo</li>, <li class="element">Foo</li>, <li class="element">Bar</li>]
View Code直接傳入 id = 'list-1', 就可以查詢 id為list-1的節點元素。對於 class 來說,由於 class在Python 裡是一個關鍵字,所以後面需要加一個下劃線,即 class_ = 'element' ,返回結果依然是Tag。
-
-
text
- text引數可用來匹配節點的文字,傳入的形式可以是字串,可以是正則表示式物件,示例:
import re html = ''' <div class="panel"> <div class="panel-body"> <a>Hello,this is a link</a> <a>Hello,this is a link,too</a> </div> </div> ''' from bs4 import BeautifulSoup soup=BeautifulSoup(html,'lxml') print(soup.find_all(text=re.compile('link'))) 輸出:
['Hello,this is a link', 'Hello,this is a link,too']
這裡有兩個 a 節點,內部包含文字資訊。這裡在 find_all() 方法傳人text 引數,該引數為正則表示式物件,結果返回所有匹配正則表示式的節點文字組成的列表。
- find()
- find()方法返回單個元素 ,也就是第一個匹配的元素。示例:
from bs4 import BeautifulSoup soup=BeautifulSoup(html,'lxml') print(soup.find(name='ul')) print(soup.find(class_ ='element')) print(type(soup.find(name='ul'))) 輸出:
<ul class="list" id="list-1"> <li class="element">Foo</li> <li cass="element">Bar</li> <li cass="element">Jay</li> </ul> <li class="element">Foo</li> <class 'bs4.element.Tag'>
View Code返回結果不再是列表形式,是第一個匹配的節點元素,型別依然是 Tag 型別。
還有許多查詢方法,其用方法與前面介紹的 find_all(), find() 方法完全相同, 只不過查詢範圍不同- find_parents()和find_parents(): 前者返回 所有祖先節點,後者返回直接父節點。
- find_next_siblings()和find_next_sibling(): 前者返回後面所有的兄弟節點,後者返回後面第一個兄弟節點
- find_previous_siblings()和find_previous_sibling(): 前者返回前面所有的兄弟節點 ,後者返回前面第一個兄弟節點
- find_all_next()和find_previous(): 前者返回節點後所有符合條件的節點,後者返回第一個符合條件的節點
- find_all_previous()和find_previous():前者返回節點後所有符合條件的節點,後者返回第 一個符合條件的節點
- text引數可用來匹配節點的文字,傳入的形式可以是字串,可以是正則表示式物件,示例:
-
-
- CSS選擇器
- 使用 css 選擇器時,只需要呼叫 select()方法,傳人相應的 css 選擇器即可,示例:
html = ''' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element">Foo</li> <li cass= "element">Bar</li> <li cass= "element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class= "element">Foo</li> <li class="element">Bar</li> </ul> </div> </div> ''' from bs4 import BeautifulSoup soup=BeautifulSoup(html,'lxml') print(soup.select('.panel .panel-heading')) print(soup.select('ul li')) print(soup.select('#list-2 .element')) print(type(soup.select('ul')[0])) 輸出:
[<div class="panel-heading"> <h4>Hello</h4> </div>] [<li class="element">Foo</li>, <li cass="element">Bar</li>, <li cass="element">Jay</li>, <li class="element">Foo</li>, <li class="element">Bar</li>] [<li class="element">Foo</li>, <li class="element">Bar</li>] <class 'bs4.element.Tag'>
View Code這裡用了CSS 選擇器,返回的結果均是符合 css 選擇器的節點組成的列表 。如, select( ’ ul li ’)則是選擇所有 ul 節點下面的所有li 節點,結果所有的 li 節點組成的列表。輸出列表中元素的型別依然是 Tag 型別。
- 巢狀選擇
- select()方法同樣支援巢狀選擇。如,先選擇所有 ul 節點,再遍歷每個 ul 節點,選擇其 li節點,示例:
from bs4 import BeautifulSoup soup=BeautifulSoup(html,'lxml') for ul in soup.select('ul'): print(ul.select('li')) 輸出:
[<li class="element">Foo</li>, <li cass="element">Bar</li>, <li cass="element">Jay</li>] [<li class="element">Foo</li>, <li class="element">Bar</li>]
正常輸出了所有 ul 節點下所有 li 節點組成的列表
- select()方法同樣支援巢狀選擇。如,先選擇所有 ul 節點,再遍歷每個 ul 節點,選擇其 li節點,示例:
-
獲取屬性
- 節點型別是 Tag 型別,獲取屬性可以用原來的方法。仍然是以上的 HTML 文字, 嘗試獲取每個 ul 節點的 id 屬性:
from bs4 import BeautifulSoup soup=BeautifulSoup(html, 'lxml') for ul in soup.select('ul'): print(ul['id']) print(ul.attrs['id']) 輸出:
list-1 list-1 list-2 list-2
View Code接傳入中括號和屬性名,以及通過 attrs 屬性獲取屬性值,都可以成功。
- 節點型別是 Tag 型別,獲取屬性可以用原來的方法。仍然是以上的 HTML 文字, 嘗試獲取每個 ul 節點的 id 屬性:
-
獲取文字
-
獲取文字,除了可以用 string 屬性。還有一個方法,那就是 get_text() ,效果一致。示例:
from bs4 import BeautifulSoup soup=BeautifulSoup(html, 'lxml') for li in soup.select('li'): print('Get Text:',li.get_text()) print('string:',li.string) 輸出:
Get Text: Foo string: Foo Get Text: Bar string: Bar Get Text: Jay string: Jay Get Text: Foo string: Foo Get Text: Bar string: BarView Code
-
- 使用 css 選擇器時,只需要呼叫 select()方法,傳人相應的 css 選擇器即可,示例:
-
-
小結:
- 使用lxml解析庫,必要時使用html.parse.
- 節點篩選功能弱,但是速度快。
- 使用find()或者find_all()查詢匹配單個結果或者多個結果
- CSS選擇器,可以使用select()方法選擇