
Spark的運算元的分類與詳解
Spark的運算元的分類
從大方向來說,Spark 運算元大致可以分為以下兩類:
1)Transformation 變換/轉換運算元:這種變換並不觸發提交作業,完成作業中間過程處理。
Transformation 操作是延遲計算的,也就是說從一個RDD 轉換生成另一個 RDD 的轉換操作不是馬上執行,需要等到有 Action 操作的時候才會真正觸發運算。
2)Action 行動運算元:這類運算元會觸發 SparkContext 提交 Job 作業。
Action 運算元會觸發 Spark 提交作業(Job),並將資料輸出 Spark系統。
從小方向來說,Spark 運算元大致可以分為以下三類:
1)Value資料型別的Transformation運算元,這種變換並不觸發提交作業,針對處理的資料項是Value型的資料。 2)Key-Value資料型別的Transfromation運算元,這種變換並不觸發提交作業,針對處理的資料項是Key-Value型的資料對。
3)Action運算元,這類運算元會觸發SparkContext提交Job作業。
1)Value資料型別的Transformation運算元
一、輸入分割槽與輸出分割槽一對一型
1、map運算元
2、flatMap運算元
3、mapPartitions運算元
4、glom運算元
二、輸入分割槽與輸出分割槽多對一型
5、union運算元
6、cartesian運算元
三、輸入分割槽與輸出分割槽多對多型
7、grouBy運算元
四、輸出分割槽為輸入分割槽子集型
8、filter運算元
9、distinct運算元
10、subtract運算元
11、sample運算元
12、takeSample運算元
五、Cache型
13、cache運算元
14、persist運算元
2)Key-Value資料型別的Transfromation運算元
一、輸入分割槽與輸出分割槽一對一
15、mapValues運算元
二、對單個RDD或兩個RDD聚集
單個RDD聚集
16、combineByKey運算元
17、reduceByKey運算元
18、partitionBy運算元
兩個RDD聚集
19、Cogroup運算元
三、連線
20、join運算元
21、leftOutJoin和 rightOutJoin運算元
3)Action運算元
一、無輸出
22、foreach運算元
二、HDFS
23、saveAsTextFile運算元
24、saveAsObjectFile運算元
三、Scala集合和資料型別
25、collect運算元
26、collectAsMap運算元
27、reduceByKeyLocally運算元
28、lookup運算元
29、count運算元
30、top運算元
31、reduce運算元
32、fold運算元
33、aggregate運算元
運算元詳解:
1. Transformations 運算元 (1) map
將原來 RDD 的每個資料項通過 map 中的使用者自定義函式 f 對映轉變為一個新的元素。原始碼中 map 運算元相當於初始化一個 RDD, 新 RDD 叫做 MappedRDD(this, sc.clean(f))。
圖 1中每個方框表示一個 RDD 分割槽,左側的分割槽經過使用者自定義函式 f:T->U 對映為右側的新 RDD 分割槽。但是,實際只有等到 Action運算元觸發後,這個 f 函式才會和其他函式在一個stage 中對資料進行運算。在圖 1 中的第一個分割槽,資料記錄 V1 輸入 f,通過 f 轉換輸出為轉換後的分割槽中的資料記錄 V’1。
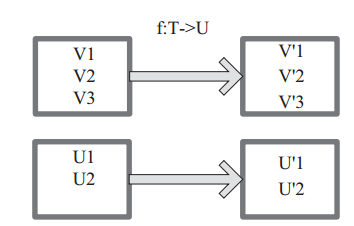
圖1 map 運算元對 RDD 轉換
(2) flatMap 將原來 RDD 中的每個元素通過函式 f 轉換為新的元素,並將生成的 RDD 的每個集合中的元素合併為一個集合,內部建立 FlatMappedRDD(this,sc.clean(f))。 圖 2 表 示 RDD 的 一 個 分 區 ,進 行 flatMap函 數 操 作, flatMap 中 傳 入 的 函 數 為 f:T->U, T和 U 可以是任意的資料型別。將分割槽中的資料通過使用者自定義函式 f 轉換為新的資料。外部大方框可以認為是一個 RDD 分割槽,小方框代表一個集合。 V1、 V2、 V3 在一個集合作為 RDD 的一個數據項,可能儲存為陣列或其他容器,轉換為V’1、 V’2、 V’3 後,將原來的陣列或容器結合拆散,拆散的資料形成為 RDD 中的資料項。
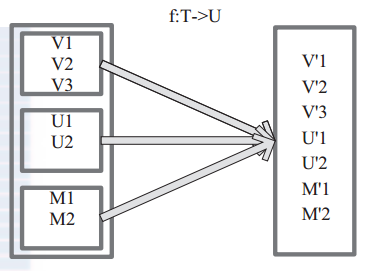
圖2 flapMap 運算元對 RDD 轉換
(3) mapPartitions
mapPartitions 函 數 獲 取 到 每 個 分 區 的 迭 代器,在 函 數 中 通 過 這 個 分 區 整 體 的 迭 代 器 對整 個 分 區 的 元 素 進 行 操 作。 內 部 實 現 是 生 成
MapPartitionsRDD。圖 3 中的方框代表一個 RDD 分割槽。圖 3 中,使用者通過函式 f (iter)=>iter.f ilter(_>=3) 對分割槽中所有資料進行過濾,大於和等於 3 的資料保留。一個方塊代表一個 RDD 分割槽,含有 1、 2、 3 的分割槽過濾只剩下元素 3。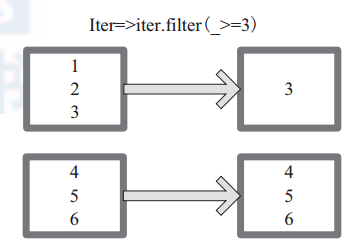
圖3 mapPartitions 運算元對 RDD 轉換
(4)glom
glom函式將每個分割槽形成一個數組,內部實現是返回的GlommedRDD。 圖4中的每個方框代表一個RDD分割槽。圖4中的方框代表一個分割槽。 該圖表示含有V1、 V2、 V3的分割槽通過函式glom形成一陣列Array[(V1),(V2),(V3)]。
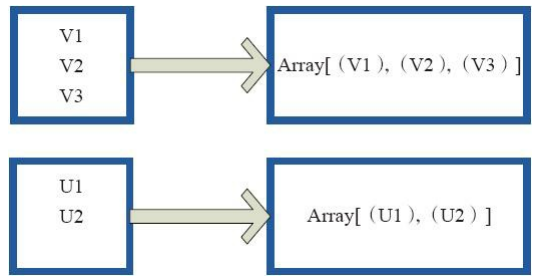
圖 4 glom運算元對RDD轉換
(5) union 使用 union 函式時需要保證兩個 RDD 元素的資料型別相同,返回的 RDD 資料型別和被合併的 RDD 元素資料型別相同,並不進行去重操作,儲存所有元素。如果想去重 可以使用 distinct()。同時 Spark 還提供更為簡潔的使用 union 的 API,通過 ++ 符號相當於 union 函式操作。 圖 5 中左側大方框代表兩個 RDD,大方框內的小方框代表 RDD 的分割槽。右側大方框代表合併後的 RDD,大方框內的小方框代表分割槽。
含有V1、V2、U1、U2、U3、U4的RDD和含有V1、V8、U5、U6、U7、U8的RDD合併所有元素形成一個RDD。V1、V1、V2、V8形成一個分割槽,U1、U2、U3、U4、U5、U6、U7、U8形成一個分割槽。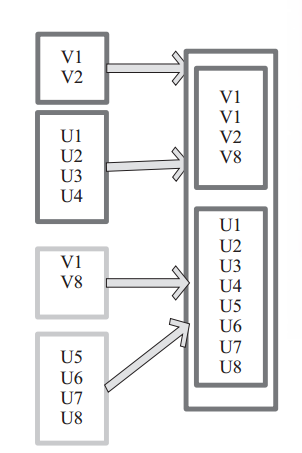 圖 5 union 運算元對 RDD 轉換
圖 5 union 運算元對 RDD 轉換
(6) cartesian
對 兩 個 RDD 內 的 所 有 元 素 進 行 笛 卡 爾 積 操 作。 操 作 後, 內 部 實 現 返 回CartesianRDD。圖6中左側大方框代表兩個 RDD,大方框內的小方框代表 RDD 的分割槽。右側大方框代表合併後的 RDD,大方框內的小方框代表分割槽。圖6中的大方框代表RDD,大方框中的小方框代表RDD分割槽。
例 如: V1 和 另 一 個 RDD 中 的 W1、 W2、 Q5 進 行 笛 卡 爾 積 運 算 形 成 (V1,W1)、(V1,W2)、 (V1,Q5)。
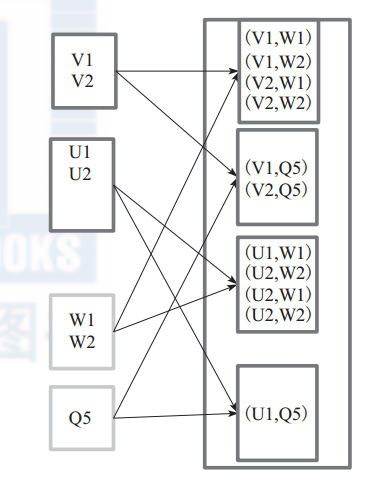
圖 6 cartesian 運算元對 RDD 轉換
(7) groupBy groupBy :將元素通過函式生成相應的 Key,資料就轉化為 Key-Value 格式,之後將 Key 相同的元素分為一組。 函式實現如下: 1)將使用者函式預處理: val cleanF = sc.clean(f) 2)對資料 map 進行函式操作,最後再進行 groupByKey 分組操作。
this.map(t => (cleanF(t), t)).groupByKey(p) 其中, p 確定了分割槽個數和分割槽函式,也就決定了並行化的程度。
圖7 中方框代表一個 RDD 分割槽,相同key 的元素合併到一個組。例如 V1 和 V2 合併為 V, Value 為 V1,V2。形成 V,Seq(V1,V2)。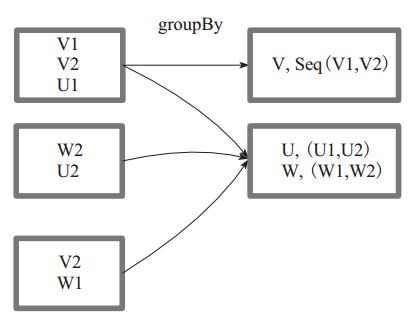 圖 7 groupBy 運算元對 RDD 轉換
圖 7 groupBy 運算元對 RDD 轉換
(8) filter filter 函式功能是對元素進行過濾,對每個 元 素 應 用 f 函 數, 返 回 值 為 true 的 元 素 在RDD 中保留,返回值為 false 的元素將被過濾掉。 內 部 實 現 相 當 於 生 成 FilteredRDD(this,sc.clean(f))。 下面程式碼為函式的本質實現: deffilter(f:T=>Boolean):RDD[T]=newFilteredRDD(this,sc.clean(f)) 圖 8 中每個方框代表一個 RDD 分割槽, T 可以是任意的型別。通過使用者自定義的過濾函式 f,對每個資料項操作,將滿足條件、返回結果為 true 的資料項保留。例如,過濾掉 V2 和 V3 保留了 V1,為區分命名為 V’1。
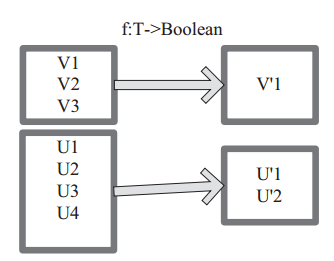
圖 8 filter 運算元對 RDD 轉換
(9)distinct
distinct將RDD中的元素進行去重操作。圖9中的每個方框代表一個RDD分割槽,通過distinct函式,將資料去重。 例如,重複資料V1、 V1去重後只保留一份V1。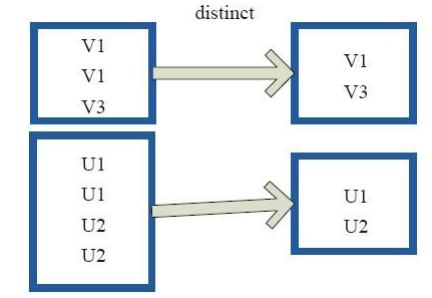
圖9 distinct運算元對RDD轉換
(10)subtract
subtract相當於進行集合的差操作,RDD 1去除RDD 1和RDD 2交集中的所有元素。圖10中左側的大方框代表兩個RDD,大方框內的小方框代表RDD的分割槽。 右側大方框
代表合併後的RDD,大方框內的小方框代表分割槽。 V1在兩個RDD中均有,根據差集運算規則,新RDD不保留,V2在第一個RDD有,第二個RDD沒有,則在新RDD元素中包含V2。
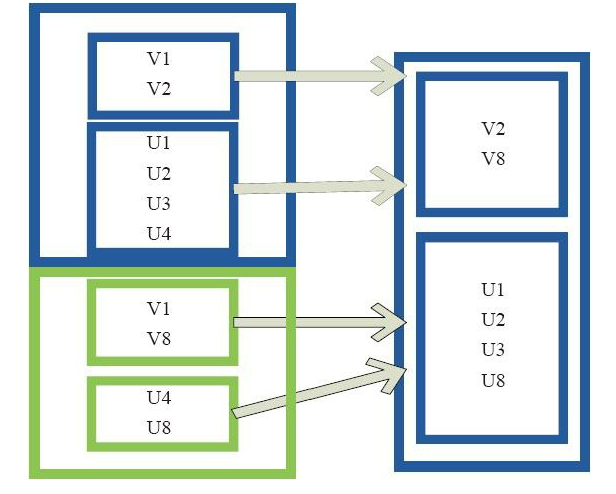
圖10 subtract運算元對RDD轉換
(11) sample sample 將 RDD 這個集合內的元素進行取樣,獲取所有元素的子集。使用者可以設定是否有放回的抽樣、百分比、隨機種子,進而決定取樣方式。內部實現是生成 SampledRDD(withReplacement, fraction, seed)。 函式引數設定: ‰ withReplacement=true,表示有放回的抽樣。 ‰ withReplacement=false,表示無放回的抽樣。 圖 11中 的 每 個 方 框 是 一 個 RDD 分 區。 通 過 sample 函 數, 採 樣 50% 的 數 據。V1、 V2、 U1、 U2、U3、U4 取樣出資料 V1 和 U1、 U2 形成新的 RDD。
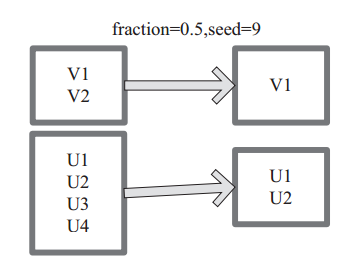
圖11 sample 運算元對 RDD 轉換
(12)takeSample
takeSample()函式和上面的sample函式是一個原理,但是不使用相對比例取樣,而是按設定的取樣個數進行取樣,同時返回結果不再是RDD,而是相當於對取樣後的資料進行 Collect(),返回結果的集合為單機的陣列。 圖12中左側的方框代表分散式的各個節點上的分割槽,右側方框代表單機上返回的結果陣列。 通過takeSample對資料取樣,設定為取樣一份資料,返回結果為V1。
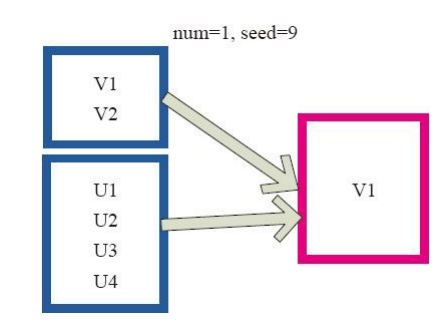
圖12 takeSample運算元對RDD轉換
(13) cache
cache 將 RDD 元素從磁碟快取到記憶體。 相當於 persist(MEMORY_ONLY) 函式的功能。
圖13 中每個方框代表一個 RDD 分割槽,左側相當於資料分割槽都儲存在磁碟,通過 cache 運算元將資料快取在記憶體。
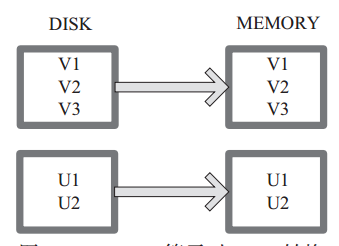
圖 13 Cache 運算元對 RDD 轉換
(14) persist persist 函式對 RDD 進行快取操作。資料快取在哪裡依據 StorageLevel 這個列舉型別進行確定。 有以下幾種型別的組合(見10), DISK 代表磁碟,MEMORY 代表記憶體, SER 代表資料是否進行序列化儲存。
下面為函式定義, StorageLevel 是列舉型別,代表儲存模式,使用者可以通過圖 14-1 按需進行選擇。
persist(newLevel:StorageLevel)
圖 14-1 中列出persist 函式可以進行快取的模式。例如,MEMORY_AND_DISK_SER 代表資料可以儲存在記憶體和磁碟,並且以序列化的方式儲存,其他同理。
圖 14-1 persist 運算元對 RDD 轉換
圖 14-2 中方框代表 RDD 分割槽。 disk 代表儲存在磁碟, mem 代表儲存在記憶體。資料最初全部儲存在磁碟,通過 persist(MEMORY_AND_DISK) 將資料快取到記憶體,但是有的分割槽無法容納在記憶體,將含有 V1、 V2、 V3 的RDD儲存到磁碟,將含有U1,U2的RDD仍舊儲存在記憶體。
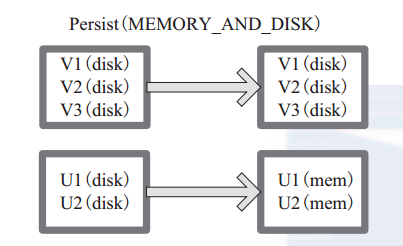
圖 14-2 Persist 運算元對 RDD 轉換
(15) mapValues mapValues :針對(Key, Value)型資料中的 Value 進行 Map 操作,而不對 Key 進行處理。
圖 15 中的方框代表 RDD 分割槽。 a=>a+2 代表對 (V1,1) 這樣的 Key Value 資料對,資料只對 Value 中的 1 進行加 2 操作,返回結果為 3。
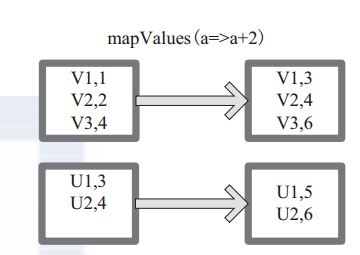
圖 15 mapValues 運算元 RDD 對轉換
(16) combineByKey 下面程式碼為 combineByKey 函式的定義: combineByKey[C](createCombiner:(V) C, mergeValue:(C, V) C, mergeCombiners:(C, C) C, partitioner:Partitioner, mapSideCombine:Boolean=true, serializer:Serializer=null):RDD[(K,C)]
說明: ‰ createCombiner: V => C, C 不存在的情況下,比如通過 V 建立 seq C。 ‰ mergeValue: (C, V) => C,當 C 已經存在的情況下,需要 merge,比如把 item V 加到 seq C 中,或者疊加。 mergeCombiners: (C, C) => C,合併兩個 C。 ‰ partitioner: Partitioner, Shuff le 時需要的 Partitioner。 ‰ mapSideCombine : Boolean = true,為了減小傳輸量,很多 combine 可以在 map 端先做,比如疊加,可以先在一個 partition 中把所有相同的 key 的 value 疊加, 再 shuff le。 ‰ serializerClass: String = null,傳輸需要序列化,使用者可以自定義序列化類:
例如,相當於將元素為 (Int, Int) 的 RDD 轉變為了 (Int, Seq[Int]) 型別元素的 RDD。圖 16中的方框代表 RDD 分割槽。如圖,通過 combineByKey, 將 (V1,2), (V1,1)資料合併為( V1,Seq(2,1))。
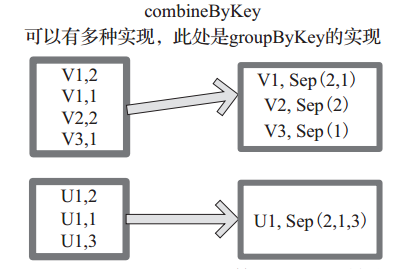
圖 16 comBineByKey 運算元對 RDD 轉換
(17) reduceByKey
reduceByKey 是比 combineByKey 更簡單的一種情況,只是兩個值合併成一個值,( Int, Int V)to (Int, Int C),比如疊加。所以 createCombiner reduceBykey 很簡單,就是直接返回 v,而 mergeValue和 mergeCombiners 邏輯是相同的,沒有區別。
函式實現:
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)]
= {
combineByKey[V]((v: V) => v, func, func, partitioner)
}
圖17中的方框代表 RDD 分割槽。通過使用者自定義函式 (A,B) => (A + B) 函式,將相同 key 的資料 (V1,2) 和 (V1,1) 的 value 相加運算,結果為( V1,3)。
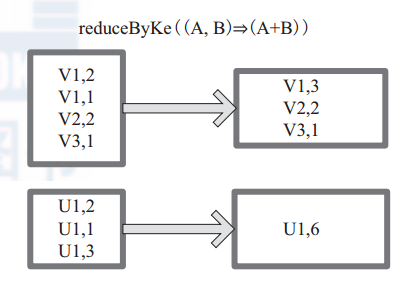
圖 17 reduceByKey 運算元對 RDD 轉換
(18)partitionBy
partitionBy函式對RDD進行分割槽操作。
函式定義如下。
partitionBy(partitioner:Partitioner)
如果原有RDD的分割槽器和現有分割槽器(partitioner)一致,則不重分割槽,如果不一致,則相當於根據分割槽器生成一個新的ShuffledRDD。
圖18中的方框代表RDD分割槽。 通過新的分割槽策略將原來在不同分割槽的V1、 V2資料都合併到了一個分割槽。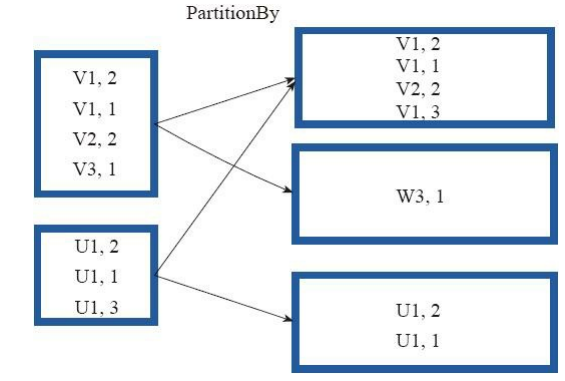
圖18 partitionBy運算元對RDD轉換
(19)Cogroup
cogroup函式將兩個RDD進行協同劃分,cogroup函式的定義如下。 cogroup[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (Iterable[V], Iterable[W]))] 對在兩個RDD中的Key-Value型別的元素,每個RDD相同Key的元素分別聚合為一個集合,並且返回兩個RDD中對應Key的元素集合的迭代器。 (K, (Iterable[V], Iterable[W])) 其中,Key和Value,Value是兩個RDD下相同Key的兩個資料集合的迭代器所構成的元組。 圖19中的大方框代表RDD,大方框內的小方框代表RDD中的分割槽。 將RDD1中的資料(U1,1)、 (U1,2)和RDD2中的資料(U1,2)合併為(U1,((1,2),(2)))。
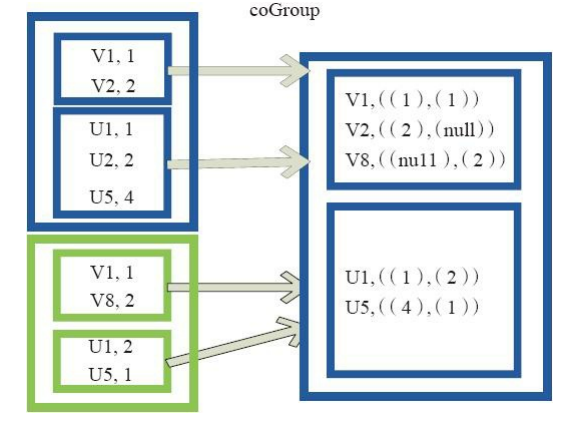
圖19 Cogroup運算元對RDD轉換
(20) join
join 對兩個需要連線的 RDD 進行 cogroup函式操作,將相同 key 的資料能夠放到一個分割槽,在 cogroup 操作之後形成的新 RDD 對每個key 下的元素進行笛卡爾積的操作,返回的結果再展平,對應 key 下的所有元組形成一個集合。最後返回 RDD[(K, (V, W))]。
下 面 代 碼 為 join 的 函 數 實 現, 本 質 是通 過 cogroup 算 子 先 進 行 協 同 劃 分, 再 通 過flatMapValues 將合併的資料打散。
this.cogroup(other,partitioner).f latMapValues{case(vs,ws) => for(v<-vs;w<-ws)yield(v,w) }
圖 20是對兩個 RDD 的 join 操作示意圖。大方框代表 RDD,小方框代表 RDD 中的分割槽。函式對相同 key 的元素,如 V1 為 key 做連線後結果為 (V1,(1,1)) 和 (V1,(1,2))。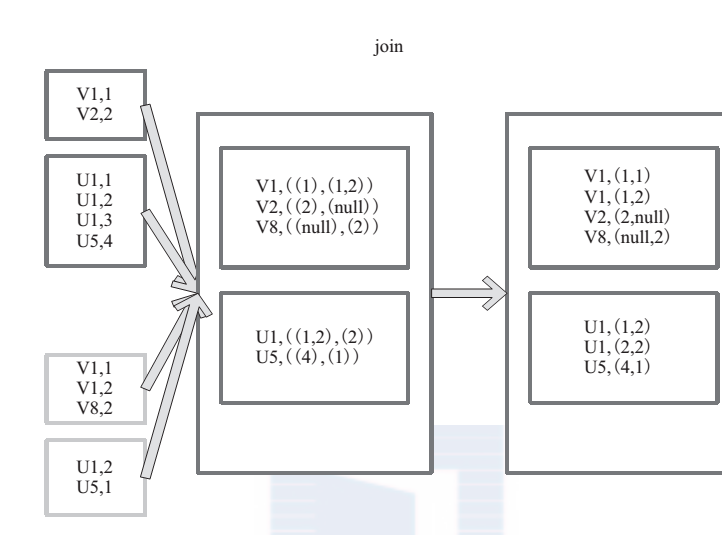
圖 20 join 運算元對 RDD 轉換
(21)eftOutJoin和rightOutJoin
LeftOutJoin(左外連線)和RightOutJoin(右外連線)相當於在join的基礎上先判斷一側的RDD元素是否為空,如果為空,則填充為空。 如果不為空,則將資料進行連線運算,並 返回結果。 下面程式碼是leftOutJoin的實現。 if (ws.isEmpty) { vs.map(v => (v, None)) } else { for (v <- vs; w <- ws) yield (v, Some(w)) }
2. Actions 運算元 本質上在 Action 運算元中通過 SparkContext 進行了提交作業的 runJob 操作,觸發了RDD DAG 的執行。 例如, Action 運算元 collect 函式的程式碼如下,感興趣的讀者可以順著這個入口進行原始碼剖析: /** * Return an array that contains all of the elements in this RDD. */ def collect(): Array[T] = { /* 提交 Job*/ val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray) Array.concat(results: _*) }
(22) foreach
foreach 對 RDD 中的每個元素都應用 f 函式操作,不返回 RDD 和 Array, 而是返回Uint。圖22表示 foreach 運算元通過使用者自定義函式對每個資料項進行操作。本例中自定義函式為 println(),控制檯列印所有資料項。
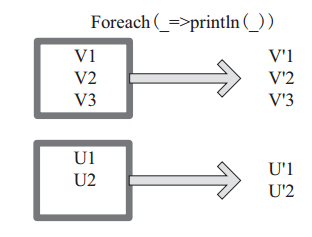
圖 22 foreach 運算元對 RDD 轉換
(23) saveAsTextFile 函式將資料輸出,儲存到 HDFS 的指定目錄。
下面為 saveAsTextFile 函式的內部實現,其內部 通過呼叫 saveAsHadoopFile 進行實現: this.map(x => (NullWritable.get(), new Text(x.toString))).saveAsHadoopFile[TextOutputFormat[NullWritable, Text]](path) 將 RDD 中的每個元素對映轉變為 (null, x.toString),然後再將其寫入 HDFS。 圖 23中左側方框代表 RDD 分割槽,右側方框代表 HDFS 的 Block。通過函式將RDD 的每個分割槽儲存為 HDFS 中的一個 Block。
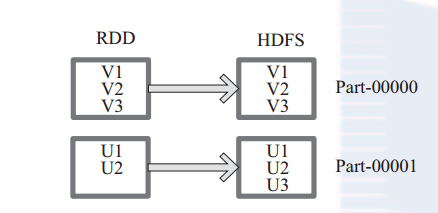
圖 23 saveAsHadoopFile 運算元對 RDD 轉換
(24)saveAsObjectFile
saveAsObjectFile將分割槽中的每10個元素組成一個Array,然後將這個Array序列化,對映為(Null,BytesWritable(Y))的元素,寫入HDFS為SequenceFile的格式。 下面程式碼為函式內部實現。 map(x=>(NullWritable.get(),new BytesWritable(Utils.serialize(x)))) 圖24中的左側方框代表RDD分割槽,右側方框代表HDFS的Block。 通過函式將RDD的每個分割槽儲存為HDFS上的一個Block。
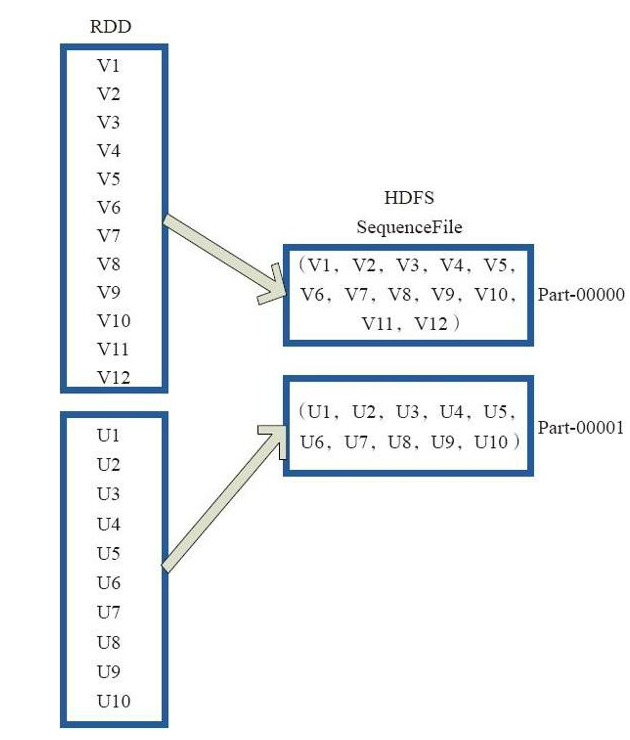
圖24 saveAsObjectFile運算元對RDD轉換
(25) collect collect 相當於 toArray, toArray 已經過時不推薦使用, collect 將分散式的 RDD 返回為一個單機的 scala Array 陣列。在這個陣列上運用 scala 的函式式操作。 圖 25中左側方框代表 RDD 分割槽,右側方框代表單機記憶體中的陣列。通過函式操作,將結果返回到 Driver 程式所在的節點,以陣列形式儲存。
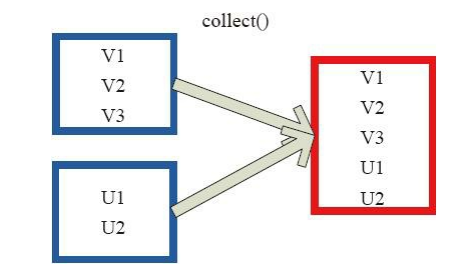
圖 25 Collect 運算元對 RDD 轉換
(26)collectAsMap
collectAsMap對(K,V)型的RDD資料返回一個單機HashMap。 對於重複K的RDD元素,後面的元素覆蓋前面的元素。 圖26中的左側方框代表RDD分割槽,右側方框代表單機陣列。 資料通過collectAsMap函式返回給Driver程式計算結果,結果以HashMap形式儲存。
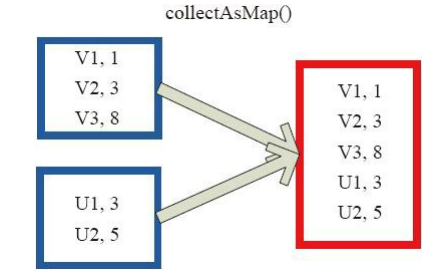
圖26 CollectAsMap運算元對RDD轉換
(27)reduceByKeyLocally
實現的是先reduce再collectAsMap的功能,先對RDD的整體進行reduce操作,然後再收集所有結果返回為一個HashMap。
(28)lookup
下面程式碼為lookup的宣告。 lookup(key:K):Seq[V] Lookup函式對(Key,Value)型的RDD操作,返回指定Key對應的元素形成的Seq。 這個函式處理優化的部分在於,如果這個RDD包含分割槽器,則只會對應處理K所在的分割槽,然後返回由(K,V)形成的Seq。 如果RDD不包含分割槽器,則需要對全RDD元素進行暴力掃描處理,搜尋指定K對應的元素。 圖28中的左側方框代表RDD分割槽,右側方框代表Seq,最後結果返回到Driver所在節點的應用中。
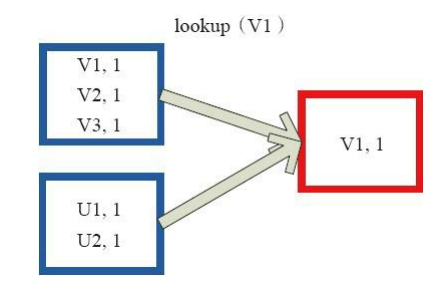
圖28 lookup對RDD轉換
(29) count
count 返回整個 RDD 的元素個數。
內部函式實現為:
defcount():Long=sc.runJob(this,Utils.getIteratorSize_).sum
圖 29中,返回資料的個數為 5。一個方塊代表一個 RDD 分割槽。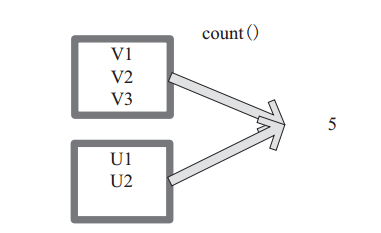
圖29 count 對 RDD 運算元轉換
(30)top
top可返回最大的k個元素。 函式定義如下。 top(num:Int)(implicit ord:Ordering[T]):Array[T]
相近函式說明如下。 ·top返回最大的k個元素。 ·take返回最小的k個元素。 ·takeOrdered返回最小的k個元素,並且在返回的陣列中保持元素的順序。 ·first相當於top(1)返回整個RDD中的前k個元素,可以定義排序的方式Ordering[T]。 返回的是一個含前k個元素的陣列。
(31)reduce
reduce函式相當於對RDD中的元素進行reduceLeft函式的操作。 函式實現如下。 Some(iter.reduceLeft(cleanF)) reduceLeft先對兩個元素<K,V>進行reduce函式操作,然後將結果和迭代器取出的下一個元素<k,V>進行reduce函式操作,直到迭代器遍歷完所有元素,得到最後結果。在RDD中,先對每個分割槽中的所有元素<K,V>的集合分別進行reduceLeft。 每個分割槽形成的結果相當於一個元素<K,V>,再對這個結果集合進行reduceleft操作。 例如:使用者自定義函式如下。 f:(A,B)=>(A._1+”@”+B._1,A._2+B._2) 圖31中的方框代表一個RDD分割槽,通過使用者自定函式f將資料進行reduce運算。 示例 最後的返回結果為[email protected][1]V2U!@[email protected]@U4,12。
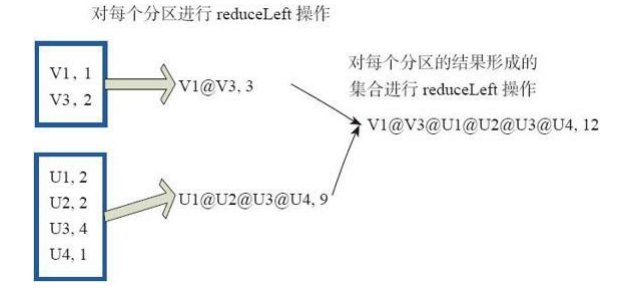
圖31 reduce運算元對RDD轉換
(32)fold
fold和reduce的原理相同,但是與reduce不同,相當於每個reduce時,迭代器取的第一個元素是zeroValue。 圖32中通過下面的使用者自定義函式進行fold運算,圖中的一個方框代表一個RDD分割槽。 讀者可以參照reduce函式理解。 fold((”[email protected]”,2))( (A,B)=>(A._1+”@”+B._1,A._2+B._2))
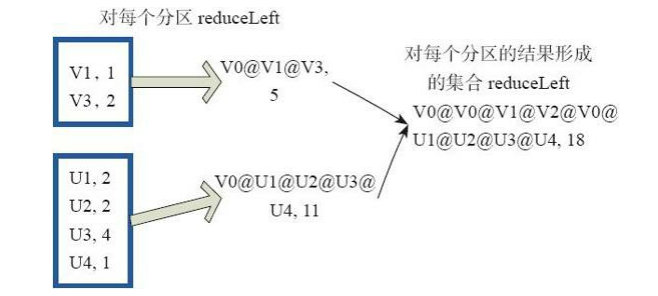
圖32 fold運算元對RDD轉換
(33)aggregate
aggregate先對每個分割槽的所有元素進行aggregate操作,再對分割槽的結果進行fold操作。
aggreagate與fold和reduce的不同之處在於,aggregate相當於採用歸併的方式進行資料聚集,這種聚集是並行化的。 而在fold和reduce函式的運算過程中,每個分割槽中需要進行序列處理,每個分割槽序列計算完結果,結果再按之前的方式進行聚集,並返回最終聚集結果。
函式的定義如下。
aggregate[B](z: B)(seqop: (B,A) => B,combop: (B,B) => B): B
圖33通過使用者自定義函式對RDD 進行aggregate的聚集操作,圖中的每個方框代表一個RDD分割槽。
rdd.aggregate(”[email protected]”,2)((A,B)=>(A._1+”@”+B._1,A._2+B._2)),(A,B)=>(A._1+”@”+B_1,[email protected]+B_.2))
最後,介紹兩個計算模型中的兩個特殊變數。
廣播(broadcast)變數:其廣泛用於廣播Map Side Join中的小表,以及廣播大變數等場景。 這些資料集合在單節點記憶體能夠容納,不需要像RDD那樣在節點之間打散儲存。
Spark執行時把廣播變數資料發到各個節點,並儲存下來,後續計算可以複用。 相比Hadoo的distributed cache,廣播的內容可以跨作業共享。 Broadcast的底層實現採用了BT機制。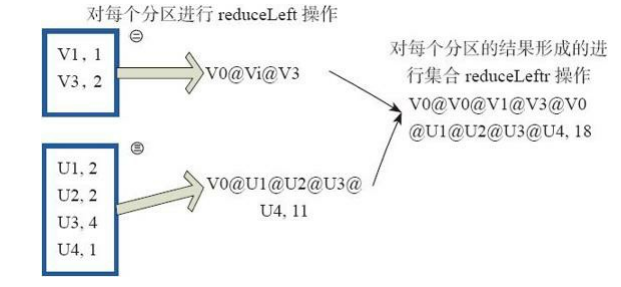
圖33 aggregate運算元對RDD轉換
②代表V。 ③代表U。 accumulator變數:允許做全域性累加操作,如accumulator變數廣泛使用在應用中記錄當前的執行指標的情景。