
爬蟲--解析庫的使用 XPath、BeautifulSoup、pyquery
阿新 • • 發佈:2018-12-10
1. XPath
XPath , 全稱XML Path Language ,即XML 路徑語言,它是一門在XML 文件中查詢資訊的語言。它最初是用來搜尋XML 文件的,但是它同樣適用於HTML 文件的搜尋。
XPath 的選擇功能十分強大,它提供了非常簡潔明瞭的路徑選擇表示式。另外,它還提供了超過100 個內建函式,用於字串、數值、時間的匹配以及節點、序列的處理等。幾乎所有我們想要定位的節點,都可以用XPath 來選擇。

from lxml import etree text = ''' <div> <ul> <li class="item-O"><a href="linkl.html">first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html">third item</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a> </ul> </div> ''' html = etree.HTML(text) result= etree.tostring(html) print(result.decode('utf-8'))

<html><body><div> <ul> <li class="item-O"><a href="linkl.html">first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html">third item</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a> </li></ul> </div> </body></html>


7. 父節點
from lxml import etree html = etree.parse('F:\\spider\\XPath\\test.html', etree.HTMLParser()) result = etree.tostring(html) res = html.xpath('//a[@href="link4.html"]/../@class') # 或者下面的寫法 # res = html.xpath('//a[@href="link4.html"]/parent::*/@class') print(result.decode('utf-8')) print('\n', res)


9. 文字獲取
from lxml import etree
html = etree.parse('F:\\spider\\XPath\\test.html', etree.HTMLParser())
res = html.xpath('//li[@class="item-0"]/a/text()') # 文字獲取
print(res)
# ['first item', 'fifth item']這裡我們是逐層選取的,先選取了li 節點,又利用/選取了其直接子節點兒然後再選取其文字,得到的結果恰好是符合我們預期的兩個結果。
from lxml import etree
html = etree.parse('F:\\spider\\XPath\\test.html', etree.HTMLParser())
res = html.xpath('//li[@class="item-0"]//text()') # 文字獲取
print(res)
# ['first item', 'fifth item', '\r\n\t']不出所料,這裡的返回結果是3 個。可想而知,這裡是選取所有子孫節點的文字,其中前兩個就是li 的子節點a 節點內部的文字,另外一個就是最後一個li 節點內部的文字,即換行符。
10 . 屬性獲取 我們知道用text ()可以獲取節點內部文字,那麼節點屬性該怎樣獲取呢?其實還是用@符號就可以。例如,我們想獲取所有li 節點下所有a 節點的href 屬性,程式碼如下:
from lxml import etree
# 屬性獲取
html = etree.parse('F:\\spider\\XPath\\test.html', etree.HTMLParser())
res = html.xpath('//li/a/@href') # 文字獲取
print(res)
# ['linkl.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html']

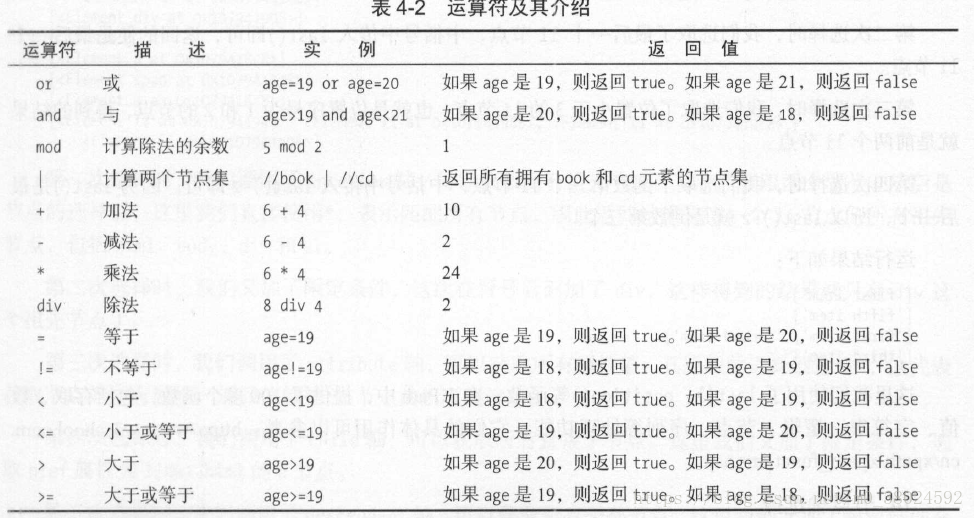
13. 按序選擇
有時候,我們在選擇的時候某些屬性可能同時匹配了多個節點,但是隻想要其中的某個節點,如第二個節點或者最後一個節點。這時可以利用中括號傳入索引的方法獲取特定次序的節點。
from lxml import etree
text = '''
<div>
<ul>
<li class="item-O"><a href="linkl.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.parse("F:/spider/XPath/test.html", etree.HTMLParser())
res = html.xpath("//li/a/text()") # 注意:這裡的下標從1開始
res1 = html.xpath("//li[1]/a/text()")
res2 = html.xpath("//li[last()]/a/text()")
res3 = html.xpath("//li[position()<3]/a/text()")
res5 = html.xpath("//li[last()-2]/a/text()")
print(res, res1, res2, res3, res5, sep='\n')
# ['first item', 'second item', 'third item', 'fourth item', 'fifth item']
# ['first item']
# ['fifth item']
# ['first item', 'second item']
# ['third item']第一次選擇時,我們選取了第一個li 節點,中括號中傳入數字1即可。注意,這裡和程式碼中不同,序號是以1 開頭的,不是以0 開頭。
14. 節點軸選擇
XPath 提供了很多節點軸選擇方法,包括獲取子元素、兄弟元素、父元素、祖先元素等。
from lxml import etree
text = '''
<div>
<ul>
<li class="item-O"><a href="link1.html"><span>first item</span></a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text)
res = html.xpath("//li[1]/ancestor::*") # 注意:這裡的下標從1開始
print(res)
# [<Element html at 0x1991a74efc8>, <Element body at 0x1991a720dc8>, <Element div at 0x1991a760488>, <Element ul at 0x1991a760848>]
res = html.xpath("//li[1]/ancestor::div")
print(res)
# [<Element div at 0x1991a6c0188>]
res = html.xpath("//li[1]/attribute::*")
print(res)
# ['item-O']
res = html.xpath('//li[1]/child::a[@href="link1.html"]')
print(res)
# [<Element a at 0x1991a760308>]
res = html.xpath("//li[1]/descendant::span")
print(res)
# [<Element span at 0x1991a7688c8>]
res = html.xpath('//li[1]/following::*[1]')
print(res)
# [<Element li at 0x1991a6c02c8>]
res = html.xpath('//li[1]/following-sibling::*')
print(res)
# [<Element li at 0x1991a74ed48>, <Element li at 0x1991a74e748>, <Element li at 0x1991a720dc8>, <Element li at 0x1991a720bc8>]
