
大資料-Hadoop生態(13)-MapReduce框架原理--Job提交原始碼和切片原始碼解析
1.MapReduce的資料流

1) Input -> Mapper階段
輸入源是一個檔案,經過InputFormat之後,到了Mapper就成了K,V對,以上一章的流量案例來說,經過InputFormat之後,變成了手機號為key,這一行資料為value的K,V對,所以這裡我們可以自定義InputFormat,按照具體的業務來實現將檔案轉為K,V對的方式
2) Mapper -> Reducer階段
這一階段叫做shuffle(洗牌)階段,從Mapper出來的資料是無序的K,V對,那到了Reducer階段,就變成了有序了.所以我們可以自定義排序規則
3) Reducer -> Output階段
檔案資料經過之前的種種處理,已經變成了有序的資料,這一階段就是將資料寫入檔案
2.資料切片與MapTask並行度決定機制
問題引出
MapTask的並行度決定Map階段的任務處理併發度,進而影響到整個Job的處理速度。
思考:1G的資料,啟動8個MapTask,可以提高叢集的併發處理能力。那麼1K的資料,也啟動8個MapTask,會提高叢集效能嗎?MapTask並行任務是否越多越好呢?哪些因素影響了MapTask並行度?
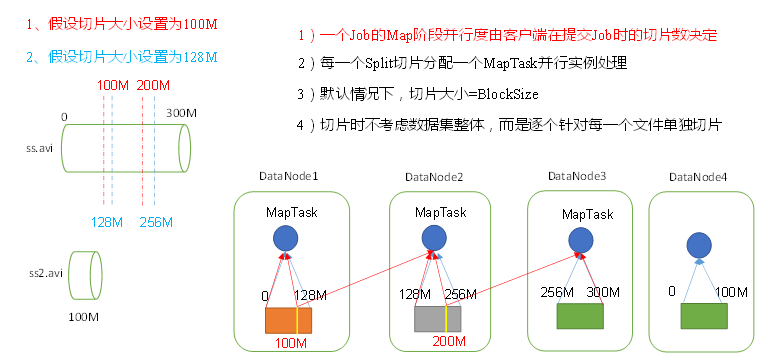
一個300M的資料,按照blocksize=128M進行儲存,在datanode上分別是0-128m,128m-256m,256m-300m
1) 紅線切片,將資料按照100M進行切片,每個MapTask處理同樣大小的100M資料,看似很公平,datanode1的MapTask處理100M資料,剩下的28m傳輸給datanode2的MapTask,datanode2的MapTask處理28m+本地的72m資料,剩下的56m再傳輸給datanode3的MapTask.這樣就增加了84m的網路傳輸資料.為了減少網路傳輸,yarn有一個本地原則,即block儲存在哪個節點上,就在哪個節點上啟動MapTask
2) 藍線切片,切片大小128m=blocksize,每一個datanode啟動的MapTask處理的資料都是128m,雖然看似處理速度比1)的100m慢一些,但是卻節省了緊張的網路傳輸資源
所以約定俗成的,切片大小=blocksize
3.Job提交流程原始碼


確定job的輸出路徑是否有問題



建立jobid和臨時資料夾

生成job的配置資訊
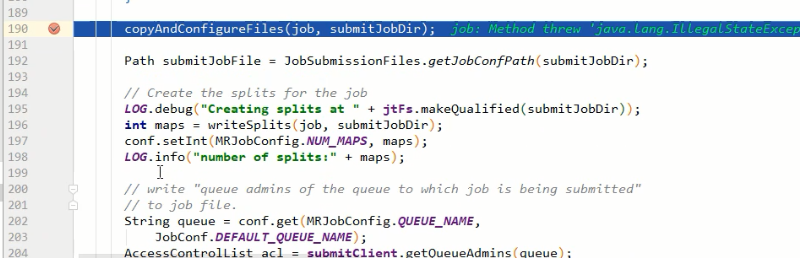

經過這一步寫入後,資料夾裡就有了檔案


最後提交job

整理一下
waitForCompletion() submit(); // 1建立連線 connect();// 1)建立提交Job的代理 new Cluster(getConfiguration()); // (1)判斷是本地yarn還是遠端 initialize(jobTrackAddr, conf); // 2 提交job submitter.submitJobInternal(Job.this, cluster) // 1)建立給叢集提交資料的Stag路徑 Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf); // 2)獲取jobid ,並建立Job路徑 JobID jobId = submitClient.getNewJobID(); // 3)拷貝jar包到叢集 copyAndConfigureFiles(job, submitJobDir); rUploader.uploadFiles(job, jobSubmitDir); // 4)計算切片,生成切片規劃檔案 writeSplits(job, submitJobDir); maps = writeNewSplits(job, jobSubmitDir); input.getSplits(job); // 5)向Stag路徑寫XML配置檔案 writeConf(conf, submitJobFile); conf.writeXml(out); // 6)提交Job,返回提交狀態 status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
3.FileInputFormat切片機制
上一小章的job提交流程裡,生成的臨時資料夾裡面,有一個job.split檔案,說明切片是在job提交之前就切好了,是本地的Driver類做的
那麼就再追一下切片原始碼


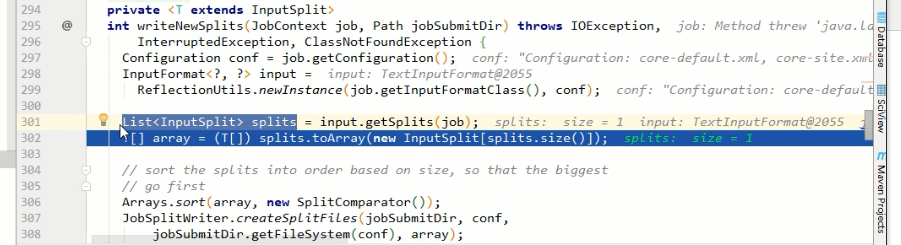
最小值minsize=1,最大值maxsize是int的最大值

遍歷input源的資料夾,對每一個檔案進行切片,先判斷檔案是否可切
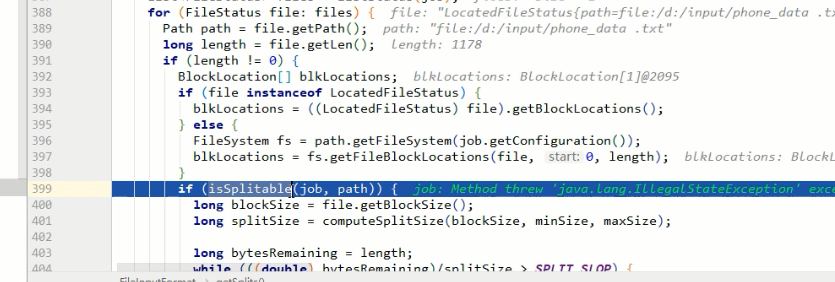
計算切片大小

如,minsize=1,blocksize=32G(33554432),maxsize=9223372036854775807
通過計算,返回的是blocksize.也就是返回的中間值
如果想增加切片大小,那麼就增加minsize的大小到>blocksize,如果想減小切片大小,那麼就減小maxsize大小到<blocksize

bytesRemaining是檔案的大小,根據上面計算到的splitSize來進行切片
404行的SPLIT_SLOP的值是1.1,比的時候是按1.1倍來比,而409行切的時候是按1倍來切
假如blocksize=32M,現在要切一個32.001M的檔案,為了多出來的1k啟動一個MapTask,很浪費不值當~,所以這樣做是為了保證,切出來的片,至少是blocksize大小的10%以上,如果不夠10%,那就交給最後的MapTask哥們來處理好了
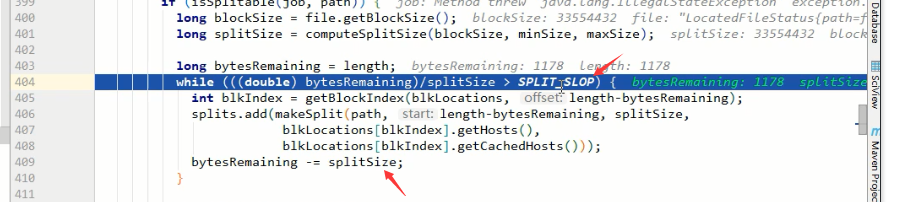
最後將切片放到切片list裡

總結一下
