
Kubernetes權威指南學習----基本概念和術語
Master
是整個Kubernetes的控制節點,是叢集的首腦,Master節點上執行著一下一組關鍵程序:
- Kubernetes API Server(kube-apiserver),提供了HTTP Rest介面的關鍵服務程序,是Kubernetes裡所有資源的增、刪、改、查等操作的唯一入口,也是叢集控制的入口程序
- Kubernetes Controller Manager(kube-controller-manage),Kubernetes裡所有資源物件的自動化控制中心,
- Kubernetes Scheduler(kube-scheduler),負責資源排程(Pod排程)的程序
Node
除了Master結點外的其它機器被稱為Node結點,是叢集的工作結點,可以是一臺物理機或虛擬機器,每個Node結點上都運行了一組關鍵程序:
- kubelet:負責Pod對應的容器的創刪、啟停等任務,同時與Master結點密切協作,實現叢集管理的基本功能
- kube-proxy:實現Kubernetes Service的通訊與負載均衡機制的重要元件
- Docker Engine:負責本機容器的建立和管理工作
注意:已經正確安裝、配置和啟動上述關鍵程序的Node可以動態增加到Kubernetes叢集中,在預設情況下kubelet會想Master註冊自己,一旦Node納入管理範圍,kubelet程序會定時向Master結點彙報自身的情況,如作業系統、Docker版本、機器CPU和記憶體情況,以及運行了哪些Pod等,Master會根據Node的資源使用情況,進行高效均衡的資源排程策略,如果某個Node超過指定時間不上報資訊,會被Master判斷為“失聯”,Node被標記為不可用,隨後該幾點上的工作負載會轉移到其他節點上。
kubectl get nodes可以檢視叢集結點數

kubectl describe node 節點名可以檢視結點詳細資訊
[[email protected] Kubernetes]# kubectl get nodes NAME STATUS AGE 127.0.0.1 Ready 4d [[email protected] Kubernetes]# kubectl describe node 127.0.0.1 Name: 127.0.0.1 Role: Labels: beta.kubernetes.io/arch=amd64 beta.kubernetes.io/os=linux kubernetes.io/hostname=127.0.0.1 Taints: <none> CreationTimestamp: Thu, 29 Nov 2018 05:34:09 -0500 Phase: Conditions: Type Status LastHeartbeatTime LastTransitionTime Reason Message ---- ------ ----------------- ------------------ ------ ------- OutOfDisk False Tue, 04 Dec 2018 03:01:30 -0500 Thu, 29 Nov 2018 05:34:09 -0500 KubeletHasSufficientDisk kubelet has sufficient disk space available MemoryPressure False Tue, 04 Dec 2018 03:01:30 -0500 Thu, 29 Nov 2018 05:34:09 -0500 KubeletHasSufficientMemory kubelet has sufficient memory available DiskPressure False Tue, 04 Dec 2018 03:01:30 -0500 Thu, 29 Nov 2018 05:34:09 -0500 KubeletHasNoDiskPressure kubelet has no disk pressure Ready True Tue, 04 Dec 2018 03:01:30 -0500 Fri, 30 Nov 2018 01:31:48 -0500 KubeletReady kubelet is posting ready status Addresses: 127.0.0.1,127.0.0.1,127.0.0.1 Capacity: alpha.kubernetes.io/nvidia-gpu: 0 cpu: 1 memory: 1865284Ki pods: 110 Allocatable: alpha.kubernetes.io/nvidia-gpu: 0 cpu: 1 memory: 1865284Ki pods: 110 System Info: Machine ID: e0cf5490988c4a65acc364c5e1f70ae1 System UUID: 45F64D56-A209-D65C-6D99-6AF0C29DF941 Boot ID: 4333a69d-1e09-4a1f-b75b-9bfbe0759fcb Kernel Version: 3.10.0-862.el7.x86_64 OS Image: CentOS Linux 7 (Core) Operating System: linux Architecture: amd64 Container Runtime Version: docker://1.13.1 Kubelet Version: v1.5.2 Kube-Proxy Version: v1.5.2 ExternalID: 127.0.0.1 Non-terminated Pods: (1 in total) Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits --------- ---- ------------ ---------- --------------- ------------- default mysql-pkxgr 0 (0%) 0 (0%) 0 (0%) 0 (0%) Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted. CPU Requests CPU Limits Memory Requests Memory Limits ------------ ---------- --------------- ------------- 0 (0%) 0 (0%) 0 (0%) 0 (0%) Events: FirstSeen LastSeen Count From SubObjectPath Type Reason Message --------- -------- ----- ---- ------------- -------- ------ ------- 46m 46m 1 {kubelet 127.0.0.1} Normal Starting Starting kubelet. 46m 46m 1 {kubelet 127.0.0.1} Warning ImageGCFailed unable to find data for container / 46m 46m 1 {kubelet 127.0.0.1} Normal NodeHasSufficientDisk Node 127.0.0.1 status is now: NodeHasSufficientDisk 46m 46m 1 {kubelet 127.0.0.1} Normal NodeHasSufficientMemoryNode 127.0.0.1 status is now: NodeHasSufficientMemory 46m 46m 1 {kubelet 127.0.0.1} Normal NodeHasNoDiskPressure Node 127.0.0.1 status is now: NodeHasNoDiskPressure 46m 46m 1 {kubelet 127.0.0.1} Warning Rebooted Node 127.0.0.1 has been rebooted, boot id: 4333a69d-1e09-4a1f-b75b-9bfbe0759fcb 46m 45m 2 {kubelet 127.0.0.1} Warning MissingClusterDNS kubelet does not have ClusterDNS IP configured and cannot create Pod using "ClusterFirst" policy. pod: "mysql-pkxgr_default(af042e71-f469-11e8-8738-000c299df941)". Falling back to DNSDefault policy.


Pod
pod的組成與容器的關係

每個Pod都有一個特殊容器稱為根容器的Pause容器,以及一個或多個container。
Pod裡的多個容器共享Pause容器的IP,共享Pause容器掛載的Volume,將密切關聯的業務捆綁起來,可以很好解決檔案共享問題,例如,php的web伺服器中的nginx和php
Pod的兩種型別:普通Pod與靜態Pod
- 普通Pod:普通Pod一旦被建立,就會被放入到etcd中儲存,所有會被Kubernetes Master排程到具體的Node上進行繫結,隨後被該Node上的kubelet進行例項化成一組相關的Docker容器,一旦該node或pod宕機或停止了,該Pod會被重新排程到其他結點上
- 靜態Pod:該Pod不會被放在Kubernetes的etcd儲存裡,而是放在某個具體的Node的檔案裡,並且只在該Node上啟動執行,如果該Node宕機了,該Pod也不會被重新排程。
Kubernetes裡的所有資源物件都可以採用yml或者JSON格式的檔案來定義或描述
例如myweb這個Pod的資原始檔的定義:



對Pod進行資源限額:


Label
Label是Kubernetes系統中的核心概念之一,一個Label是一個key=value的鍵值對,其中key與value由使用者指定。Label可以附加到各種資源物件上,例如Node、Pod、Service、RC等,一個資源物件可以定義任意數量的Label,同一個Label也可以被新增到任意數量的資源物件上去。
LabelSelector
Label Selector與SQL中的where查詢條件類似,例如name=redis-slave這個Label Selector作用於Pod是,可以被類比為select * from pod where pod’s name = ‘redis-slave’。當前有兩種Label Selector的表示式:基於等式和基於集合,例如:name = redis-slave,env != production;name in (redis-master,redis-slave),name not in (php-frontend)
可以指定多個Label Selector表示式進行組合,多個表示式之間用“ , ”間隔。

使用場景:
- kube-controller程序通過資源物件RC上的Label Selector來篩選要監控的Pod副本的數量
- kube-proxy程序通過Service的Label Selector來選擇對應的Pod,自動建立每個Service到對應Pod的請求轉發路由,實現負載均衡機制
- 通過某些Node定義特定的Label,並且在Pod定義檔案使用NodeSelector這種標籤排程策略,kube-scheduler程序可以實現Pod“定向排程”的特性
Replication Controller(RC)
Kubernetes系統的核心概念之一,定義一個期望場景,即宣告某種Pod的副本數量在任意時刻都符合某個預期值。所以RC的定義包含如下幾個部分:
- POD期待的副本數
- 用於篩選目標Pod的Label Selector
- 當Pod的副本數量小於預期數量的時候,用於建立Pod的Pod模板

在執行時,可以通過修改RC的副本數量來實現Pod的動態縮放:
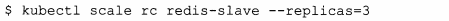
下一代RC–Replica Set*與RC的唯一區別是Replica Set支援基於集合的Label Selector,而RC只支援基於等式的Label Selector
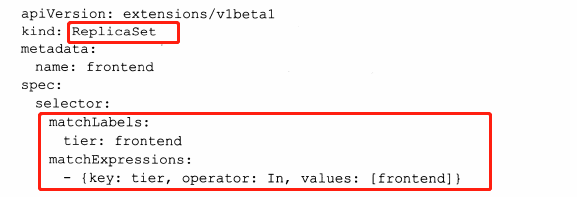
通常Replica Set很少單獨使用,它主要被Deployment這個更高層的資源物件使用,從而形成一整套Pod建立、刪除、更新的編排機制。
RC的一些特性與作用:

Deployment
Kubernetes 1.2引入的新概念,可以看成RC的升級版,相對於RC的最大升級是我們可以隨時知道當前Pod“部署”的進度。
典型的使用場景:
- 建立一個Deployment物件來生成對應的Replica Set並完成Pod副本的建立過程
- 檢查Deployment的狀態來看部署是否完成
- 更新Deployment以建立新的Pod(映象升級)
- 如果當前Deployment不穩定,回滾到一個早先的deployment版本
- 掛起或者回復一個Deployment
Deployment的yaml檔案例項:



Horizontal Pod Autoscaler(HPA)
根據叢集的負載情況實現Pod的自動擴容和縮容
HPA可以有以下兩種方式作為Pod負載的度量指標:
- CPUUtilizationPercentage,是一個算術平均值,即目標Pod所有副本自身的CPU利用率的平均值。
- 應用程式自定義的度量指標,比如服務在每秒內的響應請求數。

Service
Kubernetes裡最核心的資源物件之一,每個Service其實就是一個“微服務”。


每個Service都被分配一個全域性唯一的虛擬IP地址(Cluster IP),與Pod不同的是,在Service的整個生命週期裡,它的Cluster IP不會發生變化,而Pod的Endpoint在Pod銷燬和重新建立時會發生變化。
Service的yaml檔案舉例:

建立Service

檢視tomcat-service的Endpoint

檢視Service被分配的Cluster IP

Service的多埠問題,很多服務都存在多個埠,Kubernetes Service支援多個Endpoint,在存在多個Endpoint的情況下,要求每個Endpoint定義一個名字來區分。
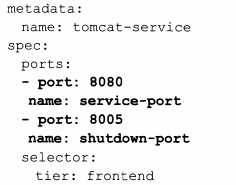
Kubernetes的服務發現機制
最早的Kubernetes採用Linux的環境變數的方式解決服務發現問題,由於Service有唯一的名字和Cluster IP,所以為每個Service生成一些對應的Linux環境變數,在Pod的容器啟動時,自動注入這些環境變數,以tomact-service舉例:

後來Kubernetes通過Add-On增值包的方式引入DNS系統,把服務名作為DNS域名,通過域名解析來實現服務發現。
外部系統訪問Service
Kubernetes的三種IP:

- Node IP是每個結點的物理網絡卡的IP地址,是一個真實的物理網路,所有屬於這個網路的伺服器之間都能通過這個網路直接通訊。叢集之外的結點只能通過該IP訪問叢集之內的結點
- Pod IP是每個Pod的IP地址,是docker0網橋的IP地址段分配的一個虛擬地址,Kubernetes要求不同Node上的Pod能夠彼此通訊,所以叢集內的一個Pod裡的容器訪問另一個個Pod的容器時使用這個地址
- Cluster IP,是一個虛擬IP,

通過上面可知Cluster IP是一個虛擬IP,無法從叢集外部直接訪問,採用NodePort可以解決這個問題。

NodePort的實現方式是在Kubernetes叢集裡的每個Node上為需要外部訪問的Service開啟一個對應的TCP監聽埠,外部系統只需要用任意一個Node的IP地址+具體的NodePort埠號即可訪問此服務。

Volume(儲存卷)
Kubernetes中的Volume被一個Pod中的多個容器掛載,與Pod的生命週期相同,與容器的生命週期無關。
Volume的使用,大多數情況下,我面先宣告一個Volume,然後在容器裡面應用該Volume。

Kubernetes中的Volume的型別:
1.emptyDir:Pod分配到Node時建立該卷,初始內容為空,無須指定宿主機上對應的目錄檔案,因為Kubernetes會自動分配一個目錄,當Pod從Node上移除時,emptyDir中的資料也會被永久刪除。目前使用者無法控制emptyDir使用的介質種類,emptyDir的一些用途:

2.hostPath:在Pod上掛載宿主機上的檔案或目錄,通常用於以下幾個方面

3.gcePersistentDisk:使用谷歌公有云提供的永久磁碟存放Volume的資料,PD上的內容會永久儲存。


4.awsElasticBlockStore:與GCE類似,使用亞馬遜公有云
5.NFS:使用NFS網路檔案系統提供的共享目錄儲存資料,我們需要在系統中部署一個NFS Server,定義NFS型別的Volume:

Persistent Volume


Namespace(名稱空間)
是Kubernetes中的一個非常重要的概念,用於實現多租戶的資源隔離。
Kubernetes叢集啟動後會建立一個名為“ default ”的Namespace,可以使用kubectl檢視

接下來如果不特別指明Namespace,則使用者建立的Pod、RC、Service都會被系統建立到default的Namespace中。
定義Namespace的yaml檔案例項:

建立資源時指定Namespace

此時kubectl get命令無法查到該pod,因為kubectl get預設查詢“ default ”名稱空間的資源,所以需要加上–namespace引數


Annotation(註解)
Annotation與Label類似,也是用key/value鍵值對形式定義,不同的是,Label具有嚴格的命名規則並且勇於Label Selector,Annotation則是使用者任意定義的“附加”資訊,以便外部工具進行查詢。
