
Hadoop分別啟動NN DN SN等服務
查詢當前解壓檔案之後,hadoop2.7.3的預設配置檔案, 四個檔案的.xml,
1.core-default.xml common\hadoop-common-2.7.3.jar 2.hdfs-default.xml hdfs\hadoop-hdfs-2.7.3 3.mapred-default.xml mapreduce\hadoop-hdfs-2.7.3.jar4.yarn-default.xml yarn\hadoop-yarn-common-2.7.3.jar

三種啟動方式介紹
方式一:逐一啟動(實際生產環境中的啟動方式)
hadoop-daemon.sh start|stop namenode|datanode| journalnode
yarn-daemon.sh start |stop resourcemanager|nodemanager
方式二:分開啟動
start-dfs.sh
start-yarn.sh
方式三:一起啟動
start-all.sh
start-all.sh指令碼:
說明:start-all.sh實際上是呼叫sbin/start-dfs.sh指令碼和sbin/start-yarn.sh指令碼
指令碼解讀
start-dfs.sh指令碼:
(1) 通過命令bin/hdfs getconf –namenodes檢視namenode在那些節點上
(2) 通過ssh方式登入到遠端主機,啟動hadoop-deamons.sh指令碼
(3) hadoop-deamon.sh指令碼啟動slaves.sh指令碼
(4) slaves.sh指令碼啟動hadoop-deamon.sh指令碼,再逐一啟動
注意:為什麼要使用SSH??
當執行start-dfs.sh指令碼時,會呼叫slaves.sh指令碼,通過ssh協議無密碼登陸到其他節點去啟動程序。三種啟動方式的關係
start-all.sh :其實呼叫start-dfs.sh和start-yarn.sh
start-dfs.sh:呼叫hadoop-deamon.sh start-yarn.sh:呼叫yarn-deamon.sh
如下圖:
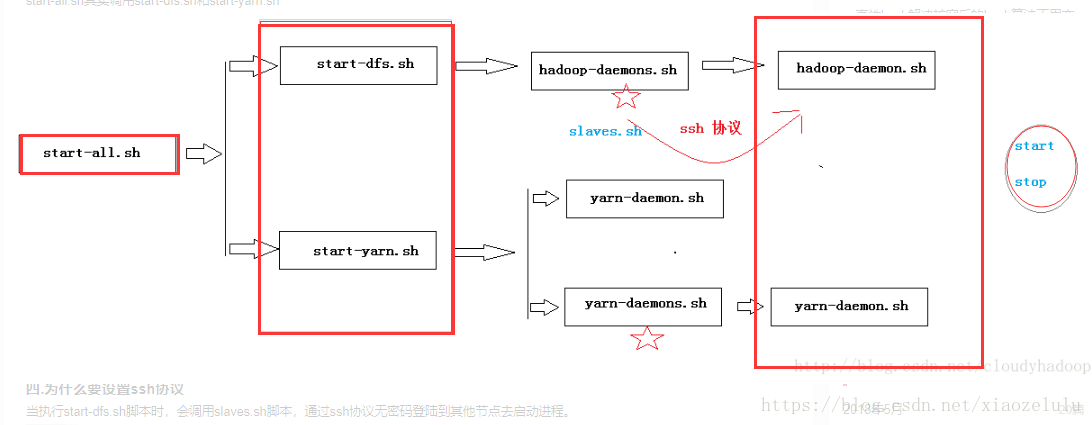
hadoop-daemon.sh 和Hadoop-daemons.sh 的區別
Hadoop-daemon.sh:用於啟動當前節點的程序
例如Hadoop-daemon.sh start namenode 用於啟動當前的名稱節點Hadoop-daemons.sh:用於啟動所有節點的程序
例如:Hadoop-daemons.sh start datanode 用於啟動所有節點的資料節點有時候我們可能/hyxy/hadoop/etc/hadoop資料夾會宕機,找不到,一般我們會備份這個檔案,這裡備份為hadoop_pseudo ,之後啟動服務(或關閉),會提示:找不到路徑,所以,這個時候我們就可以:分別啟動服務程序,達到目的。
分別動守護程序--啟動順序不重要
假如:mv ~/soft/hadoop/etc/hadoop hadoop_pseudo 提示: 可能會出現檔案被更名,啟動服務找不到路徑,我們可以單獨去啟動某個服務啟動的路徑。1) 直接輸入
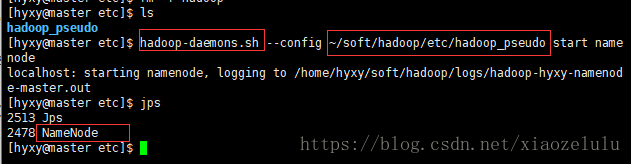
etc$>1.namenode程序hadoop-daemons.sh --config ~/soft/hadoop/etc/hadoop_pseudo start namenode守護程序 配置項 傳這個配置路徑 可能/etc/hadoop更名為hadoop_pseudo,找不到路徑,我們可以配置後來的路徑,去開啟服務。2.啟動datanode程序hadoop-daemons.sh --config ~/soft/hadoop/etc/hadoop_pseudo start datanode3.啟動secondarynamenode程序hadoop-daemons.sh --config ~/soft/hadoop/etc/hadoop_pseudo start secondarynamenode
- [[email protected] etc]$ hadoop-daemons.sh --config ~/soft/hadoop/etc/hadoop_pseudo start namenode
- localhost: starting namenode, logging to /home/hyxy/soft/hadoop/logs/hadoop-hyxy-namenode-master.out
- [[email protected] etc]$ jps
- 2513 Jps
- 2478 NameNode
注:殺掉某個程序:kill 2478,如下,殺掉namenode程序了。

2)可以不指定路徑,在命令列上export 或者在.bash_profile
執行下列:~/soft/hadoop/etc/hadoop_pseudo
etc$> hadoop-daemons.sh start secondarynamenode會報錯,解決: etc$> export HADOOP_CONF_DIR=~/soft/hadoop/etc/hadoop_pseudo 只在本次頁面有用 etc$> hadoop-daemons.sh start secondarynamenode
- [[email protected] etc]$ export HADOOP_CONF_DIR=~/soft/hadoop/etc/hadoop_pseudo
- [[email protected] etc]$ hadoop-daemons.sh start secondarynamenode
- localhost: starting secondarynamenode, logging to /home/hyxy/soft/hadoop/logs/hadoop-hyxy-secondarynamenode-master.out
- [[email protected] etc]$ jps
- 2983 Jps
- 2942 SecondaryNameNode
 命令:hadoop-daemon.sh
命令:hadoop-daemon.sh
etc$> hadoop-daemon.sh
Usage: hadoop-daemon.sh [--config <conf-dir>] [--hosts hostlistfile] [--script script] (start|stop) <hadoop-command> <args...> 前提【:三者之一均可: ①/etc/hadoop檔案沒有改名, ②/etc/hadoop_pseudo,改名了, 在.bash_profile配置了HADOOP_CONF_DIR=③改名後,建立軟連結:ln -s hadoop_pseudo hadoop 到時候找路徑,還是原先那樣的路徑,只不過本質變成軟連線了。】 hadoop-daemon.sh start secondarynamenode hadoop-daemon.sh start namenode hadoop-daemons.sh start datanode 要加s,datanode是複數 hadoop預設查詢{HADOOP_HOME}/etc/hadoop sbin$> hadoop-daemons.sh start namenode 直接啟動也可以
- ~/soft/hadoop/etc/hadoop_pseudo
- 的絕對路徑了。 (直接export也行)
命令: hadoop-daemons.sh
Usage: hadoop-daemons.sh [--config confdir] [--hosts hostlistfile] [start|stop] command args... 配置目錄 筆記: Hadoop的瓶頸是:物理儲存!!而絕非網路、核心 CPU、記憶體; last connect:最後連線的時間; datanode:宕機是常態,不是一種異常; 偽分佈是完全分佈的一種特例;關於軟連結小總結:
最就算我們/etc/hadoop檔案不見,我們還有備份的hadoop_pseudo,我們建立一個軟連結: ln -s hadoop_pseudo hadoop指向原先失去的hadoop,同樣對我們開啟服務沒有影響,不用指定--config的路徑了。
也許在以後,我們要用的配置項不一定是原先的/etc/hadoop檔案,或許是hadoop_pseuso等其他配置文 件,這下,可以利用軟連結去指向我們想配置的的哪個配置檔案。只需要改下軟連結,不用再麻煩修改其他配置檔案或環境變數引數了。