
我的Python成長之路---Day7-字元編碼和檔案處理part1
儲備知識點:
1. 計算機系統分為三層: 應用程式 作業系統 計算機硬體
2. 執行python程式的三個步驟 1. 先啟動python直譯器 2. 再將python檔案當作普通的文字檔案讀入記憶體 3. 解釋執行讀入記憶體的程式碼,開始識別語法
一、字元編碼
1. 什麼是字元編碼 字元編碼表: 人類的字元<------------>計算機的語言(二進位制數字)
字元編碼說白了就是需要將人類的組合計算機語言一一對應起來(以ASCII碼為例,26個英文字母和符號都和唯一的二進位制數相對應),比如說英語的國家,單詞都是由26個英文字母組成的,定義了26個英文字母對應的字元編碼之後就可以組合出來所有的英文單詞了,同時再將要用的符號和特殊符號也定義出來,這樣就可以組合出來可以正常使用的單詞和句子以及文章了
1Bytes=8bit 1B=8b 1位元組等於8個二進位制位 B代表bytes b代表bit
字元編碼表常用的幾種形式:
ASCII碼:只能識別英文字元,
1英文字元=8bit 用8個二進位制bit(位元位)位表示一個英文字元
GBK:能識別漢字與英文,1漢字=2Bytes=16bit,1英文字元=1Bytes=8bit Shift_JIS 日文的字元編碼 Euc-kr 韓文的字元編碼
unicode:能夠識別萬國字元,1字元=2Bytes=16bit 兩大特點: 1. 能夠相容萬國字元 2. 與各個國家的字元編碼都有對映關係 utf-8:是unicode的轉換格式,1個英文字元=1Bytes 1漢字=3Bytes
重點理論: 1 編碼與解碼: 編碼: (輸入的)字元----編碼--->unicode的二進位制-------編碼----->GBK的二進位制 解碼: GBK的二進位制-----解碼-->unicode的二進位制----解碼---->字元
2. 解決亂碼問題的核心法則: 字元用什麼編碼格式編碼的,就應該用什麼編碼格式進行解碼
3. python直譯器預設的字元編碼 python2:ASCII python3:UTF-8
通過檔案頭可以修改python直譯器預設使用的字元編碼 在檔案首行寫:#coding:檔案當初存的時候用的字元編碼
# coding:utf-8
# 這是一行列印資訊
print('hello')針對python2直譯器中定義字串應該: x=u"上" 這樣x就變成了unicode的型別 對於python3直譯器中,即便是x="上"不加u字首也是存成unicode
在python3中 x='上' # '上'存成了uncidoe
unicode--------encode----------->gbk encode是一個編碼操作 res=x.encode('gbk') #res是gbk格式的二進位制,稱之為bytes型別
gbk(bytes型別)-------decode---------->unicode y=res.decode('gbk') #y就是unicode
關於字元編碼的操作:
1. 編寫python檔案,首行應該加檔案頭:#coding:檔案存時用的編碼 2. 用python2寫程式,定義字串應該加字首u,如x=u'上' 3. python3中的字串都是unicode編碼的,python3的字串encode之後可以得到bytes型別
2. 為何字元要編碼 人類與計算機打交道用的都是人類的字元,而計算機無法識別人類的字元,只能識別 二進位制,所以必須將人類的字元編碼成計算機能識別的二進位制數字.
3. 如何用字元編碼
在文字編輯器中,會有儲存時使用的檔案編碼方式,在讀取檔案的時候,為了避免讀出來的檔案出現亂碼的現象,要使用和檔案儲存時一致的字元編碼方式,在pycharm中,pycharm會自動在檔案讀取的時候和檔案讀取的時候使用的字元編碼保持一致,也可以自己進行改.要注意只有在文字還未開始編輯的時候才可以進行切換
二、檔案處理
1 什麼是檔案 檔案是作業系統提供給使用者/應用程式的一種虛擬單位,該虛擬單位直接對映的是硬碟空間,如圖所示
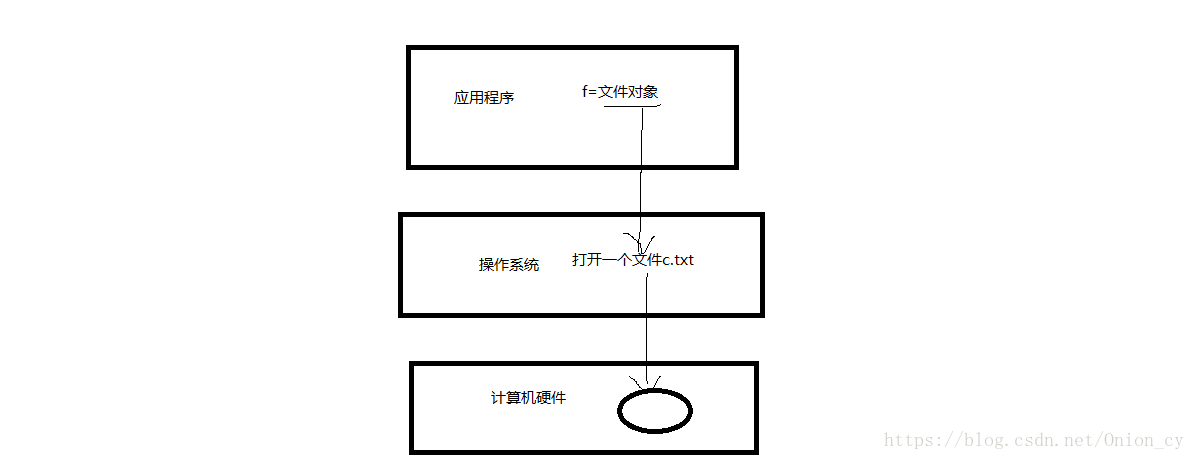
2 為何要處理檔案 使用者/應用程式直接操作檔案(讀/寫)就被作業系統轉換成具體的硬碟操作,從而實現 使用者/應用程式將記憶體中的資料永久儲存到硬碟中
3 如何用檔案
檔案處理的三個步驟(開啟檔案=====進行/讀取======關閉檔案)
f=open(r'c.txt',mode='r',encoding='utf-8') # 檔案物件(應用程式的記憶體資源 )------》作業系統開啟的檔案(作業系統的記憶體資源) # print(f) 檔案前面加r (rawstreet) 表示取消轉譯,在python中/+字母會有特殊意義,因為在這裡可 能會輸入檔案路徑,加r之後表示無論在後邊的字串中輸入多少個字串都不會進行轉譯. data=f.read() f.close() # 向作業系統傳送訊號,讓作業系統關閉開啟的檔案,從而回收作業系統的資源
上下文管理with open(r'c.txt',mode='r',encoding='utf-8') as f,open(r'b.txt',mode='r',encoding='utf-8') as f1:
使用with開頭的取值操作,取出值之後把值賦給as後邊的變數,在檔案進行完讀取操作之後,檔案會自動儲存並關閉.中間可以使用逗號隔開進行多個開啟操作
讀寫檔案的操作
檔案的開啟模式:r(預設的) w a
在進行檔案的讀取時,光標出現在文字文件的首行的開頭,來執行讀取命令.在只執行一次讀取後就關閉檔案再開啟時游標還是會在首行開頭.但是在開啟檔案未關閉時,游標會停留在上次讀取操作完畢後的位置.
模式一:r(也是開啟檔案的預設模式) 操作檔案內容的模式: t(預設的):(t表示對文字內容進行操作)操作檔案內容都是以字串為單位,會自動幫我們解碼,必須指定encoding引數 b: 操作檔案內容都是以Bytes(二進位制)為單位,硬碟中存的時什麼就取出什麼,一定不能指定encoding引數,在encoding引數刪除之後再對檔案進行操作時,預設的編碼方式不再是gbk 總結:t模式只能用於檔案本檔案,而b模式可以用於任意檔案
r模式:只讀模式,在檔案不存在時則報錯,如果檔案存在檔案指標跳到檔案的開頭 with open(r'c.txt',mode='rt',encoding='utf-8') as f: print(f.read()) print(f.readable()) print(f.writable()) f.write('hello') # 這行會進行報錯,因為該文字模式只能讀
data=f.read() print(data,type(data))
with open(r'c.txt',mode='rb') as f: data=f.read() # print(data,type(data)) res=data.decode('utf-8') print(res)
with open(r'c.txt',mode='rt',encoding='utf-8') as f: # line=f.readline() readline,表示對文字檔案只讀取一行 # print(line,end='') # line1=f.readline() # print(line1,end='') # line2 = f.readline() # print(line2,end='')
lines=f.readlines() readlines表示對文字檔案進行多行讀取也就是全部讀取,並輸出為一個列表 print(lines) with open(r'c.txt',mode='rt',encoding='utf-8') as f: line=f.readline() print(line,end='')
迴圈讀檔案內容的方法: with open(r'c.txt',mode='rt',encoding='utf-8') as f: for line in f: print(line,end='')