
R語言分組計算平均數、SE、SD等等
阿新 • • 發佈:2018-12-10
1提出問題
資料處理時經常遇到這麼一個問題:自變數(處理)分組group1,2,3.變數(x1.x2,x3,x4,x5…)一系列的變數。我只想計算group1、group3分組的情況下的x2,x4,x5的mean等等。
舉例解決辦法
R語言實戰二里面p131-136都是在講基礎統計,有興趣自己去敲一遍。
這裡說下一自我感覺用的隨意方便的其中一種可以很好的解決分組計算的問題。
舉例
1,像這樣的資料排列有plot,Site,site,V,N,D,R,而因變數TCMI、TCM6,。。。也可以很多。
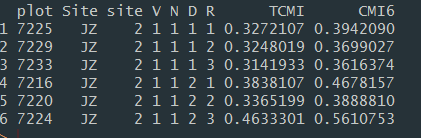
整個cmi資料庫有108*9,
#資料一定要檢查型別(factor、num、int)

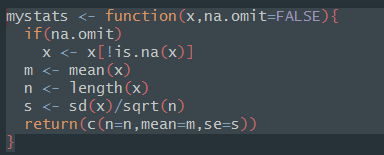
2,寫個要計算的方程(實戰p132有詳解)
此處copy
(只要確保自己的資料沒有空值,這個n沒什麼用,可以不輸出)
3,引用包doby(名字起得好 ,“逗~”)
詳細公式實戰p135 7.1.4有詳解
summaryBy(formula,data,FUN=function)
##formula格式x1+x2+x3...~group1+group2+....(formula挺有意思,後續寫方差分析時再補充)
##data 資料data
##FUN就是計算方程
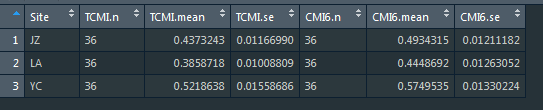
4,運算結果
#注意因變數+自變數

 5,新增自變數V,新增重複R,如何?
5,新增自變數V,新增重複R,如何?

