
Redis開發與運維讀書筆記-第十一章-快取設計
快取能夠有效地加速應用的讀寫速度,同時也可以降低後端負載,對日常應用的開發至關重要。但是將快取加入應用架構後也會帶來一些問題.
1 快取的收益和成本
收益如下:·加速讀寫:因為快取通常都是全記憶體的(例如Redis、Memcache),而儲存層通常讀寫效能不夠強悍(例如MySQL),通過快取的使用可以有效地加速讀寫,優化使用者體驗。·降低後端負載:幫助後端減少訪問量和複雜計算(例如很複雜的SQL語句),在很大程度降低了後端的負載。成本如下: ·資料不一致性:快取層和儲存層的資料存在著一定時間視窗的不一致性,時間視窗跟更新策略有關。 ·程式碼維護成本:加入快取後,需要同時處理快取層和儲存層的邏輯,增大了開發者維護程式碼的成本。·運維成本:
2 快取更新策略
快取中的資料通常都是有生命週期的,需要在指定時間後被刪除或更新,這樣可以保證快取空間在一個可控的範圍。但是快取中的資料會和資料來源中的真實資料有一段時間視窗的不一致,需要利用某些策略進行更新。下 面將分別從使用場景、一致性、開發人員開發/維護成本三個方面介紹三種快取的更新策略。
1.LRU/LFU/FIFO演算法剔除使用場景:剔除演算法通常用於快取使用量超過了預設的最大值時候,如何對現有的資料進行剔除。例如Redis使用maxmemory-policy這個配置作為記憶體最大值後對於資料的剔除策略。一致性:要清理哪些資料是由具體演算法決定,開發人員只能決定使用哪種演算法,所以資料的一致性是最差的。維護成本:演算法不需要開發人員自己來實現,通常只需要配置最大 maxmemory和對應的策略即可。開發人員只需要知道每種演算法的含義,選擇適合自己的演算法即可。
2.超時剔除使用場景:超時剔除通過給快取資料設定過期時間,讓其在過期時間後自動刪除,例如Redis提供的expire命令。如果業務可以容忍一段時間內,快取層資料和儲存層資料不一致,那麼可以為其設定過期時間。在資料過期後,再從真實資料來源獲取資料,重新放到快取並設定過期時間。例如一個視訊的描述資訊,可以容忍幾分鐘內資料不一致,但是涉及交易方面的業務,後果可想而知。一致性:
3.主動更新使用場景:應用方對於資料的一致性要求高,需要在真實資料更新後,立即更新快取資料。例如可以利用訊息系統或者其他方式通知快取更新。一致性:一致性最高,但如果主動更新發生了問題,那麼這條資料很可能很長時間不會更新,所以建議結合超時剔除一起使用效果會更好。維護成本:維護成本會比較高,開發者需要自己來完成更新,並保證更新操作的正確性。
下表給出了快取的三種常見更新策略的對比。
| 策略 | 一致性 | 維護成本 |
| LRU/LFU/FIFO演算法剔除 | 最差 | 低 |
| 超時剔除 | 較差 | 較低 |
| 主動更新 | 強 | 高 |
4.最佳實踐 ·低一致性業務建議配置最大記憶體和淘汰策略的方式使用。 ·高一致性業務可以結合使用超時剔除和主動更新,這樣即使主動更新出了問題,也能保證資料過期時間後刪除髒資料。
3 快取粒度控制
下圖是很多專案關於快取比較常用的選型,快取層選用Redis,儲存層選用MySQL。

例如現在需要將MySQL的使用者資訊使用Redis快取,可以執行如下操作: 從MySQL獲取使用者資訊:
select * from user where id={id}將使用者資訊快取到Redis中:
set user:{id} 'select * from user where id={id}'
假設使用者表有100個列,需要快取到什麼維度呢? ·快取全部列:
set user:{id} 'select * from user where id={id}'
·快取部分重要列:
set user:{id} 'select {importantColumn1}, {important Column2} ... {importantColumnN} from user where id={id}'
上述這個問題就是快取粒度問題,究竟是快取全部屬性還是隻快取部分重要屬性呢?下面將從通用性、空間佔用、程式碼維護三個角度進行說明.
通用性。快取全部資料比部分資料更加通用,但從實際經驗看,很長時間內應用只需要幾個重要的屬性。空間佔用。快取全部資料要比部分資料佔用更多的空間,可能存在以下問題: ·全部資料會造成記憶體的浪費。 ·全部資料可能每次傳輸產生的網路流量會比較大,耗時相對較大,在極端情況下會阻塞網路。 ·全部資料的序列化和反序列化的CPU開銷更大。程式碼維護。全部資料的優勢更加明顯,而部分資料一旦要加新欄位需要修改業務程式碼,而且修改後通常還需要重新整理快取資料
下表給出快取全部資料和部分資料在通用性、空間佔用、程式碼維護上的對比,開發人員可以酌情選擇。
| 資料型別 | 通用性 | 空間佔用(記憶體空間+網路頻寬) | 程式碼維護 |
| 全部資料 | 高 | 大 | 簡單 |
| 部分資料 | 低 | 小 | 較為複雜 |
快取粒度問題是一個容易被忽視的問題,如果使用不當,可能會造成很多無用空間的浪費,網路頻寬的浪費,程式碼通用性較差等情況,需要綜合資料通用性、空間佔用比、程式碼維護性三點進行取捨。
4 穿透優化
快取穿透是指查詢一個根本不存在的資料,快取層和儲存層都不會命中,通常出於容錯的考慮,如果從儲存層查不到資料則不寫入快取層,整個過程分為如下3步: 1)快取層不命中。 2)儲存層不命中,不將空結果寫回快取。 3)返回空結果。
快取穿透將導致不存在的資料每次請求都要到儲存層去查詢,失去了快取保護後端儲存的意義。快取穿透問題可能會使後端儲存負載加大,由於很多後端儲存不具備高併發性,甚至可能造成後端儲存宕掉。通常可以在程式中分別統計總呼叫數、快取層命中數、儲存層命中數,如果發現大量儲存層空命中,可能就是出現了快取穿透問題。造成快取穿透的基本原因有兩個。第一,自身業務程式碼或者資料出現問題,第二,一些惡意攻擊、爬蟲等造成大量空命中。下面我們來看一下如何解決快取穿透問題。
1.快取空物件
如下圖所示,當第2步儲存層不命中後,仍然將空物件保留到快取層中,之後再訪問這個資料將會從快取中獲取,這樣就保護了後端資料來源。
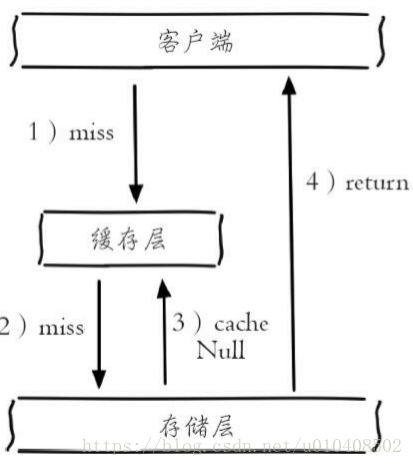
快取空物件會有兩個問題:第一,空值做了快取,意味著快取層中存了更多的鍵,需要更多的記憶體空間(如果是攻擊,問題更嚴重),比較有效的方法是針對這類資料設定一個較短的過期時間,讓其自動剔除。第二,快取層和儲存層的資料會有一段時間視窗的不一致,可能會對業務有一定影響。 例如過期時間設定為5分鐘,如果此時儲存層添加了這個資料,那此段時間就會出現快取層和儲存層資料的不一致,此時可以利用訊息系統或者其他方式清除掉快取層中的空物件。 下面給出快取空物件的實現程式碼:
String get(String key) {
// 從快取中獲取資料
String cacheValue = cache.get(key);
// 快取為空
if (StringUtils.isBlank(cacheValue)) {
// 從儲存中獲取
String storageValue = storage.get(key);
cache.set(key, storageValue);
// 如果儲存資料為空,需要設定一個過期時間(300秒)
if (storageValue == null) {
cache.expire(key, 60 * 5);
}
return storageValue;
} else {
// 快取非空
return cacheValue;
}
}
2.布隆過濾器攔截 如下圖所示,在訪問快取層和儲存層之前,將存在的key用布隆過濾 器提前儲存起來,做第一層攔截。例如:一個推薦系統有4億個使用者id,每個小時演算法工程師會根據每個使用者之前歷史行為計算出推薦資料放到儲存層中,但是最新的使用者由於沒有歷史行為,就會發生快取穿透的行為,為此可 以將所有推薦資料的使用者做成布隆過濾器。如果布隆過濾器認為該使用者id不存在,那麼就不會訪問儲存層,在一定程度保護了儲存層。
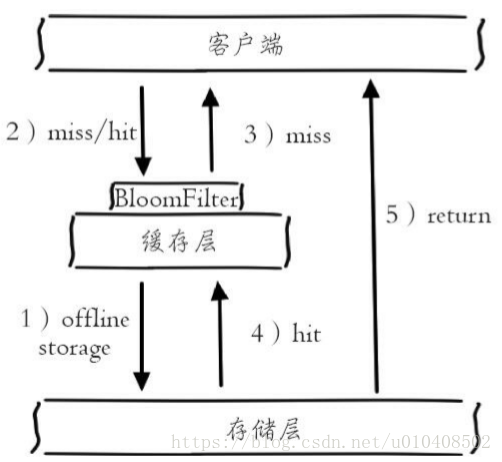
有關布隆過濾器的相關知識,可以參考:https://en.wikipedia.org/wiki/Bloom_filter可以利用Redis的Bitmaps實現布 隆過濾器,GitHub上已經開源了類似的方案,讀者可以進行參 考:https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter。這種方法適用於資料命中不高、資料相對固定、實時性低(通常是資料集較大)的應用場景,程式碼維護較為複雜,但是快取空間佔用少。
3.兩種方案對比
前面介紹了快取穿透問題的兩種解決方法(實際上這個問題是一個開放問題,有很多解決方法),下表從適用場景和維護成本兩個方面對兩種方案進行分析。
| 解決快取穿透 | 適用場景 | 維護成本 |
| 快取空物件 |
資料命中不高 資料頻繁變化實時性高 |
程式碼維護簡單 需要過多的快取空間 資料不一致 |
| 布隆過濾器 |
資料命中不高 資料相對固定實時性低 |
程式碼維護複雜 快取空間佔用少 |
5 無底洞優化
2010年,Facebook的Memcache節點已經達到了3000個,承載著TB級別的快取資料。但開發和運維人員發現了一個問題,為了滿足業務要求添加了 大量新Memcache節點,但是發現效能不但沒有好轉反而下降了,當時將這 種現象稱為快取的“無底洞”現象。 那麼為什麼會產生這種現象呢,通常來說新增節點使得Memcache叢集效能應該更強了,但事實並非如此。鍵值資料庫由於通常採用雜湊函式將 key對映到各個節點上,造成key的分佈與業務無關,但是由於資料量和訪問量的持續增長,造成需要新增大量節點做水平擴容,導致鍵值分佈到更多的 節點上,所以無論是Memcache還是Redis的分散式,批量操作通常需要從不同節點上獲取,相比於單機批量操作只涉及一次網路操作,分散式批量操作會涉及多次網路時間。
無底洞問題分析: ·客戶端一次批量操作會涉及多次網路操作,也就意味著批量操作會隨著節點的增多,耗時會不斷增大。 ·網路連線數變多,對節點的效能也有一定影響。
用一句通俗的話總結就是,更多的節點不代表更高的效能,所謂“無底 洞”就是說投入越多不一定產出越多。但是分散式又是不可以避免的,因為訪問量和資料量越來越大,一個節點根本抗不住,所以如何高效地在分散式快取中批量操作是一個難點。 下面介紹如何在分散式條件下優化批量操作。在介紹具體的方法之前, 我們來看一下常見的IO優化思路: ·命令本身的優化,例如優化SQL語句等。 ·減少網路通訊次數。 ·降低接入成本,例如客戶端使用長連/連線池、NIO等。 這裡我們假設命令、客戶端連線已經為最優,重點討論減少網路操作次數。以Redis批量獲取n個字串為例,有三種實現方法,如下圖所示。

·客戶端n次get:n次網路+n次get命令本身。 ·客戶端1次pipeline get:1次網路+n次get命令本身。 ·客戶端1次mget:1次網路+1次mget命令本身。 上面已經給出了IO的優化思路以及單個節點的批量操作優化方式,下面結合Redis Cluster的一些特性對四種分散式的批量操作方式進行說明。1.序列命令 由於n個key是比較均勻地分佈在Redis Cluster的各個節點上,因此無法 使用mget命令一次性獲取,所以通常來講要獲取n個key的值,最簡單的方法 就是逐次執行n個get命令,這種操作時間複雜度較高,它的操作時間=n次網路時間+n次命令時間,網路次數是n。很顯然這種方案不是最優的,但是實 現起來比較簡單,如下圖所示。

Jedis客戶端示例程式碼如下:
List<String> serialMGet(List<String> keys) {
// 結果集
List<String> values = new ArrayList<String>();
// n次序列get
for (String key : keys) {
String value = jedisCluster.get(key);
values.add(value);
}
return values;
}
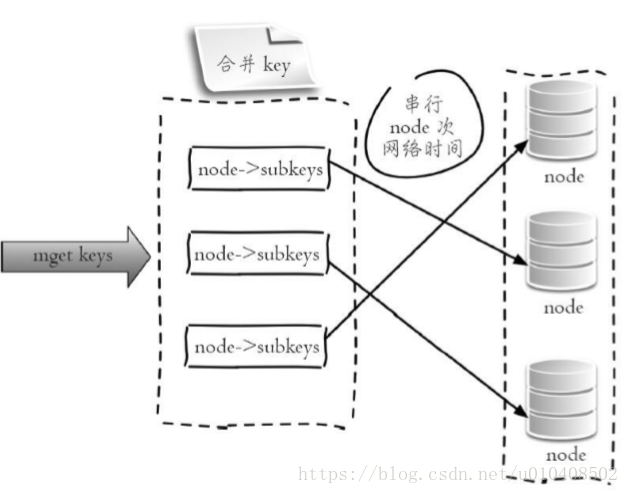
2.序列IO Redis Cluster使用CRC16演算法計算出雜湊值,再取對16383的餘數就可以算出slot值,同時Jedis客戶端會儲存slot和節點的對應關係,有了這兩個資料就可以將屬於同一個節點的key進行歸檔,得到每個節點的key子列表,之後對每個節點執行mget或者Pipeline操作,它的操作時間 =node次網路時間+n次命令時間,網路次數是node的個數,整個過程如下圖所示,很明顯這種方案比第一種要好很多,但是如果節點數太多,還是有一定的效能問題。
Jedis客戶端示例程式碼如下:
Map<String, String> serialIOMget(List<String> keys) {
// 結果集
Map<String, String> keyValueMap = new HashMap<String, String>();
// 屬於各個節點的key列表,JedisPool要提供基於ip和port的hashcode方法
Map<JedisPool, List<String>> nodeKeyListMap = new HashMap<JedisPool, List<String>>()
// 遍歷所有的key
for (String key : keys) {
// 使用CRC16本地計算每個key的slot
int slot = JedisClusterCRC16.getSlot(key);
// 通過jedisCluster本地slot->node對映獲取slot對應的node
JedisPool jedisPool = jedisCluster.getConnectionHandler()
.getJedisPoolFromSlot(slot);
// 歸檔
if (nodeKeyListMap.containsKey(jedisPool)) {
nodeKeyListMap.get(jedisPool).add(key);
} else {
List<String> list = new ArrayList<String>();
list.add(key);
nodeKeyListMap.put(jedisPool, list);
}
}
// 從每個節點上批量獲取,這裡使用mget也可以使用pipeline
for (Entry<JedisPool, List<String>> entry : nodeKeyListMap.entrySet()) {
JedisPool jedisPool = entry.getKey();
List<String> nodeKeyList = entry.getValue();
// 列表變為陣列
String[] nodeKeyArray = nodeKeyList.toArray(new String[nodeKeyList.size()]);
// 批量獲取,可以使用mget或者Pipeline
List<String> nodeValueList = jedisPool.getResource().mget(nodeKeyArray);
// 歸檔
for (int i = 0; i < nodeKeyList.size(); i++) {
keyValueMap.put(nodeKeyList.get(i), nodeValueList.get(i));
}
}
return keyValueMap;
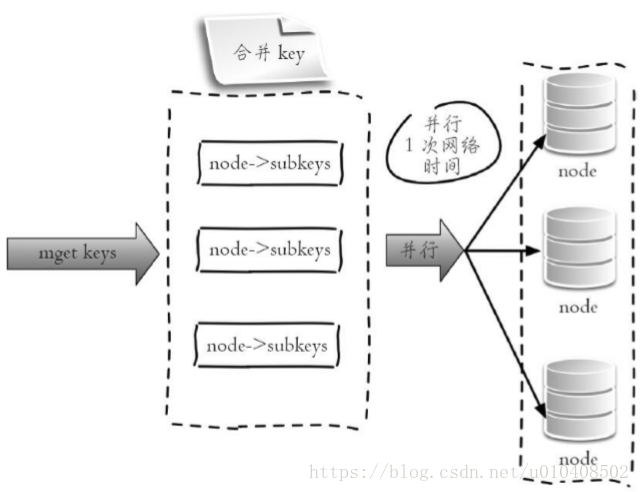
}3.並行IO 此方案是將方案2中的最後一步改為多執行緒執行,網路次數雖然還是節點個數,但由於使用多執行緒網路時間變為O(1),這種方案會增加程式設計的複雜度。它的操作時間為:
max_slow(node網路時間)+n次命令時間
整個過程如下圖所示。Jedis客戶端示例程式碼如下,只需要將序列IO變為多執行緒:
Jedis客戶端示例程式碼如下,只需要將序列IO變為多執行緒:
Map<String, String> parallelIOMget(List<String> keys) {
// 結果集
Map<String, String> keyValueMap = new HashMap<String, String>();
// 屬於各個節點的key列表
Map<JedisPool, List<String>> nodeKeyListMap = new HashMap<JedisPool,
List<String>>()
...和前面一樣
// 多執行緒mget,最終彙總結果
for (Entry<JedisPool, List<String>> entry : nodeKeyListMap.entrySet()) {
// 多執行緒實現
}
return keyValueMap;
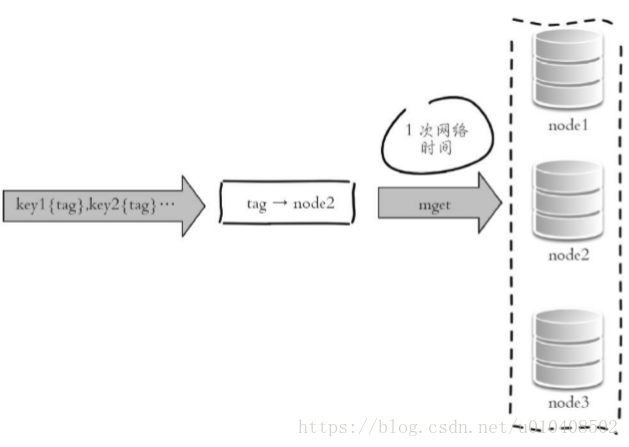
}4.hash_tag實現 Redis Cluster的hash_tag功能,可以將多個key強制分配到 一個節點上,它的操作時間=1次網路時間+n次命令時間,如下圖所示。
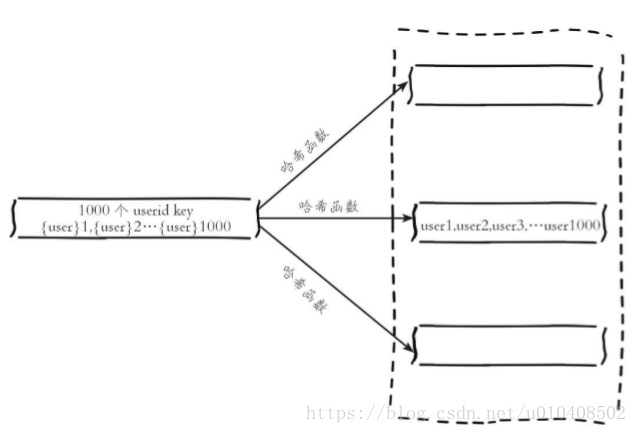
如下圖所示,所有key屬於node2節點。
Jedis客戶端示例程式碼如下:
List<String> hashTagMget(String[] hashTagKeys) {
return jedisCluster.mget(hashTagKeys);
}
上面對批量操作的四種方案進行了介紹,最後通過下表來對四種方案的優缺點、網路IO次數進行一個總結。
| 方案 | 優點 | 缺點 | 網路IO |
| 序列命令 |
1)程式設計簡單 2)如果少量keys,效能可以滿足要求 |
大量keys請求,延遲嚴重 | o(keys) |
| 序列IO |
1)程式設計簡單 2)少量節點,效能滿足要求 |
大量node延遲嚴重 | o(nodes) |
| 並行IO | 利用並行特點,延遲取決於最慢的節點 |
1)程式設計複雜 2)由於多執行緒,問題定位可能較難 |
o(max_slow(nodes)) |
| hash_tag | 效能最高 |
1)業務維護成本較高 2)容易出現數據傾斜 |
o(1) |
實際開發中可以根據上表給出的優缺點進行分析,沒有最好的方案只有最合適的方案。
6 雪崩優化
下圖描述了什麼是快取雪崩:由於快取層承載著大量請求,有效地保護了儲存層,但是如果快取層由於某些原因不能提供服務,於是所有的請求都會達到儲存層,儲存層的呼叫量會暴增,造成儲存層也會級聯宕機的情 況。快取雪崩的英文原意是stampeding herd(奔逃的野牛),指的是快取層宕掉後,流量會像奔逃的野牛一樣,打向後端儲存。
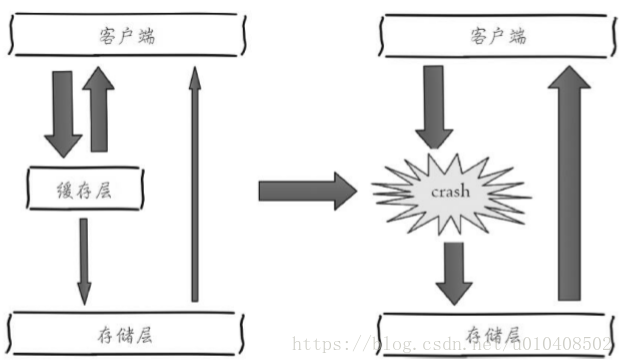
預防和解決快取雪崩問題,可以從以下三個方面進行著手。1)保證快取層服務高可用性。如果快取層設計成高可用的,即使個別節點、個別機器、甚至是機房宕掉,依然可以提供服務,例如前面介紹過的Redis Sentinel和Redis Cluster都實現了高可用。2)依賴隔離元件為後端限流並降級。無論是快取層還是儲存層都會有出錯的概率,可以將它們視同為資源。作為併發量較大的系統,假如有一個資源不可用,可能會造成執行緒全部阻塞(hang)在這個資源上,造成整個系統不可用。降級機制在高併發系統中是非常普遍的:比如推薦服務中,如果個性化推薦服務不可用,可以降級補充熱點資料,不至於造成前端頁面是開天窗。在實際專案中,我們需要對重要的資源(例如Redis、MySQL、 HBase、外部介面)都進行隔離,讓每種資源都單獨執行在自己的執行緒池中,即使個別資源出現了問題,對其他服務沒有影響。但是執行緒池如何管理,比如如何關閉資源池、開啟資源池、資源池閥值管理,這些做起來還是 相當複雜的。這裡推薦一個Java依賴隔離工具 Hystrix(https://github.com/netflix/hystrix)。Hystrix是解決依賴隔離的利器,只適用於Java應用,這裡不做詳細介紹。3)提前演練。在專案上線前,演練快取層宕掉後,應用以及後端的負載情況以及可能出現的問題,在此基礎上做一些預案設定。
7 熱點key重建優化
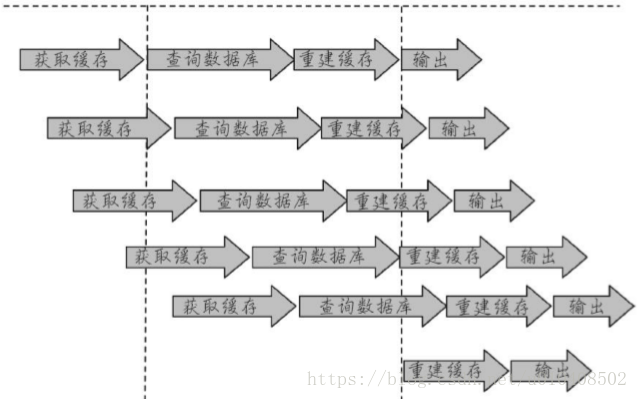
開發人員使用“快取+過期時間”的策略既可以加速資料讀寫,又保證資料的定期更新,這種模式基本能夠滿足絕大部分需求。但是有兩個問題如果同時出現,可能就會對應用造成致命的危害: ·當前key是一個熱點key(例如一個熱門的娛樂新聞),併發量非常大。 ·重建快取不能在短時間完成,可能是一個複雜計算,例如複雜的SQL、多次IO、多個依賴等。 在快取失效的瞬間,有大量執行緒來重建快取(如下圖所示),造成後端負載加大,甚至可能會讓應用崩潰。要解決這個問題也不是很複雜,但是不能為了解決這個問題給系統帶來更多的麻煩,所以需要制定如下目標:
·減少重建快取的次數 ·資料儘可能一致。 ·較少的潛在危險。
1.互斥鎖(mutex key) 此方法只允許一個執行緒重建快取,其他執行緒等待重建快取的執行緒執行完,重新從快取獲取資料即可,整個過程如下圖所示。
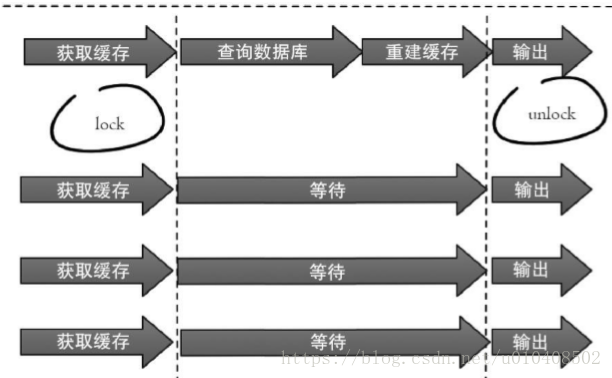
下面程式碼使用Redis的setnx命令實現上述功能:
String get(String key) {
// 從Redis中獲取資料
String value = redis.get(key);
// 如果value為空,則開始重構快取
if (value == null) {
// 只允許一個執行緒重構快取,使用nx,並設定過期時間ex
String mutexKey = "mutext:key:" + key;
if (redis.set(mutexKey, "1", "ex 180", "nx")) {
// 從資料來源獲取資料
value = db.get(key);
// 回寫Redis,並設定過期時間
redis.setex(key, timeout, value);
// 刪除key_mutex
redis.delete(mutexKey);
}
// 其他執行緒休息50毫秒後重試
else {
Thread.sleep(50);
get(key);
}
}
return value;
}
1)從Redis獲取資料,如果值不為空,則直接返回值;否則執行下面的2.1)和2.2)步驟。 2.1)如果set(nx和ex)結果為true,說明此時沒有其他執行緒重建快取,那麼當前執行緒執行快取構建邏輯。 2.2)如果set(nx和ex)結果為false,說明此時已經有其他執行緒正在執行構建快取的工作,那麼當前執行緒將休息指定時間(例如這裡是50毫秒,取決於構建快取的速度)後,重新執行函式,直到獲取到資料。
2.永遠不過期 “永遠不過期”包含兩層意思: ·從快取層面來看,確實沒有設定過期時間,所以不會出現熱點key過期 後產生的問題,也就是“物理”不過期。 ·從功能層面來看,為每個value設定一個邏輯過期時間,當發現超過邏輯過期時間後,會使用單獨的執行緒去構建快取。 整個過程如下圖所示。
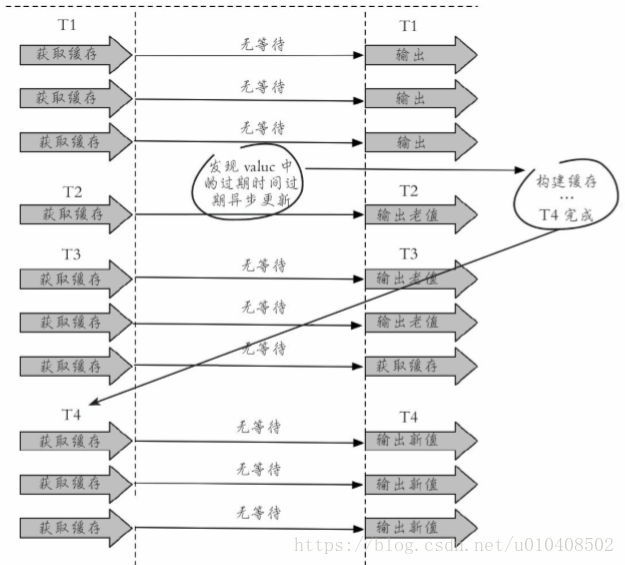
從實戰看,此方法有效杜絕了熱點key產生的問題,但唯一不足的就是重構快取期間,會出現資料不一致的情況,這取決於應用方是否容忍這種不 一致。下面程式碼使用Redis進行模擬:
String get(final String key) {
V v = redis.get(key);
String value = v.getValue();
// 邏輯過期時間
long logicTimeout = v.getLogicTimeout();
// 如果邏輯過期時間小於當前時間,開始後臺構建
if (v.logicTimeout <= System.currentTimeMillis()) {
String mutexKey = "mutex:key:" + key;
if (redis.set(mutexKey, "1", "ex 180", "nx")) {
// 重構快取
threadPool.execute(new Runnable() {
public void run() {
String dbValue = db.get(key);
redis.set(key, (dbvalue,newLogicTimeout));
redis.delete(mutexKey);
}
});
}
}
return value;
}作為一個併發量較大的應用,在使用快取時有三個目標:第一,加快使用者訪問速度,提高使用者體驗。第二,降低後端負載,減少潛在的風險,保證 系統平穩。第三,保證資料“儘可能”及時更新。下面將按照這三個維度對上述兩種解決方案進行分析。·互斥鎖(mutex key):這種方案思路比較簡單,但是存在一定的隱患,如果構建快取過程出現問題或者時間較長,可能會存在死鎖和執行緒池阻塞的風險,但是這種方法能夠較好地降低後端儲存負載,並在一致性上做得比較好。·“永遠不過期”:這種方案由於沒有設定真正的過期時間,實際上已經 不存在熱點key產生的一系列危害,但是會存在資料不一致的情況,同時代碼複雜度會增大。
兩種解決方法對比如下表所示:
| 解決方法 | 優點 | 缺點 |
| 簡單分散式鎖 |
1)思路簡單 2)保證一致性 |
程式碼複雜度增大 存在死鎖的風險 |
| 永不過期 | 基本杜絕熱點key問題 |
不保證一致性 邏輯過期時間增加程式碼維護成本和記憶體成本 |
小結:
1)快取的使用帶來的收益是能夠加速讀寫,降低後端儲存負載。 2)快取的使用帶來的成本是快取和儲存資料不一致性,程式碼維護成本增大,架構複雜度增大。 3)比較推薦的快取更新策略是結合剔除、超時、主動更新三種方案共同完成。 4)穿透問題:使用快取空物件和布隆過濾器來解決,注意它們各自的使用場景和侷限性。 5)無底洞問題:分散式快取中,有更多的機器不保證有更高的效能。 有四種批量操作方式:序列命令、序列IO、並行IO、hash_tag。 6)雪崩問題:快取層高可用、客戶端降級、提前演練是解決雪崩問題的重要方法。 7)熱點key問題:互斥鎖、“永遠不過期”能夠在一定程度上解決熱點 key問題,開發人員在使用時要了解它們各自的使用成本。