
libgo 原始碼剖析(2. libgo排程策略原始碼實現)
本文將從原始碼實現上對 libgo 的排程策略進行分析,主要涉及到上一篇文章中的三個結構體的定義:
- 排程器 Scheduler(簡稱 S)
- 執行器 Processer(簡稱 P)
- 協程 Task(簡稱 T)
三者的關係如下圖所示:
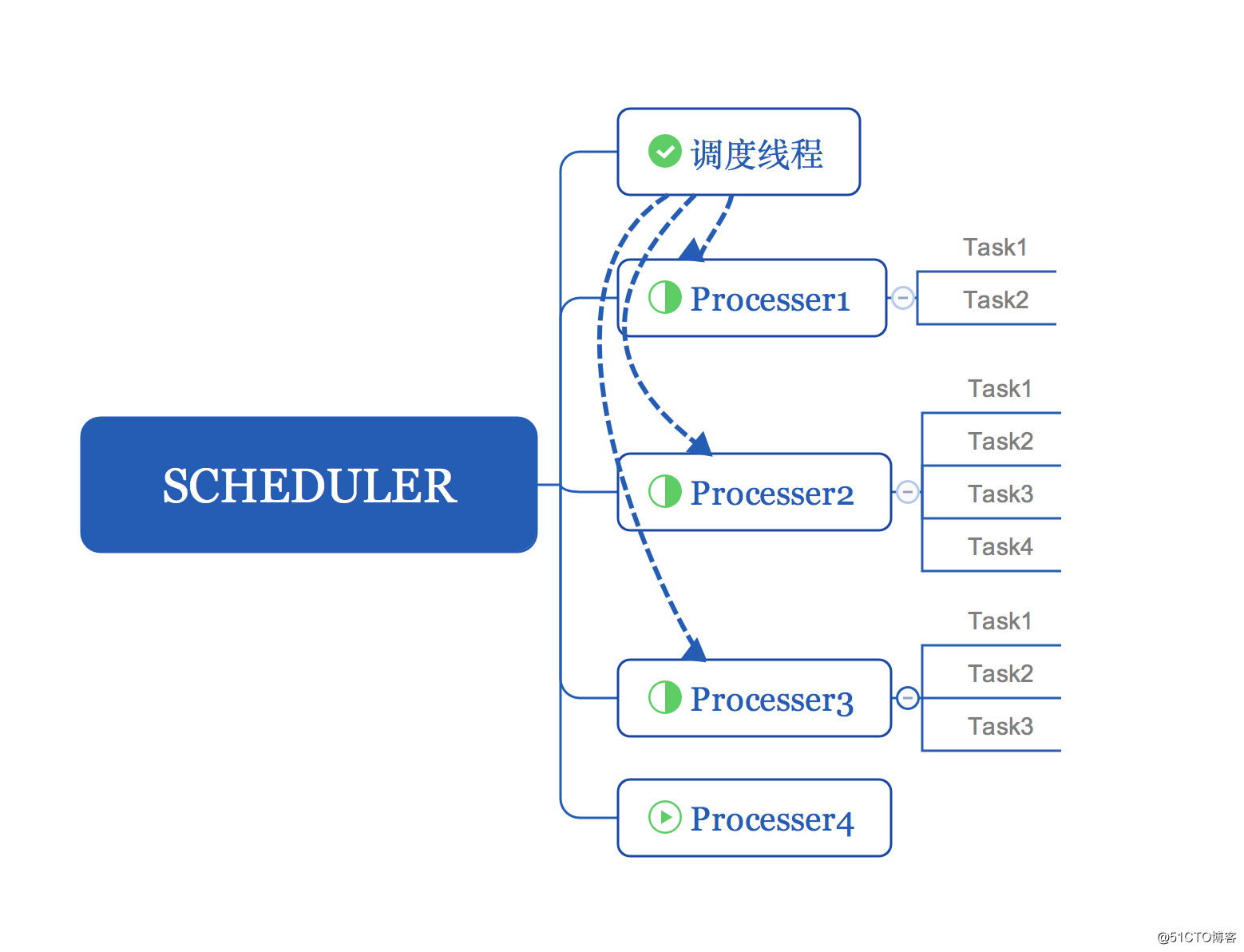
本文會列出類內的主要成員和主要函式做以分析。
1. 協程排程器:class Scheduler
libgo/scheduler/scheduler.h
class Scheduler{ public: /* * 建立一個排程器,初始化 libgo * 建立主執行緒的執行器,如果後續 STart 的時候沒有引數,預設只有一個執行器去做 * 當僅使用一個執行緒進行協程排程時, 協程地執行會嚴格地遵循其建立順序. * */ static Scheduler* Create(); /* * 建立一個協程 Task 物件,並新增到當前的執行器 processer 的任務佇列中, * 排程器的任務數 taskCount_ +1 * */ void CreateTask(TaskF const& fn, TaskOpt const& opt); /* 啟動排程器 * @minThreadNumber : 最小排程執行緒數, 為0時, 設定為cpu核心數. * @maxThreadNumber : 最大排程執行緒數, 為0時, 設定為minThreadNumber. * 如果maxThreadNumber大於minThreadNumber, 則當協程產生長時間阻塞時, * 可以自動擴充套件排程執行緒數. * 喚醒定時器執行緒 * 每個排程執行緒都會呼叫 Process 開始排程,最後開啟 id 為 0 的排程執行緒 * 如果 maxThreadNumber_ > 1 的話,會開啟排程執行緒 DispatcherThread * */ void Start(int minThreadNumber = 1, int maxThreadNumber = 0); /* * 停止排程,停止後無法恢復, 僅用於安全退出main函式 * 如果某個排程執行緒被協程阻塞, 必須等待阻塞結束才能退出. * */ void Stop(); private: /* * 排程執行緒,主要為平衡多個 processer 的負載將高負載或阻塞的 p 中的協程 steal 給低負載的 p * 如果全部阻塞但是還有協程待執行,會起新執行緒,執行緒數不超過 maxThreadNumber_ * 會將阻塞 P 中的協程分攤給負載較少的 P * */ void DispatcherThread(); /* * 建立一個新的 Processer,並新增到雙端佇列 processers_ 中 * */ void NewProcessThread(); private: atomic_t<uint32_t> taskCount_{0}; // 用來統計協程數量 Deque<Processer*> processers_; // DispatcherThread雙端佇列,用來存放所有的執行器,每個執行器都會單獨開一個執行緒去執行,執行緒中回撥 Process() 方法。 LFLock started_; // libgo 提供的自選鎖 };
排程器負責管理 1~N 個排程執行緒,每個排程執行緒一個執行器 Processer。排程器僅負責均衡各個執行器的負載,防止全部卡住的情況,並不涉及協程的切換等工作。
使用
ligbo提供了預設的協程排程器 co_sched
#define g_Scheduler ::co::Scheduler::getInstance()
#define co_sched g_Scheduler使用者也可以建立自己的協程排程器
co::Scheduler* my_sched = co::Scheduler::Create();啟動排程
std::thread t([my_sched]{mysched->Start();}); t.detach();
排程器原理
-
schedule 負責整個系統的協程排程,協程的執行依賴於執行器 Processer(簡稱 P),因此在排程器初始化的時候會選擇建立 P 的數量(支援動態增長),所有的執行器會新增到雙端佇列中。主執行緒也作為一個執行器,在建立 Scheduler 物件的時候建立,位於雙端佇列下標為 0 的位置(注意:只是建立物件,並沒有開始執行);
-
當呼叫了 Start() 函式後,會正式開始執行。在 Start 函式內部,會建立指定數量的執行器 P,具體數量取決於引數,預設會建立 minThreadNumber 個,當全部執行器都阻塞之後,會動態擴充套件,最多 maxThreadNumber 個執行器。每個執行器都會運行於一個單獨的執行緒,執行器負責該執行緒內部協程的切換和執行;
-
當建立協程時,會將協程新增到某一個處於活躍狀態的執行器,如果恰好都不活躍,也會新增到某一個 P 中,這並不影響執行器的正常工作,因為排程器的排程執行緒會去處理它;
-
Start 函式內部,除了上述執行器所線上程,還會開啟排程執行緒 DispatcherThread,排程執行緒會平衡各個 P 的協程數量和負載,進行 steal,如果所有 P 都阻塞,會根據 maxThreadNumber 動態增加 P 的數量,如果僅僅部分 P 阻塞,會將阻塞的 P 中的協程全部拿出(steal),均攤到負載最小的 P 中;
-
Schedule 也會選擇性開啟協程的定時器執行緒;
- 開啟 FastSteadyClock 執行緒。
關於定時器以及時鐘的實現,會在之後的文章中討論。
2. 協程執行器:class Processer
libgo/scheduler/processer.h
每個協程執行器對應一個執行緒,負責本執行緒的協程排程,但並非執行緒安全的,是協程排程的核心。
class Processer
{
public:
// 協程掛起標識,用於後續進行喚醒和超時判斷
struct SuspendEntry {
// ...
};
// 協程切出
ALWAYS_INLINE static void StaticCoYield();
// 掛起當前協程
static SuspendEntry Suspend();
// 掛起當前協程, 並在指定時間後自動喚醒
static SuspendEntry Suspend(FastSteadyClock::duration dur);
// 喚醒協程
static bool Wakeup(SuspendEntry const& entry);
private:
/*
* 執行器對協程的排程,也是執行器所在現在的主處理邏輯
* */
void Process();
/*
* 從當前執行器中偷 n 個協程並返回
* n 為0則全部偷出來,否則取出相應的個數
* */
SList<Task> Steal(std::size_t n);
private:
int id_; // 執行緒 id,與 shcedule 中的 _processer 下標對應
Scheduler * scheduler_; // 該執行器依賴的排程器
volatile bool active_ = true; // 該執行器的活躍狀態,活躍表明該執行器未被阻塞,由排程器的排程執行緒控制
volatile uint64_t switchCount_ = 0; // 協程排程的次數
// 當前正在執行的協程
Task* runningTask_{nullptr};
Task* nextTask_{nullptr};
// 協程佇列
typedef TSQueue<Task, true> TaskQueue;
TaskQueue runnableQueue_; // 執行協程佇列
TaskQueue waitQueue_; // 等待協程佇列
TSQueue<Task, false> gcQueue_; // 待回收的協程佇列,協程執行完畢之後,會被新增到該佇列中,等待回收
TaskQueue newQueue_; // 新新增到該執行器中的協程,包括剛剛 steal 過來的協程,該佇列中的協程暫不會執行,會由 Process() 函式將該佇列中的協程不斷新增到 runnableQueue_ 中
volatile uint64_t switchCount_ = 0; // 協程排程的次數
// 執行器等待的條件變數
std::mutex cvMutex_;
std::condition_variable cv_;
std::atomic_bool waiting_{false};
};
// 通過條件變數,喚醒處於等待狀態但是有任務的 P
void NotifyCondition();執行器對協程的排程 Process()
執行器 Processer 維護了三個執行緒安全的協程佇列:
- runnableQueue_:可執行協程佇列;
- waitQueue_:存放掛起的協程;
- newQueue_:該佇列中存放的是新加入的協程,包括新建立的協程,喚醒掛起的協程,還有 steal 來的協程;
void Processer::Process()
{
GetCurrentProcesser() = this;
bool & isStop = *stop_;
while (!isStop)
{
runnableQueue_.front(runningTask_);
// 獲取一個可以執行對協程物件
if (!runningTask_) {
if (AddNewTasks())
runnableQueue_.front(runningTask_);
if (!runningTask_) {
WaitCondition(); // 沒有可以執行的協程,wait 條件變數
AddNewTasks();
continue;
}
}
addNewQuota_ = 1;
while (runningTask_ && !isStop) {
runningTask_->state_ = TaskState::runnable;
runningTask_->proc_ = this;
++switchCount_;
runningTask_->SwapIn();
switch (runningTask_->state_) {
case TaskState::runnable:
{
std::unique_lock<TaskQueue::lock_t> lock(runnableQueue_.LockRef());
auto next = (Task*)runningTask_->next;
if (next) {
runningTask_ = next;
runningTask_->check_ = runnableQueue_.check_;
break;
}
if (addNewQuota_ < 1 || newQueue_.emptyUnsafe()) {
runningTask_ = nullptr;
} else {
lock.unlock();
if (AddNewTasks()) {
runnableQueue_.next(runningTask_, runningTask_);
-- addNewQuota_;
} else {
std::unique_lock<TaskQueue::lock_t> lock2(runnableQueue_.LockRef());
runningTask_ = nullptr;
}
}
}
break;
case TaskState::block:
{
std::unique_lock<TaskQueue::lock_t> lock(runnableQueue_.LockRef());
runningTask_ = nextTask_;
nextTask_ = nullptr;
}
break;
case TaskState::done:
default:
{
runnableQueue_.next(runningTask_, nextTask_);
if (!nextTask_ && addNewQuota_ > 0) {
if (AddNewTasks()) {
runnableQueue_.next(runningTask_, nextTask_);
-- addNewQuota_;
}
}
DebugPrint(dbg_task, "task(%s) done.", runningTask_->DebugInfo());
runnableQueue_.erase(runningTask_);
if (gcQueue_.size() > 16) // 執行完畢的協程,需要回收資源
GC();
gcQueue_.push(runningTask_);
if (runningTask_->eptr_) {
std::exception_ptr ep = runningTask_->eptr_;
std::rethrow_exception(ep);
}
std::unique_lock<TaskQueue::lock_t> lock(runnableQueue_.LockRef());
runningTask_ = nextTask_;
nextTask_ = nullptr;
}
break;
}
}
}
}在排程器 Schedule 執行 Stop() 函式之前,執行器 P 會一直處於排程協程階段 Process()。在期間,執行器 P 會將執行佇列 runnableQueue 中的第一個協程獲取進行執行,如果可執行佇列為空,執行器會嘗試將處於 newQueue 中的協程新增到可執行佇列中去,如果 newQueue_ 為空,說明此時該執行器處於無協程可排程狀態,通過設定條件變數,將執行器設定為等待狀態;
當獲取到一個可執行協程之後,會執行該協程的任務。協程的執行流程是通過狀態機來實現的。(協程有三個狀態:執行中,阻塞,執行完畢)
- 對於執行中的協程,我們只需要確定下一個要執行的協程物件即可;
- 對於阻塞的協程,只有當協程掛起時(呼叫了 Suspend 方法),狀態才會切換到這裡,因此,這時候只需要去執行 nextTask 即可;
- 對於執行完畢的協程,只有當 Task 處理函式執行完成之後,狀態才會切換到這裡,因此,需要考慮對該協程資源進行回收;
條件變數
Processer 使用了 std::mutex,並且提供了條件變數用來喚醒。當排程器嘗試獲取下一個可執行的協程物件時,若此時無可用協程物件,就會主動去等待該條件變數,預設100毫秒的超時時間。
void Processer::WaitCondition()
{
GC();
std::unique_lock<std::mutex> lock(cvMutex_);
waiting_ = true;
cv_.wait_for(lock, std::chrono::milliseconds(100));
waiting_ = false;
}當排程器向該執行器中增加了新的協程物件時,會喚醒該條件變數,繼續執行 Process 流程。使用條件變數喚醒的效率,要遠遠高於不斷去輪詢。
為什麼在使用了條件變數後還要設定超時時間,定時輪詢,即使條件變數沒有被喚醒也希望它返回呢?
因為我們不希望執行緒會在這裡阻塞,只要沒有新的協程加入,就一直在死等。我們希望執行緒在等待的同時,也可以定時跳出,執行一些其它的檢測工作等。
從執行器中偷指定數量的協程出來 -> steal()
簡單來說,從執行器中取協程出來,就是從執行器維護的雙端佇列中獲取執行個數的結點。
為什麼要取出來?前面提到過,要麼該執行器負載過大,要麼該執行器處於阻塞的狀態。
SList<Task> Processer::Steal(std::size_t n)
{
if (n > 0) {
// steal 指定個數協程
newQueue_.AssertLink();
auto slist = newQueue_.pop_back(n);
newQueue_.AssertLink();
if (slist.size() >= n)
return slist;
std::unique_lock<TaskQueue::lock_t> lock(runnableQueue_.LockRef());
bool pushRunningTask = false, pushNextTask = false;
if (runningTask_)
pushRunningTask = runnableQueue_.eraseWithoutLock(runningTask_, true) || slist.erase(runningTask_, newQueue_.check_);
if (nextTask_)
pushNextTask = runnableQueue_.eraseWithoutLock(nextTask_, true) || slist.erase(nextTask_, newQueue_.check_);
auto slist2 = runnableQueue_.pop_backWithoutLock(n - slist.size());
if (pushRunningTask)
runnableQueue_.pushWithoutLock(runningTask_);
if (pushNextTask)
runnableQueue_.pushWithoutLock(nextTask_);
lock.unlock();
slist2.append(std::move(slist));
if (!slist2.empty())
DebugPrint(dbg_scheduler, "Proc(%d).Stealed = %d", id_, (int)slist2.size());
return slist2;
} else {
// steal all
newQueue_.AssertLink();
auto slist = newQueue_.pop_all();
newQueue_.AssertLink();
std::unique_lock<TaskQueue::lock_t> lock(runnableQueue_.LockRef());
bool pushRunningTask = false, pushNextTask = false;
if (runningTask_)
pushRunningTask = runnableQueue_.eraseWithoutLock(runningTask_, true) || slist.erase(runningTask_, newQueue_.check_);
if (nextTask_)
pushNextTask = runnableQueue_.eraseWithoutLock(nextTask_, true) || slist.erase(nextTask_, newQueue_.check_);
auto slist2 = runnableQueue_.pop_allWithoutLock();
if (pushRunningTask)
runnableQueue_.pushWithoutLock(runningTask_);
if (pushNextTask)
runnableQueue_.pushWithoutLock(nextTask_);
lock.unlock();
slist2.append(std::move(slist));
if (!slist2.empty())
DebugPrint(dbg_scheduler, "Proc(%d).Stealed all = %d", id_, (int)slist2.size());
return slist2;
}
}首先,會從 newQueue 佇列中獲取協程結點,因為 newQueue 中的結點還沒有新增到執行佇列中,因此可以直接取出;如果 newQueue 中協程數量不足,會從 runnableQueue 佇列尾部中繼續獲取結點。由於 runnableQueue 佇列中我們記錄了正在執行的協程和下一次將執行的協程(runningTask & nextTask),需要特殊處理。在從 runnableQueue 偷協程之前,會將 runningTask & nextTask 從佇列刪除,待偷完結點之後再次新增到當前 runnableQueue_ 佇列中。
簡單說,偷協程的工作,不會從佇列中獲取到 runningTask & nextTask 標識的協程。
協程掛起 Suspend
static SuspendEntry Suspend();一種方式是直接掛起,會將該協程狀態轉換為 TaskState::block,然後將該協程從 runnableQueue 中刪除,再新增到 waitQueue 中;
另外一種方式是掛起之後(第一種方式執行完畢之後),允許配置一個時間段之後去自動喚醒該協程。
wakeup
用於喚醒協程
喚醒協程要做的,就是講待喚醒的協程從 waitQueue_ 中刪除並重新新增到 newQueue_中去。
StaticCoYield
用於在一個執行器中切出當前協程
有兩種可能,一種是協程被阻塞需要掛起;另外一種是協程執行完畢,主動切出。
具體實現是通過獲取當前執行器正在執行的協程 Task,呼叫 SwapOut() 方法實現。
ALWAYS_INLINE void Processer::StaticCoYield()
{
auto proc = GetCurrentProcesser();
if (proc) proc->CoYield();
}
ALWAYS_INLINE void Processer::CoYield()
{
Task *tk = GetCurrentTask();
assert(tk);
++ tk->yieldCount_;
#if ENABLE_DEBUGGER
DebugPrint(dbg_yield, "yield task(%s) state = %s", tk->DebugInfo(), GetTaskStateName(tk->state_));
if (Listener::GetTaskListener())
Listener::GetTaskListener()->onSwapOut(tk->id_);
#endif
tk->SwapOut();
}幾個需要注意的問題
> 可能會切出協程上下文的幾種情況:
- 協程被掛起;
- 協程執行完畢;
- 使用者主動切出 co_yield。
#define co_yield do { ::co::Processer::StaticCoYield(); } while (0)
> 協程被掛起的幾種情況:
- 系統函式被 hook;
- libgo_poll (被 hook 的 io 操作函式會呼叫 libgo_poll 實現切換)
- select
- sleep、usleep、nanosleep
- 呼叫了協程鎖 CoMutex(co_mutex),協程讀寫鎖 CoRWMutex(co_rwmutex),或者使用了 channel。
> 切入協程上下文的幾種情況:
- 執行器在排程(Process)期間;
- 喚醒掛起協程不會切入上下文,只是從等待佇列中重新新增到 newQueue_。
3. 協程物件:struct Task
# 協程狀態
enum class TaskState
{
runnable, // 可執行
block, // 阻塞
done, // 協程執行完畢
};
typedef std::function<void()> TaskF; // c++11提供的函式模板
struct Task
{
TaskState state_ = TaskState::runnable;
uint64_t id_; // 當前排程器下協程編號,從0開始
TaskF fn_; // 協程執行的函式
uint64_t yieldCount_ = 0; // 協程切出的次數
Context ctx_; // 上下文資訊
Processer* proc_ = nullptr; // 歸屬於哪個執行器
// 提供了協程切入、切出、切換到指定執行緒三個函式
ALWAYS_INLINE void SwapIn();
ALWAYS_INLINE void SwapTo(Task* other);
ALWAYS_INLINE void SwapOut();
private:
static void StaticRun(intptr_t vp); // 引數為 Task*,函式會去執行該 Task 的 fn_(),執行完畢後,協程狀態改為 TaskState::done,並在執行器 P 中切出
};每個 Task 物件是一個協程,在使用過程中,建立一個協程實際就是建立了一個 Task 物件,再新增到對應的執行器 P 中。之前提到過,執行器進行協程排程是通過一個狀態機來實現的,這裡的 TaskState 就是協程狀態,協程函式 fn_ 會在 StaticRun 靜態方法中呼叫,該靜態方法註冊到了協程上下文 _ctx 中。
除此之外,Task 類內部,也提供了協程的切入切出方法,本質也是呼叫了上下文的切換。
StaticRun
控制協程的執行,內部呼叫了 Task::Run() 方法,會在協程函式 fn_ 執行完畢之後,將協程狀態轉換為 TaskState::done,並將協程切出。
void Task::Run()
{
auto call_fn = [this]() {
this->fn_();
this->fn_ = TaskF(); //讓協程function物件的析構也在協程中執行
};
\\ ...
call_fn();
\\ ...
state_ = TaskState::done;
Processer::StaticCoYield();
}
void Task::StaticRun(intptr_t vp)
{
Task* tk = (Task*)vp;
tk->Run();
}這裡就是對 libgo 排程相關實現的描述,本文跳過了對定時器和時鐘部分的實現,這個會在之後單獨敘述。本文涉及到的程式碼在原始碼目錄下的
libgo-master/libgo/scheduler/processer.cpp
libgo-master/libgo/scheduler/processer.h
libgo-master/libgo/scheduler/scheduler.cpp
libgo-master/libgo/scheduler/scheduler.h有興趣的讀者可以對照原始碼學習,歡迎討論學習