solr實現同義詞查詢及分詞粒度
阿新 • • 發佈:2018-12-10
首先要自己修改IKAnalyzer2012FF_u2.jar包然後重新打包
修改後的jar包下載地址:http://download.csdn.net/detail/u014793522/9594470
同義詞下載地址:
http://download.csdn.net/detail/u014793522/9594519
然後修改schema.xml檔案,在末尾處新增如下程式碼
<!-- lang: xml --> <fieldType name="text_syn" class="solr.TextField"> <analyzer type="query"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="index"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="fasle"/> <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true" /> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>

在增加一個field

useSmart="false"表示使用粒度進行分詞
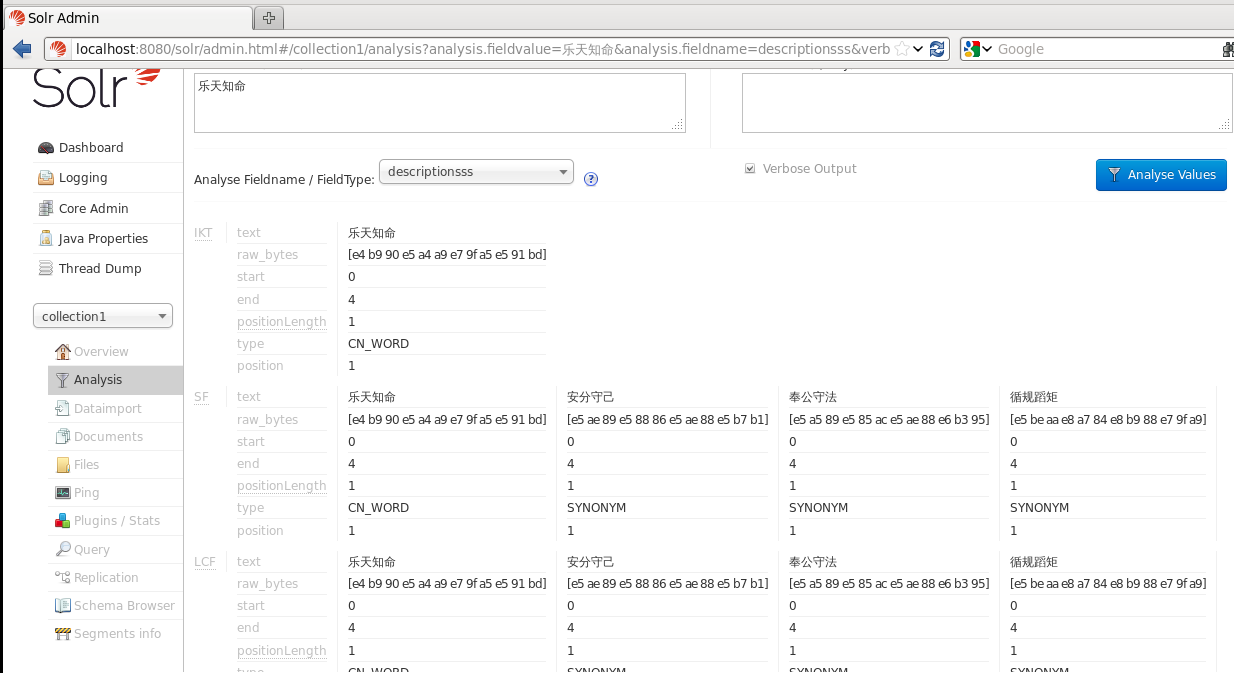
效果如圖所示
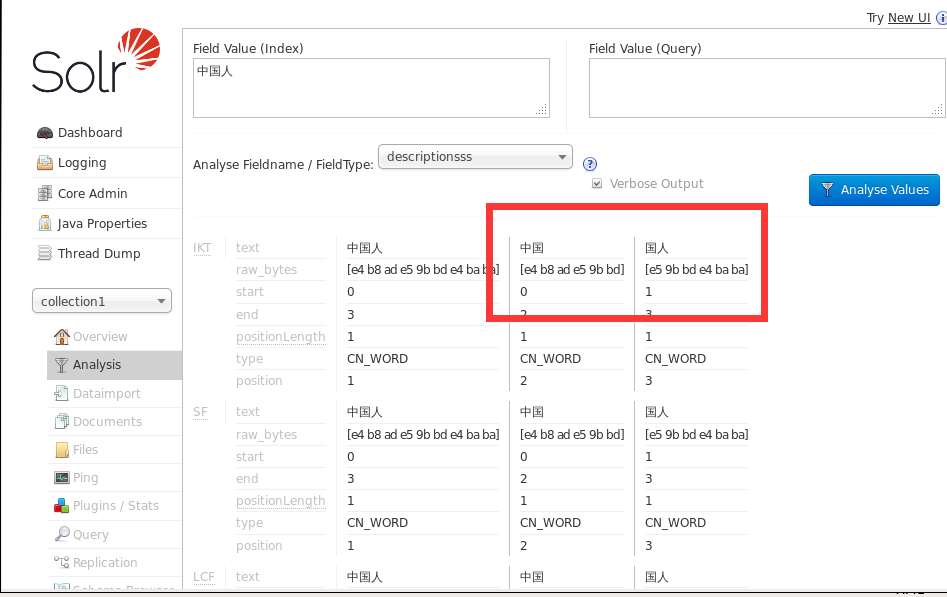
就是將中國人在進行粒度分詞
synonyms="synonyms.txt"這個就是同義詞檔案,expand這個屬性一定要設定為true,就是儘可能多的顯示
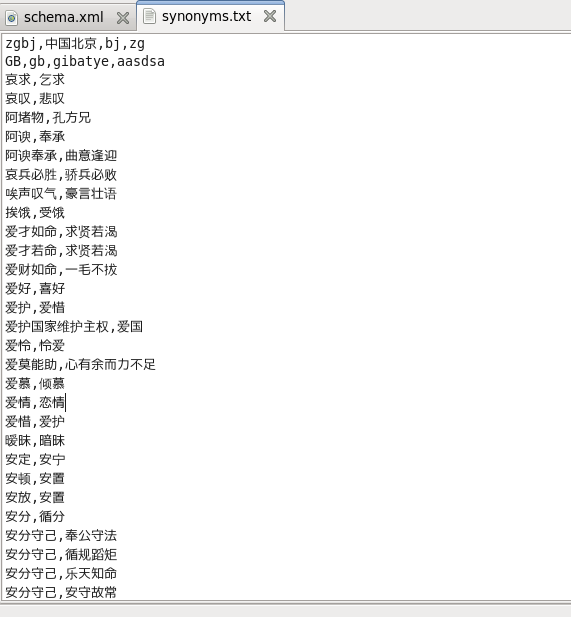
synonyms="synonyms.txt"內容如圖所示
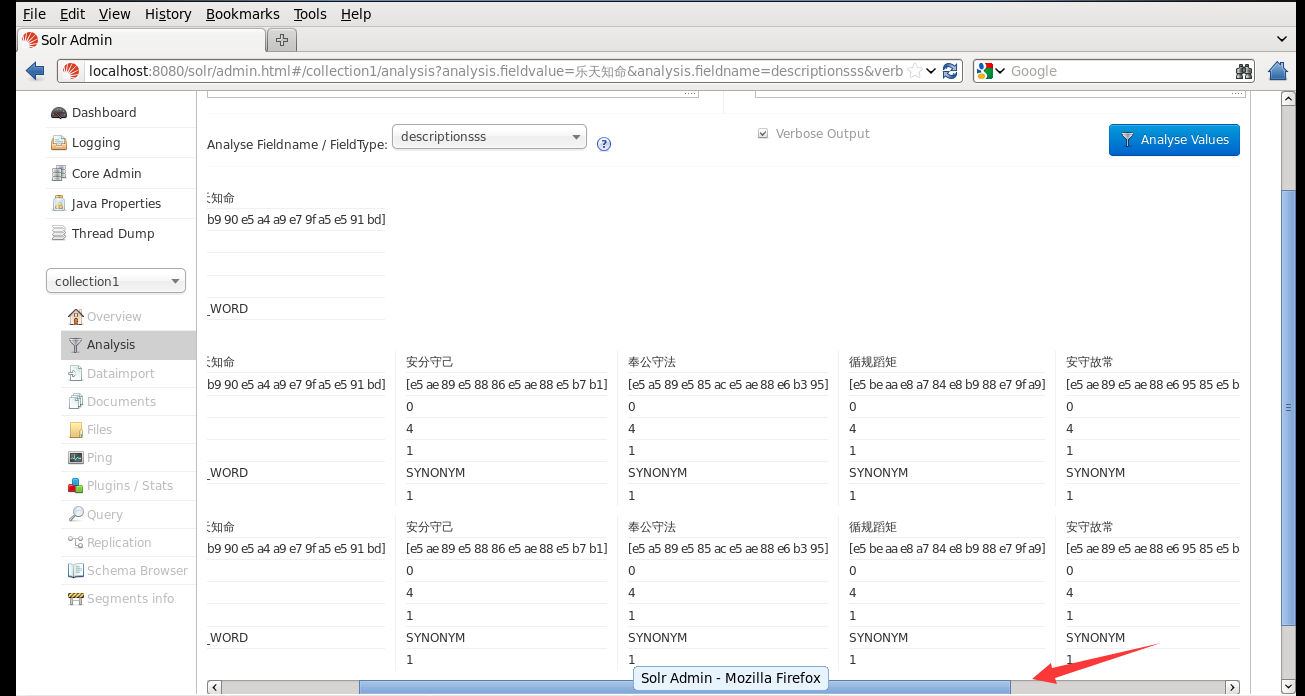
搜尋一下即可出現效果
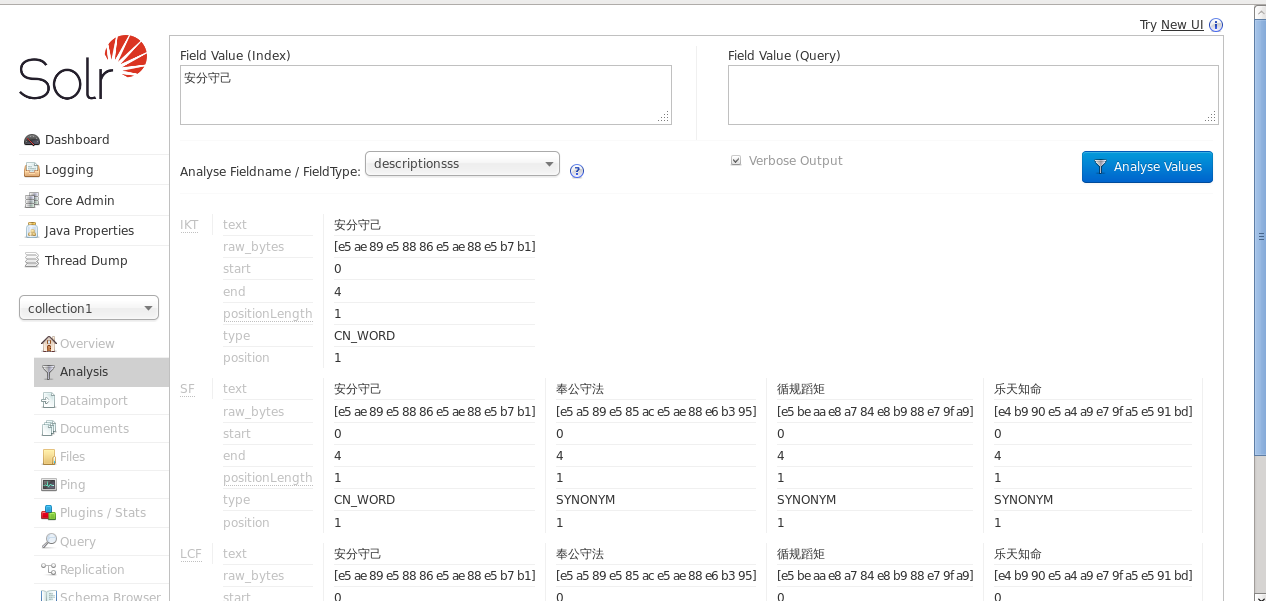
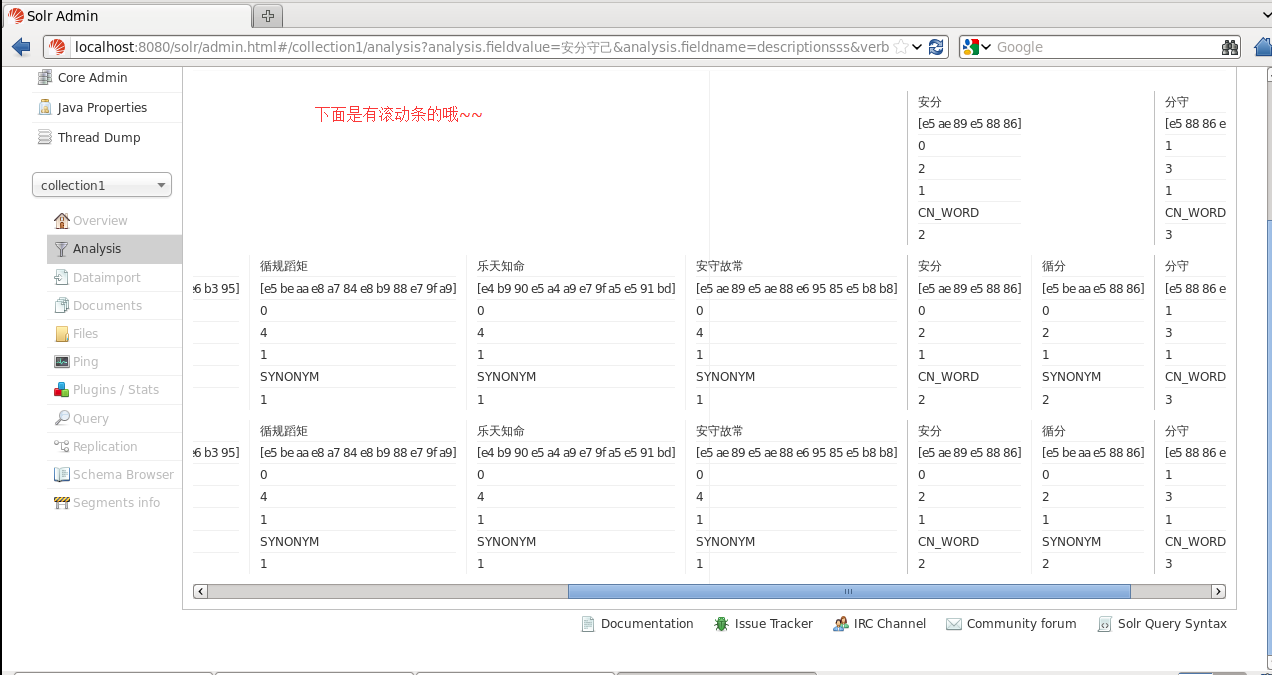
後一個詞搜前一個詞
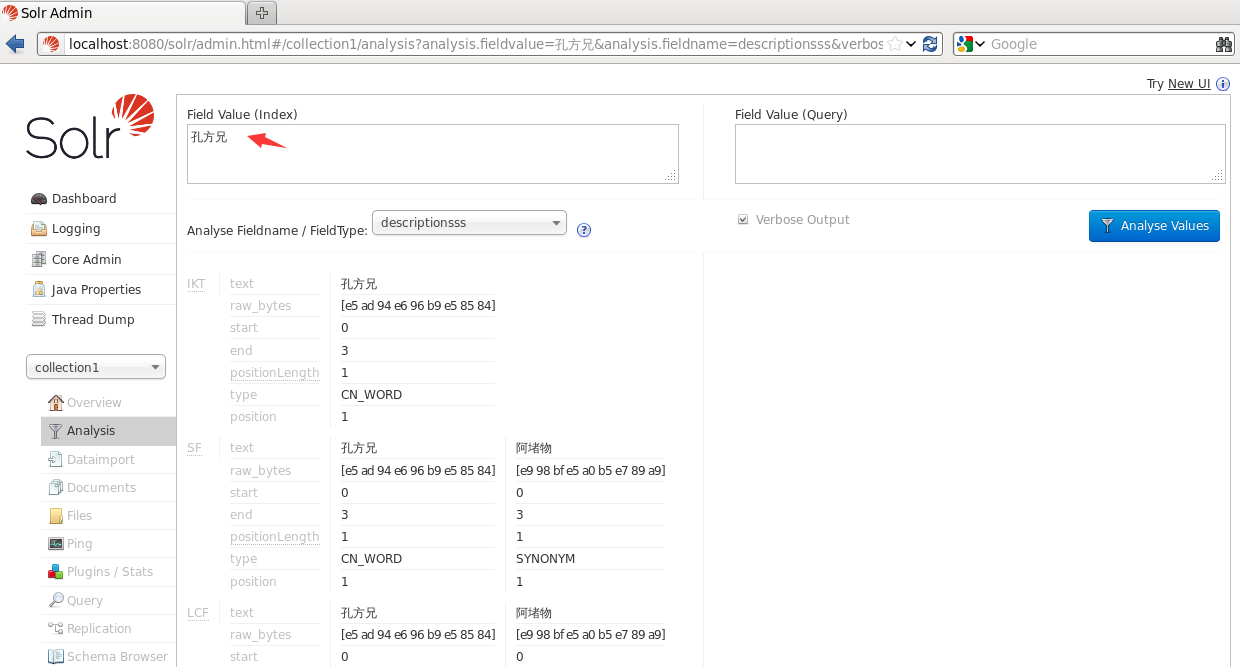
注:synonyms.txt檔案中的內容如果是相同的同義詞可以寫在同一行用,隔開

如果這樣寫我搜一個樂天知命就只能搜到安分守己 其他的幾個就不能搜出來
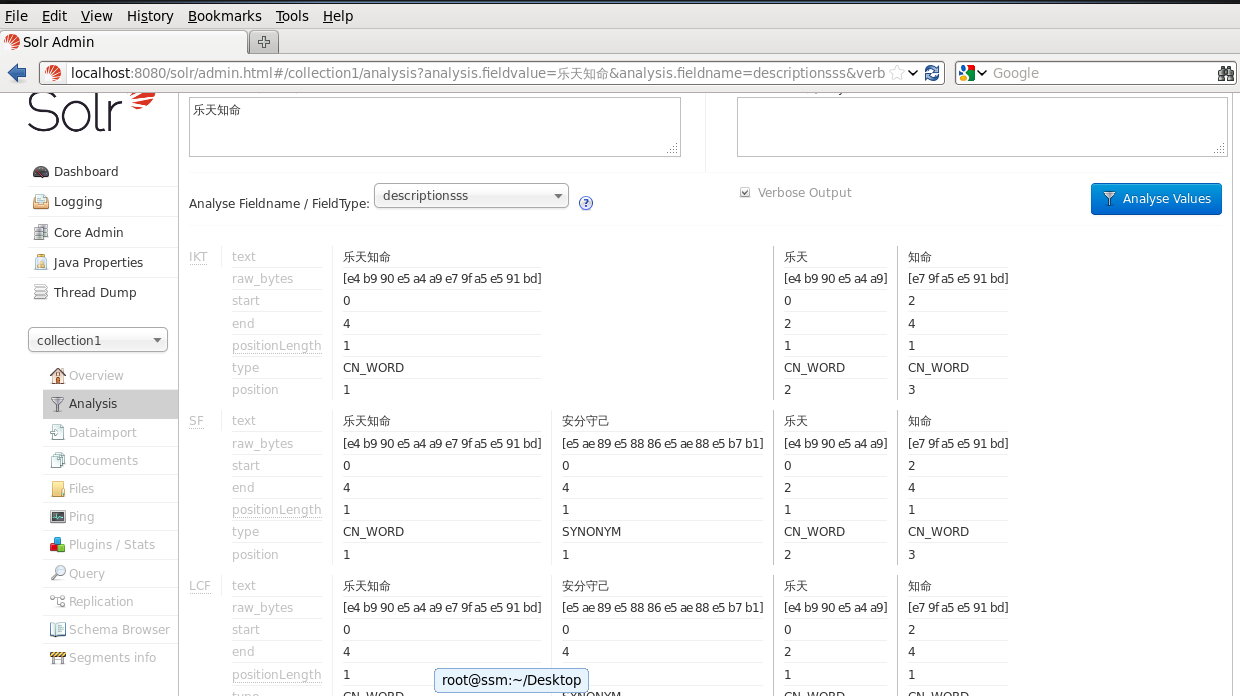
可以做一下修改

修改後的效果如圖所示