
Miccai論文分享(一)Deep Multi-instance Networks with Sparse Label Assignment for Whole Mammogram Classific
多示例學習(multi-instance learning)
本科畢業答辯結束!這個系列主要分享一些Miccai這一醫學影像分析頂級會議上論文~
為什麼講這個?
看到了miccai2017年的一篇挺有意思的論文,所以查閱了相關研究資料,分享給大家。
什麼是多示例學習?
這方面國內的大牛周志華是領域翹楚,大家有興趣可以看看他之前的相關工作。下面的部分摘自他的一個survey性質的文章。
周志華survey
在多示例學習中,訓練樣本是由多個示例組成的包,包是有概念標記的,但示例本身卻沒有概念標記。如果一個包中至少包含一個正例,則該包是一個正包,否則即為反包。
與監督學習相比,MIL中的訓練示例是沒有概念標記的,這與監督學習中所有訓練示例都有概念標記不同;與非監督學習相比,MIL中的訓練包是有概念標記的,這與非監督學習的訓練樣本中沒有任何概念標記也不同。
在以往的各種學習框架中,一個樣本就是一個示例,即樣本和示例是一一對應的關係;而在MIL中一個樣本(即包)包含了多個示例,即樣本和示例是一對多的對應關係。因此這是一種新的學習框架。
Miccai論文
那麼Miccai論文是怎麼應用這個多示例學習呢?先介紹整個論文是在幹嘛?
論文是對Mammogram乳房X光照片進行分類用來計算機輔助檢測乳腺癌,傳統的做法依賴於ROI(Regions of Interest)的獲取,即需要detection然後segementation最後再進行classification。這有兩個缺點:
- 依賴於人為設計的特徵,以及groundtruth
- 不是end-to-end
那麼這篇論文是怎麼解決的呢?
它是基於原始整個乳房X光圖片進行分類。它將每個乳房X光照片的patch看做示例,將整個乳房X光照片看做a bag of instances即上面說的包。那麼這個分類問題可以看做是標準的MIL問題。
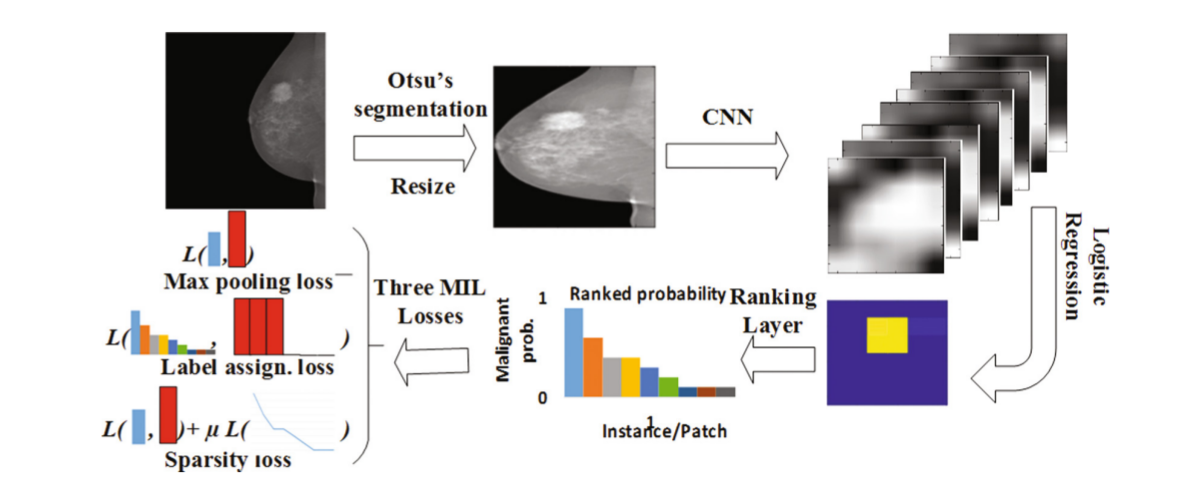
上圖就是整個乳房X照片分類的流程圖。
- 首先使用大津方法(類內方差最小,類間方差最大)來移除背景同時resize到227*227
- 使用AlexNet中的卷積層,提取它最後一個卷積層的特徵。最後會得到6*6*256的feature map
- 對CNN中的feature map進行基於惡性(當確定為惡性是為1)不同patch之間權值共享的logistic regression,然後將response進行rank。
- 最後學習的損失由三種不同的模式進行計算,分別是max pooling loss, label assignment, sparsity loss.
Deep MIL細節
邏輯迴歸
對於一個原始影象
,我們可以得到經過多層卷積和池化後的一個很小的有著多通道(通道數為
)的feature map(F)。
代表原圖
中一個patch如
的CNN特徵。可以看下面的公式:
。
256個特徵圖經過logistic regression後會得到一個6x6的圖,這個6x6圖上的每個位置的值,對應了feature map相同位置的256個特徵值經過邏輯迴歸後的值。最後其實這個6x6的圖就是每個位置的評分值,評分的大小即每個位置惡性的概率。
Max Pooling-Based Multi-instance Learning
對於傳統的MIL假設,如果存在一個示例為positive,那麼包為positive;如果所有示例為negative,那麼包才為negative。在這個問題中,如果存在惡性腫塊,那麼就為惡性,只有所有部分都為良性,才為良性。所以positive示例實際上對應的惡性,negative示例對應的為良性。所以對於negative示例,我們希望所有的示例的
都接近於0;對於positive示例,我們至少有一個示例接近與1。
對於基於最大池的學習,將得到6x6=36個概率值
進行降序排列,如下面公式
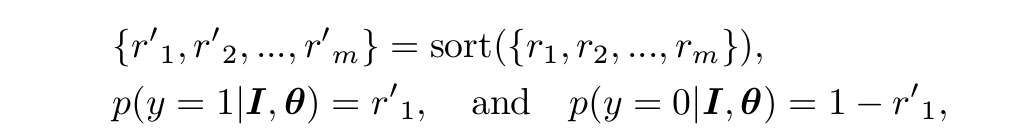
損失函式即為
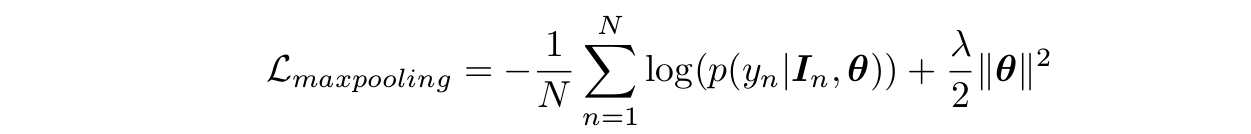
這種方法的缺點是隻考慮了最大惡性概率的塊,沒有挖掘其他塊的資訊。可以看出它的損失函式與
都無關,它不會約束其他塊的判斷。
Label Assignment-Based Multi-instance Learning
為了更好的發揮deep MIL的力量,作者將傳統的MIL假設變成一個label assignment問題。不僅只考慮第一個patch的良性還是惡性,而是考慮排序後的前k個, 認為前k個是惡性腫瘤塊而後面都是正常部分。
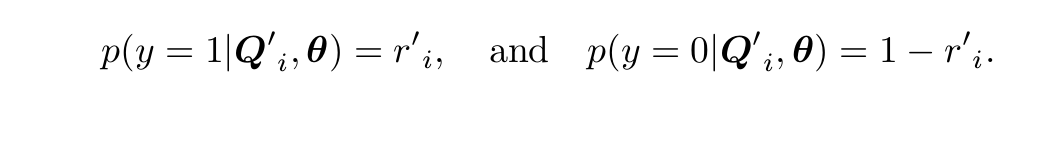
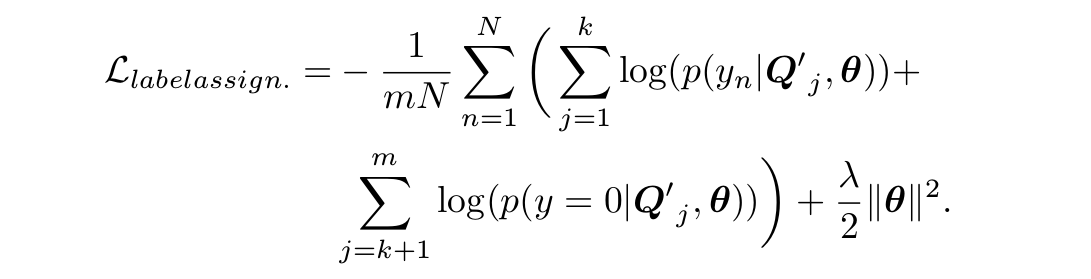
這個相比第一種方法就是挖掘了所有塊的資訊來訓練模型,但是難以確定k的取值。
Sparse Multi-instance Learning
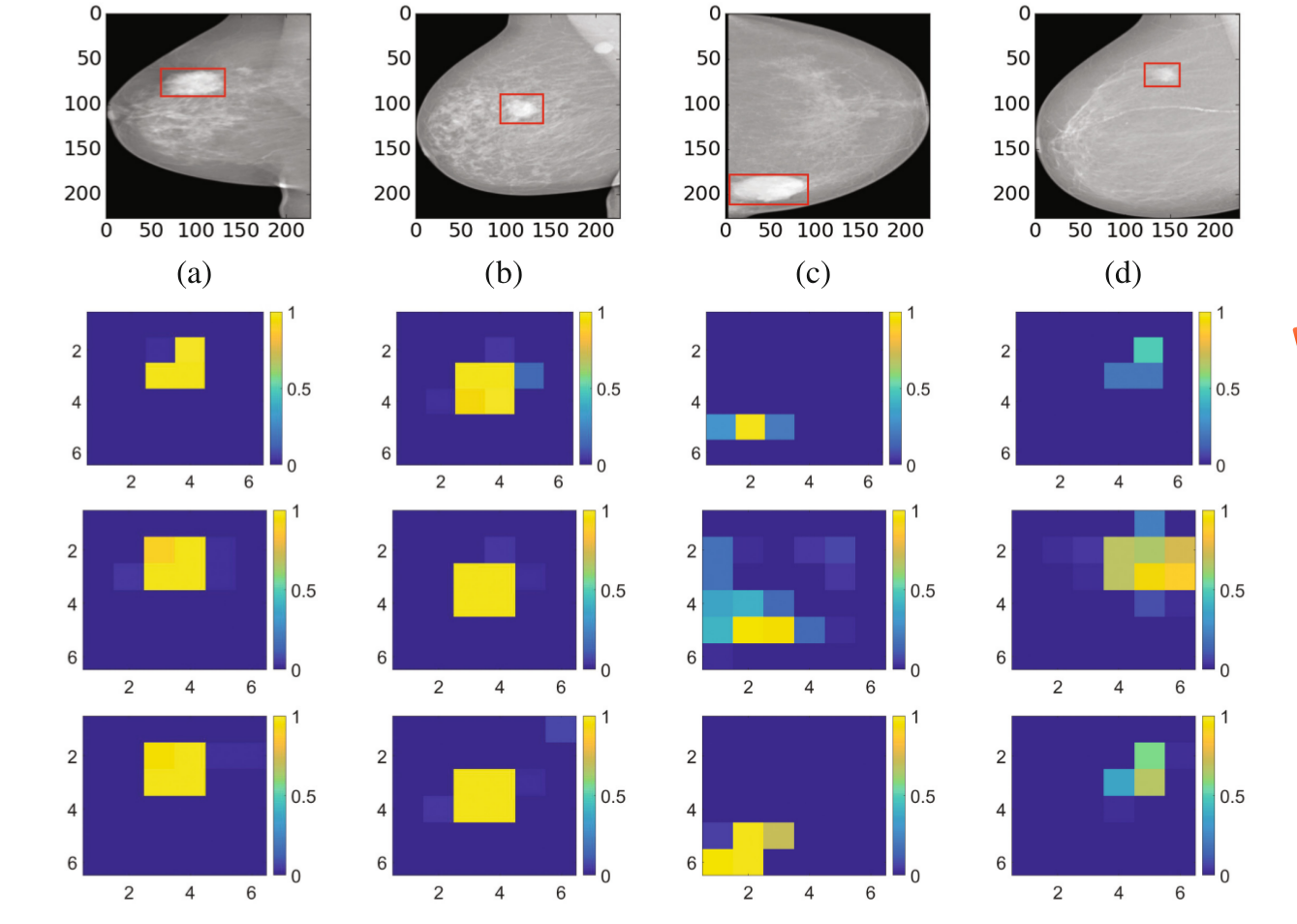
在說這個之前,作者對乳房X光照片進行了統計,統計了腫塊區域大概佔整個影象多少,看下圖。
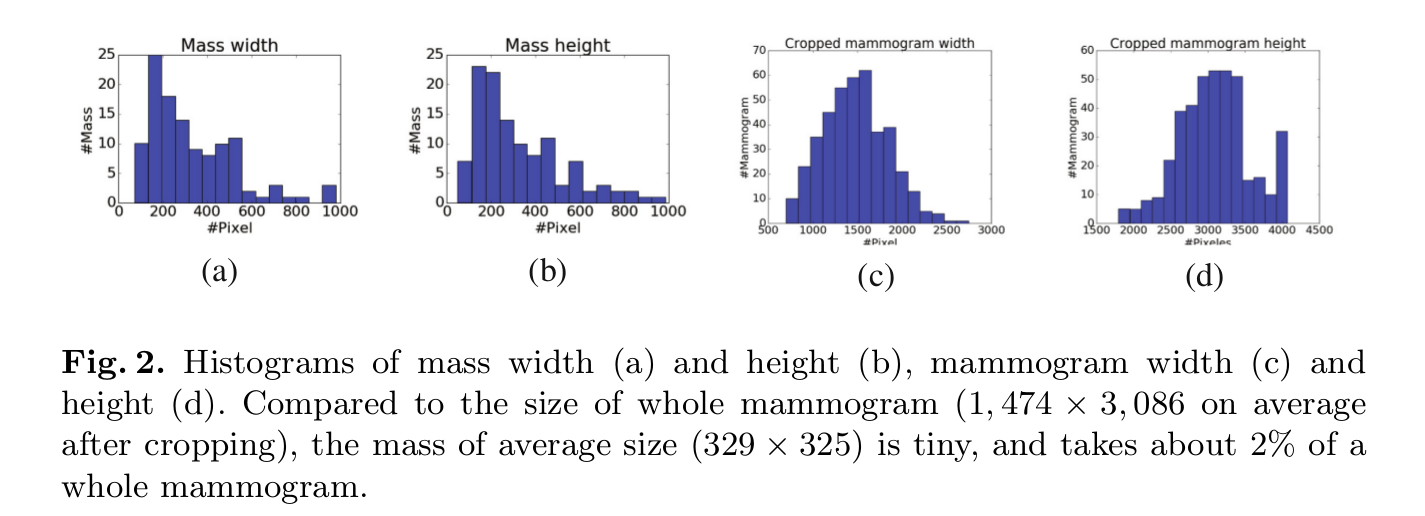
可以看出腫塊區域大概佔影象的2%,因此很多patch的那個
值要麼為0,要麼接近0。所以作者在第一種損失函式上加上了一個L1範數,
是稀疏因子,這個是稀疏假設和第一種方法的tradeoff,計算公式如下:
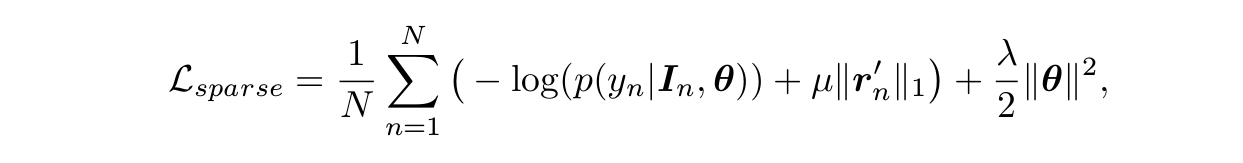
第三種方法,作者認為是第一種和第二種的tradeoff,效果可以看之間的圖,最後得到的結果也是最好的。最後作者比較了和以往方法在資料集的準確率和AUC,結果就不用說了,提升了。。。