
TensorFlow 官網API學習(Reading data)
TensorFlow 官網API學習(Reading data)
標籤(空格分隔): TensorFlow官網API
API地址
TensorFlow程式中四種獲取資料途徑
1.tf.dataAPI:很容易構建複雜的輸入流水線(推薦的方法!)
2.Feeding:在執行每一步時,利用Python程式碼提供資料。
3.QueueRunner:在TensorFlow圖最開始的時候,基於佇列的輸入佇列來讀取檔案中的資料
4.預先載入資料:在TensorFlow圖中使用常數或者變數來存入資料(僅適用於小資料集)
tf.data API
具體的細節在tf.data.Dataset
tf.dataAPI可以進行不同輸入或檔案格式的資料提取和預處理,同時可以對資料集進行批化、打亂和對映。它是舊的兩種輸入方式feeding和QueueRunner的改進版本。
Feeding
“Feeding”是效率最低的將資料載入進TensorFlow程式的方式,僅被用於小實驗和debug
TensorFlow的feed方法讓你在計算圖中給任意Tensor注入資料。提供注入資料的方式是通過feed_dict的引數,然後使用run()和eval()來呼叫初始計算。
with tf.Session():
input = tf.placeholder(tf.float32)
classifier = ... 你可以使用輸入資料來代替包括變數和常量在內的任意張量,但最好的選擇是使用tf.placeholder節點。
QueueRunner
這個部分討論的實現基於佇列的輸入流水線可以被tf.dataAPI實現清晰地替代
一個典型的從檔案讀取記錄基於佇列的流水線有下列的階段:
- 檔名列表
- (可選)檔名是否打亂
- (可選)訓練輪數限制
- 檔名佇列
- 針對檔案格式的一個讀取器(reader)
- 讀取器的解碼器
- (可選)預處理
- 樣本佇列
檔名列表,打亂和訓練輪數限制
對前三個部分,可以將一個檔名列表傳入tf.train.string_input_producer函式。string_input_producer建立一個FIFO佇列來儲存檔名直到reader需要它們。string_input_producer有是否打亂和設定訓練輪數的限制。對於每一輪,佇列runner將整個檔名列表新增進佇列一次,如果shuffle=True那麼打亂檔名,這個過程提供一個針對檔案的均勻取樣,因此樣本彼此之間不會under-或者over-取樣。這個佇列runner獨立於reader將檔案佇列中的檔名提取,因此打亂和入隊過程不會阻塞reader。
檔案格式
選擇一個合適的reader來匹配你的輸入檔案格式然後將檔名佇列傳入reader的read方法。read方法輸出一個key來標識檔案和記錄(如果你有某些奇怪的記錄對Debug很用)和一個標量字串值,使用一個(或更多)decoder和轉換器來解碼這個字串到Tensor。
CSV格式
讀取CSV格式的文字檔案,使用tf.TextLineReader和tf.decode_csv操作。
例子如下:
import tensorflow as tf
filename_queue = tf.train.string_input_producer(["file0.csv", "file1.csv"])
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# Default values, in case of empty columns. Also specifies the type of the
# decoded result.
record_defaults = [[1], [1], [1], [1], [1]]
col1, col2, col3, col4, col5 = tf.decode_csv(value, record_defaults=record_defaults)
features = tf.stack([col1, col2, col3, col4])
with tf.Session() as sess:
# Start populating the filename queue.
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(1200):
# Retrieve a single instance:
examples, label = sess.run([features, col5])
coord.request_stop()
coord.join(threads)
每一個read的執行讀取會從檔案中讀取一行。decode_csv操作會解析結果到一個Tensor列表中,record_defaults引數在輸入字串值缺失時,會確定一個預設值。
你必須在呼叫run或者eval來執行read方法前呼叫tf.train.start_queue_runners來開始佇列
定長記錄
對於每一個固定位元組的記錄形成的二進位制檔案,使用tf.FixedLengthRecordReader和tf.decode_raw操作。tf.decode_raw操作會將字串轉換為一個uint8的tensor。
對於CIFAR10資料集,它的每一個記錄都是定長的位元組。1個位元組的label然後緊跟著3072(32*32*3)位元組的影象資料。
標準TensorFlow格式
另一種將你的任意資料轉換到一個支援的格式。這種方法使得混合和匹配資料集和網路結構變得簡單。TensorFlow推薦的格式是TFRecords file,它包括tf.train.Example protocol buffers(包含Features作為域)。你需要寫一點程式來得到你的資料,將它填充進一個Example協議快取,序列化這個協議快取到一個字串,然後使用tf.python_io.TFRecordWriter來將字串寫入一個TFRecords檔案。下面是官網給出的將MNIST資料轉換到這種格式的樣例TFRecord write
推薦的方式讀取一個TFRecord檔案是使用tf.data.TFRecordDataset,TFRecord Read,為了使用基於輸入流水線佇列完成相同的工作,使用下面的程式碼:
filename_queue = tf.train.string_input_producer([filename], num_epochs=num_epochs)
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
image, label = decode(serialized_example)預處理
在解析出資料後,包括正則化資料、選取隨機的切片以及新增噪聲或者扭曲等預處理操作將進行。
Batching
在流水線最後我們使用另一個佇列來將樣本變成批來進行後續的訓練、求值和預測。我們使用tf.train.shuffle_batch來隨機化樣本的順序。
def read_my_file_format(filename_queue):
reader = tf.SomeReader()
key, record_string = reader.read(filename_queue)
example, label = tf.some_decoder(record_string)
processed_example = some_processing(example)
return processed_example, label
def input_pipeline(filenames, batch_size, num_epochs=None):
filename_queue = tf.train.string_input_producer(filenames, num_epochs=num_epochs, shuffle=True)
example, label = read_my_file_format(filename_queue)
# min_after_dequeue 定義了隨機取樣的快取大小,更大的意味著更好的隨機化但是啟動會比較慢同時會佔用更多的記憶體。
# capacity必須大於min_after_dequeue,而數量大則決定了我們預取的最大值。推薦:min_after_dequeue + (num_threads + a small safety margin) * batch_size
min_after_dequeue = 10000
capacity = min_after_dequeue + 3 * batch_size
example_batch, label_batch = tf.train.shuffle_batch([example, label], batch_size=batch_sizecapacity=capacity, min_after_dequeue=min_after_dequeue)
return example_batch, label_batch
如果你需要在檔案之間的樣本進行更多並行的打亂,通過使用tf.train.shuffle_batch_join來使用多個reader例項。例子如下:
def read_my_file_format(filename_queue):
# Same as above
reader = tf.SomeReader()
key, record_string = reader.read(filename_queue)
example, label = tf.some_decoder(record_string)
processed_example = some_processing(example)
return processed_example, label
def input_pipeline(filenames, batch_size, read_threads, num_epochs=None):
filename_queue = tf.train.string_input_producer(filenames, num_epochs=num_epochs, shuffle=True)
example_list = [read_my_file_format(filename_queue) for _ in range(read_threads)]
min_after_dequeue = 10000
capacity = min_after_dequeue + 3 * batch_size
example_batch, label_batch = tf.train.shuffle_batch_join(example_list, batch_size=batch_size, capacity=capacity, min_after_dequeue=min_after_dequeue)
return example_batch, label_batch我們依舊使用的是一個單獨的檔名佇列被所有的reader所共享。這樣確保在相同的epoch使用不同的檔案直到所有那個epoch的檔案被啟動。
另外一個可以替代方式是,使用一個reader但是在tf.train.shuffle_batch的num_threads引數設定大於1。這樣在同一時間只會讀取一個檔案(但是比只有一個執行緒要快),而不是一次讀取N個檔案。這樣做的重要性在於:
- 如果你有多於輸入檔案數量的讀取執行緒數,避免有兩個執行緒讀取來自同一份檔案同一個樣本的風險。
- 並行讀取N個檔案可能會造成多次磁碟查詢。
那麼我們應該使用什麼數量的執行緒,tf.train.shuffle_batch*函式會將樣本的佇列的擁擠情況用一個summary新增到graph中。如果擁有足夠多的讀取執行緒,summary應該會保持在0以上。使用示例
建立執行緒來預取正在使用的QueueRunner物件
很多上面列舉的tf.train函式會新增tf.train.QueueRunner物件到我們的graph中。這要求我們在執行任意訓練或者預測步驟前必須呼叫tf.train.start_queue_runners,否則就會永遠掛起。結合tf.train.Coordinator可以在出現錯誤時清晰地關閉這些執行緒。如果你設定了一個epoch的數量限制,那麼將會需要一個epoch的計數器來進行初始化。推薦的示例程式碼如下:
import tensorflow as tf
# Create the graph, etc
init_op = tf.global_variables_initializer()
# Create a session for running operations in the Graph.
sess = tf.Session()
# Initialize the variables (like the epoch counter)
sess.run(init_op)
# Start input enqueue threads.
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
try:
while not coord.should_stop():
# Run training steps or whatever
sess.run(train_op)
except tf.errors.OutOfRangeError:
print('Done training -- epoch limit reached')
finally:
# When done, ask the threads to stop
coord.request_stop()
# Wait for threads to finish
coord.join(threads)
sess.close()內部工作原理(很重要!)
首先我們會先建立一個圖,裡面有一些佇列連線起來的流水線階段。第一個階段會產生檔名來讀取然後檔名會入隊到檔名佇列中(第一個佇列)。第二個階段第二個階段使用檔名(使用Reader)來產生樣本,然後把樣本入隊到樣本佇列中。根據你的設定方式,你可能實際上會在第二階段有一些獨立的樣本使得你可以並行地讀取。在這些階段的最後是一個入隊操作,入隊進入到下一階段的出隊的佇列。下面我們就要開啟執行緒來執行這些入隊操作, 這樣我們就可以在訓練迴圈裡不斷將樣本佇列裡的樣本取出來進行訓練。
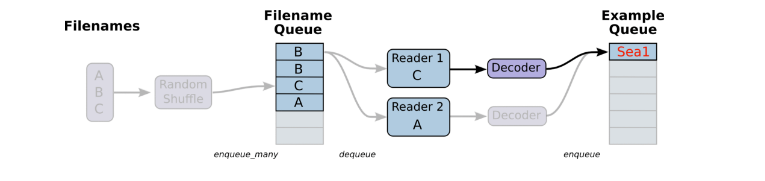
為了建立這些佇列和入隊的操作我們需要使用tf.train.add_queue_runner函式將tf.train.QueueRunner新增到圖中。每個QueueRunner負責一個階段,擁有將被執行緒執行的入隊操作的列表。一旦圖被建立起來,tf.train.start_queue_runners函式會讓每一個在圖中的QueueRunner開啟它們的執行緒來執行入隊操作。
如果一切正常,當執行訓練過程時佇列將會被背景的執行緒很快地填充。如果我們設定了訓練輪數限制,在某個企圖出隊樣本的節點,你會得到一個錯誤tf.errors.OutOfRangeError。這可以理解為TensorFlow中的end of file(EOF)
最後一個組成部分就是tf.train.Coordinator。這個負責來讓所有的執行緒知道是否有訊號關閉。大多數情況下異常發生時,才會出現這種現象。
預先載入資料
這種方法僅對於小的資料集比較合適,它們會被整
個載入進記憶體。這裡有兩種方式:
- 將資料存入常量(constant)
- 將資料存入變數,然後你對其進行初始化(或者賦值)然後就不會改變
1.使用常量會比較簡單,但是需要更多的記憶體(因為常量被內聯地儲存在圖資料結構中,可能會被複制多次)
2.使用變數則需要在圖被建立後進行初始化。設定trainable=False保持變數在圖中GraphKeys.TRAINABLE_VARIABLES集合之外,因此我們不會在訓練過程中更新它。設定collections=[]保持變數在GraphKeys.GLOBAL_VARIABLES集合外,用於儲存和恢復檢查點。
無論哪種方式,tf.train.slice_input_producer可以被用來產生一次切片。這個將會在一個完整的epoch內打亂樣本,所以之後在batching時打亂是不必要的。因此我們使用tf.train.batch函式而不是shuffle_batch函式。為了使用多個預處理執行緒,設定num_threads引數大於1。
下面是兩個MNIST預先載入資料的例子,第一個是使用常量第二個是使用變數。
MNIST預處理使用常量
MNIST預處理使用變數
多輸入流水線
通常來說你想要訓練一個數據集然後對另一個評價,一種方式去實現是在可能獨立的程序中有兩個獨立的圖和會話:
1.訓練過程讀取輸入訓練輸入資料,定期將所有訓練變數寫入檢查點檔案。
2.評價過程恢復檢查點檔案到預測模型,讀取驗證輸入資料。
在CIFAR-10示例模型中,這就是評價器和手動完成的工作,這有很多好處:
1.eval是在已經訓練好的變數單個快照上執行的。
2.當訓練已經完成並且退出後,你仍然可以執行eval操作。
你可以在同一程序同一圖中進行訓練和評價,並且共享它們的變數或者網路層。詳見共享變數的指南。共享變數
為了支援單獨一個圖的方法,tf.data也支援advanced iterator types,它允許使用者不用在重建圖或者會話的基礎上,改變輸入流水線。
Note:無所謂實現,很多操作(像tf.layers.batch_normalization和tf.layers.dropout)需要知道它們是處於訓練模式還是評價模式,如果你要改變資料來源你需要小心的設定