
[親測]SpringCloud之均衡Ribbon
一.負載均衡Ribbon
什麼是Ribbon:

接下來,我們就來使用Ribbon實現負載均衡。
1.1.啟動兩個服務例項
首先我們啟動兩個user-service例項,一個8090,一個8092。
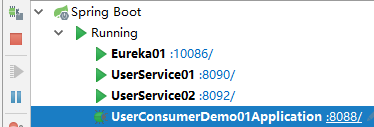
Eureka監控面板:

1.2.開啟負載均衡
因為Eureka中已經集成了Ribbon,所以我們無需引入新的依賴。直接修改程式碼:
在RestTemplate的配置方法上新增@LoadBalanced註解:
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new 修改呼叫方式,不再手動獲取ip和埠,而是直接通過服務名稱呼叫:
@Service
public class UserService {
@Autowired
private RestTemplate restTemplate;
@Autowired
private DiscoveryClient discoveryClient;
public List<User> queryUserByIds(List<Long> ids) {
List<User> 訪問頁面,檢視結果:

完美!
1.3.原始碼跟蹤
為什麼我們只輸入了service名稱就可以訪問了呢?之前還要獲取ip和埠。
顯然有人幫我們根據service名稱,獲取到了服務例項的ip和埠。它就是LoadBalancerInterceptor
我們進行原始碼跟蹤:(Debug執行user-consumer-demo專案)

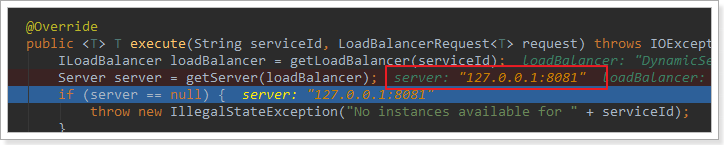
繼續跟入execute方法:發現獲取了8082埠的服務

再跟下一次,發現獲取的是8081:
1.4.負載均衡策略
Ribbon預設的負載均衡策略是簡單的輪詢,我們可以測試一下:
編寫測試類,在剛才的原始碼中我們看到攔截中是使用RibbonLoadBalanceClient來進行負載均衡的,其中有一個choose方法,是這樣介紹的:
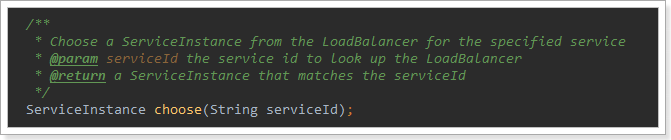
現在這個就是負載均衡獲取例項的方法。
我們對注入這個類的物件,然後對其測試:
@RunWith(SpringRunner.class)
@SpringBootTest(classes = UserConsumerDemoApplication.class)
public class LoadBalanceTest {
@Autowired
RibbonLoadBalancerClient client;
@Test
public void test(){
for (int i = 0; i < 100; i++) {
ServiceInstance instance = this.client.choose("user-service");
System.out.println(instance.getHost() + ":" + instance.getPort());
}
}
}
結果:

符合了我們的預期推測,確實是輪詢方式。
我們是否可以修改負載均衡的策略呢?
繼續跟蹤原始碼,發現這麼一段程式碼:

我們看看這個rule是誰:

這裡的rule預設值是一個RoundRobinRule,看類的介紹:
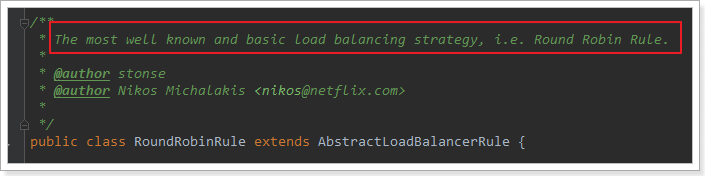
這不就是輪詢的意思嘛。
我們注意到,這個類其實是實現了介面IRule的,檢視一下:

定義負載均衡的規則介面。
它有以下實現:

SpringBoot也幫我們提供了修改負載均衡規則的配置入口:

user-service:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
格式是:{服務名稱}.ribbon.NFLoadBalancerRuleClassName,值就是IRule的實現類。
再次測試,發現結果變成了隨機:

1.5.CAP
CAP原則:CAP原則又稱CAP定理,指的是在一個分散式系統中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分割槽容錯性),三者不可兼得
1.5.1 分割槽容錯性
大多數分散式系統都分佈在多個子網路。每個子網路就叫做一個區(partition)。分割槽容錯的意思是,區間通訊可能失敗。比如,一臺伺服器放在中國,另一臺伺服器放在美國,這就是兩個區,它們之間可能無法通訊。

上圖中,G1 和 G2 是兩臺跨區的伺服器。G1 向 G2 傳送一條訊息,G2 可能無法收到。系統設計的時候,必須考慮到這種情況。
一般來說,分割槽容錯無法避免,因此可以認為 CAP 的 P 總是成立。CAP 定理告訴我們,剩下的 C 和 A 無法同時做到。
1.5.2 一致性
Consistency 中文叫做"一致性"。意思是,寫操作之後的讀操作,必須返回該值。舉例來說,某條記錄是 v0,使用者向 G1 發起一個寫操作,將其改為 v1。

接下來,使用者的讀操作就會得到 v1。這就叫一致性。

問題是,使用者有可能向 G2 發起讀操作,由於 G2 的值沒有來得及發生變化,因此返回的是 v0。G1 和 G2 讀操作的結果不一致,這就不滿足一致性了。

為了讓 G2 也能變為 v1,就要在 G1 寫操作的時候,讓 G1 向 G2 傳送一條訊息,要求 G2 也改成 v1。

這樣的話,使用者向 G2 發起讀操作,也能得到 v1。

1.5.3 可用性
Availability 中文叫做"可用性",意思是隻要收到使用者的請求,伺服器就必須給出迴應。
使用者可以選擇向 G1 或 G2 發起讀操作。不管是哪臺伺服器,只要收到請求,就必須告訴使用者,到底是 v0 還是 v1,否則就不滿足可用性。
1.5.4 一致性和可用性的矛盾
一致性和可用性,為什麼不可能同時成立?答案很簡單,因為可能通訊失敗(即出現分割槽容錯)。
如果保證 G2 的一致性,那麼 G1 必須在寫操作時,鎖定 G2 的讀操作和寫操作。只有資料同步後,才能重新開放讀寫。鎖定期間,G2 不能讀寫,沒有可用性。
如果保證 G2 的可用性,那麼勢必不能鎖定 G2,所以一致性不成立。
綜上所述,G2 無法同時做到一致性和可用性。系統設計時只能選擇一個目標。如果追求一致性,那麼無法保證所有節點的可用性;如果追求所有節點的可用性,那就沒法做到一致性。
1.6.重試機制
Eureka的服務治理強調了CAP原則中的AP,即可用性和可靠性。它與Zookeeper這一類強調CP(一致性,分割槽容錯)的服務治理框架最大的區別在於:Eureka為了實現更高的服務可用性,犧牲了一定的一致性,極端情況下它寧願接收故障例項也不願丟掉健康例項,正如我們上面所說的自我保護機制。
但是,此時如果我們呼叫了這些不正常的服務,呼叫就會失敗,從而導致其它服務不能正常工作!這顯然不是我們願意看到的。
我們現在關閉一個user-service例項:

因為服務剔除的延遲,consumer並不會立即得到最新的服務列表,此時再次訪問你會得到錯誤提示:

但是此時,8081服務其實是正常的。
因此Spring Cloud 整合了Spring Retry 來增強RestTemplate的重試能力,當一次服務呼叫失敗後,不會立即丟擲異常,而是再次重試另一個服務。
只需要(user-consumer)簡單配置即可實現Ribbon的重試:
spring:
cloud:
loadbalancer:
retry:
enabled: true # 開啟Spring Cloud的重試功能
user-service:
ribbon:
ConnectTimeout: 250 # Ribbon的連線超時時間
ReadTimeout: 1000 # Ribbon的資料讀取超時時間
OkToRetryOnAllOperations: true # 是否對所有操作都進行重試
MaxAutoRetriesNextServer: 1 # 切換例項的重試次數
MaxAutoRetries: 1 # 對當前例項的重試次數
根據如上配置,當訪問到某個服務超時後,它會再次嘗試訪問下一個服務例項,如果不行就再換一個例項,如果不行,則返回失敗。切換次數取決於MaxAutoRetriesNextServer引數的值
引入spring-retry依賴
<dependency>
<groupId>org.springframework.retry</groupId>
<artifactId>spring-retry</artifactId>
</dependency>
我們重啟user-consumer-demo,測試,發現即使user-service2宕機,也能通過另一臺服務例項獲取到結果!

再給大家推薦本人的另外一篇文章:
SpringCloud之熔斷器Hystrix+實踐