
11 非阻塞式伺服器
即使你知道Java NIO 非阻塞的工作特性(如Selector,Channel,Buffer等元件),但是想要設計一個非阻塞的伺服器仍然是一件很困難的事。非阻塞式伺服器相較於阻塞式來說要多上許多挑戰。本文將會討論非阻塞式伺服器的主要幾個難題,並針對這些難題給出一些可能的解決方案。
查詢關於非阻塞式伺服器設計方面的資料實在不太容易,所以本文提供的解決方案都是基於本人工作和想法上的。如果各位有其他的替代方案或者更好的想法,我會很樂意聽取這些方案和想法!
本文的設計思路想法都是基於Java NIO的。但是我相信如果某些語言中也有像Selector之類的元件的話,文中的想法也能用於該語言。據我所知,類似的元件底層作業系統會提供,所以對你來說也可以根據其中的思想運用在其他語言上。
非阻塞式伺服器– GitHub 倉庫
我已經建立了一些簡單的這些思想的概念驗證呈現在這篇教程中,並且為了讓你可以看到,我把原始碼放到了github資源庫上了。這裡是GitHub資源庫地址:https://github.com/jjenkov/java-nio-server。(此github倉庫不是本人的,所以只是轉載學習)
非阻塞式IO管道(Pipelines)
一個非阻塞式IO管道是由各個處理非阻塞式IO元件組成的鏈。其中包括讀/寫IO。下圖就是一個簡單的非阻塞式IO管道組成:

一個元件使用 Selector監控Channel 什麼時候有可讀資料。然後這個元件讀取輸入並且根據輸入生成相應的輸出。最後輸出將會再次寫入到一個Channel中。
一個非阻塞式IO管道不需要將讀資料和寫資料都包含,有一些管道可能只會讀資料,另一些可能只會寫資料。
上圖僅顯示了一個單一的元件。一個非阻塞式IO管道可能擁有超過一個以上的元件去處理輸入資料。一個非阻塞式管道的長度是由他的所要完成的任務決定。
一個非阻塞IO管道可能同時讀取多個Channel裡的資料。舉個例子:從多個SocketChannel管道讀取資料。
其實上圖的控制流程還是太簡單了。這裡是元件從Selector開始從Channel中讀取資料,而不是Channel將資料推送給Selector進入元件中,即便上圖畫的就是這樣。
非阻塞式vs. 阻塞式管道
非阻塞和阻塞IO管道兩者之間最大的區別
IO管道通常從流中讀取資料(來自socket或者file)並且將這些資料拆分為一系列連貫的訊息。這和使用tokenizer(這裡估計是解析器之類的意思)將資料流解析為token(這裡應該是資料包的意思)類似。相反,你只是將資料流分解為更大的訊息體。我將拆分資料流成訊息這一元件稱為“訊息讀取器”(Message Reader)下面是Message Reader拆分流為訊息的示意圖:

一個阻塞IO管道可以使用類似InputStream的介面每次一個位元組地從底層Channel讀取資料,並且這個介面阻塞直到有資料可以讀取。這就是阻塞式Message Reader的實現過程。
使用阻塞式IO介面簡化了Message Reader的實現。阻塞式Message Reader從不用處理在流沒有資料可讀的情況,或者它只讀取流中的部分資料並且對於訊息的恢復也要延遲處理的情況。
同樣,阻塞式Message Writer(一個將資料寫入流中元件)也從不用處理只有部分資料被寫入和寫入訊息要延遲恢復的情況。
阻塞式IO管道的缺陷
雖然阻塞式Message Reader容易實現,但是也有一個不幸的缺點:每一個要分解成訊息的流都需要一個獨立的執行緒。必須要這樣做的理由是每一個流的IO介面會阻塞,直到它有資料讀取。這就意味著一個單獨的執行緒是無法嘗試從一個沒有資料的流中讀取資料轉去讀另一個流。一旦一個執行緒嘗試從一個流中讀取資料,那麼這個執行緒將會阻塞直到有資料可以讀取。
如果IO管道是必須要處理大量併發連結伺服器的一部分的話,那麼伺服器就需要為每一個連結維護一個執行緒。對於任何時間都只有幾百條併發連結的伺服器這確實不是什麼問題。但是如果伺服器擁有百萬級別的併發連結量,這種設計方式就沒有良好收放。每個執行緒都會佔用棧32bit-64bit的記憶體。所以一百萬個執行緒佔用的記憶體將會達到1TB!不過在此之前伺服器將會把所有的記憶體用以處理傳經來的訊息(例如:分配給訊息處理期間使用物件的記憶體)
為了將執行緒數量降下來,許多伺服器使用了伺服器維持執行緒池(例如:常用執行緒為100)的設計,從而一次一個地從入站連結(inbound connections)地讀取。入站連結儲存在一個佇列中,執行緒按照進入佇列的順序處理入站連結。這一設計如下圖所示:(譯者注:Tomcat就是這樣的)

然而,這一設計需要入站連結合理地傳送資料。如果入站連結長時間不活躍,那麼大量的不活躍連結實際上就造成了執行緒池中所有執行緒阻塞。這意味著伺服器響應變慢甚至是沒有反應。
一些伺服器嘗試通過彈性控制執行緒池的核心執行緒數量這一設計減輕這一問題。例如,如果執行緒池執行緒不足時,執行緒池可能開啟更多的執行緒處理請求。這一方案意味著需要大量的長時連結才能使伺服器不響應。但是記住,對於併發執行緒數任然是有一個上限的。因此,這一方案仍然無法很好地解決一百萬個長時連結。
基礎非阻塞式IO管道設計
一個非阻塞式IO管道可以使用一個單獨的執行緒向多個流讀取資料。這需要流可以被切換到非阻塞模式。在非阻塞模式下,當你讀取流資訊時可能會返回0個位元組或更多位元組的資訊。如果流中沒有資料可讀就返回0位元組,如果流中有資料可讀就返回1+位元組。
為了避免檢查沒有可讀資料的流我們可以使用 Java NIO Selector. 一個或多個SelectableChannel例項可以同時被一個Selector註冊.。當你呼叫Selector的select()或者selectNow()方法它只會返回有資料讀取的SelectableChannel的例項. 下圖是該設計的示意圖:
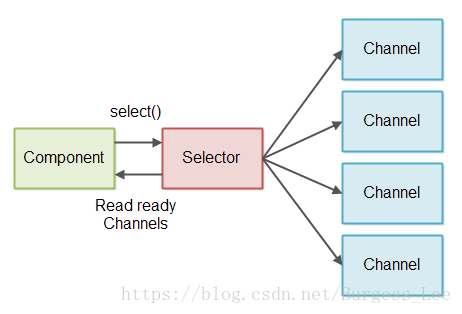
讀取部分訊息
當我們從一個SelectableChannel讀取一個數據包時,我們不知道這個資料包相比於原始檔是否有丟失或者重複資料(原文是:When we read a block of data from a SelectableChannel we do not know if that data block contains less or more than a message)。一個數據包可能的情況有:缺失資料(比原有訊息的資料少)、與原有一致、比原來的訊息的資料更多(例如:是原來的1.5或者2.5倍)。資料包可能出現的情況如下圖所示:
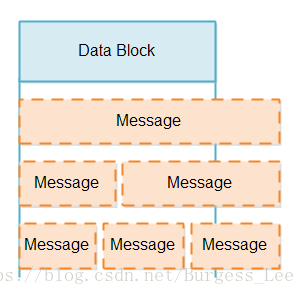
在處理類似上面這樣部分資訊時,有兩個問題:
- 判斷你是否能在資料包中獲取完整的訊息。
- 在其餘訊息到達之前如何處理已到達的部分訊息。
判斷訊息的完整性需要訊息讀取器(Message Reader)在資料包中尋找是否存在至少一個完整訊息體的資料。如果一個數據包包含一個或多個完整訊息體,這些訊息就能夠被髮送到管道進行處理。尋找完整訊息體這一處理可能會重複多次,因此這一操作應該儘可能的快。
判斷訊息完整性和儲存部分訊息都是訊息讀取器(Message Reader)的責任。為了避免混合來自不同Channel的訊息,我們將對每一個Channel使用一個Message Reader。設計如下圖所示:
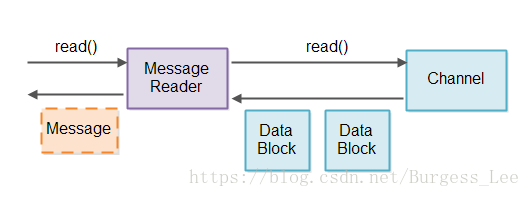
在從Selector得到可從中讀取資料的Channel例項之後, 與該Channel相關聯的Message Reader讀取資料並嘗試將他們分解為訊息。這樣讀出的任何完整訊息可以被傳到讀取通道(read pipeline)任何需要處理這些訊息的元件中。
一個Message Reader一定滿足特定的協議。Message Reader需要知道它嘗試讀取的訊息的訊息格式。如果我們的伺服器可以通過協議來複用,那它需要有能夠插入Message Reader實現的功能 – 可能通過接收一個Message Reader工廠作為配置引數。
儲存部分訊息
現在我們已經確定Message Reader有責任儲存部分訊息,直到收到完整的訊息,我們需要弄清楚這些部分訊息的儲存應該如何實現。
有兩個設計因素我們要考慮:
- 我們想盡可能少地複製訊息資料。複製越多,效能越低。
- 我們希望將完整的訊息儲存在連續的位元組序列中,使解析訊息更容易。
每個Message Reader的緩衝區
很顯然部分訊息需要儲存某些緩衝區中。簡單的實現方式可以是每一個Message Reader內部簡單地有一個緩衝區。但是這個緩衝區應該多大?它要大到足夠儲存最大允許儲存訊息。因此,如果最大允許儲存訊息是1MB,那麼Message Reader內部緩衝區將至少需要1MB。
當我們的連結達到百萬數量級,每個連結都使用1MB並沒有什麼作用。1,000,000 * 1MB仍然是1TB的記憶體!那如果最大的訊息是16MB甚至是128MB呢?
大小可調的緩衝區
另一個選擇是在Message Reader內部實現一個大小可調的緩衝區。大小可調的緩衝區開始的時候很小,如果它獲取的訊息過大,那緩衝區會擴大。這樣每一條連結就不一定需要如1MB的緩衝區。每條連結的緩衝區只要需要足夠儲存下一條訊息的記憶體就行了。
有幾個可實現可調大小緩衝區的方法。它們都各自有自己的優缺點,所以接下來的部分我將逐個討論。
通過複製調整大小
實現可調大小緩衝區的第一種方式是從一個大小(例如:4KB)的緩衝區開始。如果4KB的緩衝區裝不下一個訊息,則會分配一個更大的緩衝區(如:8KB),並將大小為4KB的緩衝區資料複製到這個更大的緩衝區中去。
通過複製實現大小可調緩衝區的優點在於訊息的所有資料被儲存在一個連續的位元組陣列中,這就使得訊息的解析更加容易。它的缺點就是在複製更大訊息的時候會導致大量的資料。
為了減少訊息的複製,你可以分析流進你係統的訊息的大小,並找出儘量減少複製量的緩衝區的大小。例如,你可能看到大多數訊息都小於4KB,這是因為它們都僅包含很小的 request/responses。這意味著緩衝區的初始值應該設為4KB。
然後你可能有一個訊息大於4KB,這通常是因為它裡面包含一個檔案。你可能注意到大多數流進系統的檔案都是小於128KB的。這樣第二個緩衝區的大小設定為128KB就較為合理。
最後你可能會發現一旦訊息超過128KB之後,訊息的大小就沒有什麼固定的模式,因此緩衝區最終的大小可能就是最大訊息的大小。
根據流經系統的訊息大小,上面三種緩衝區大小可以減少資料的複製。小於4KB的訊息將不會複製。對於一百萬個併發連結其結果是:1,000,000 * 4KB = 4GB,對於目前大多數伺服器還是有可能的。介於4KB – 128KB的訊息將只會複製一次,並且只有4KB的資料複製進128KB的緩衝區中。介於128KB至最大訊息大小的訊息將會複製兩次。第一次複製4KB,第二次複製128KB,所以最大的訊息總共複製了132KB。假設沒有那麼多超過128KB大小的訊息那還是可以接受的。
一旦訊息處理完畢,那麼分配的記憶體將會被清空。這樣在同一連結接收到的下一條訊息將會再次從最小緩衝區大小開始算。這樣做的必要性是確保了不同連線間記憶體的有效共享。所有的連線很有可能在同一時間並不需要打的緩衝區。
我有一篇介紹如何實現這樣支援可調整大小的陣列的記憶體緩衝區的完整文章:
文章包含一個GitHub倉庫連線,其中的程式碼演示了是如何實現的。
通過追加調整大小
調整緩衝區大小的另一種方法是使緩衝區由多個數組組成。當你需要調整緩衝區大小時,你只需要另一個位元組陣列並將資料寫進去就行了。
這裡有兩種方法擴張一個緩衝區。一個方法是分配單獨的位元組陣列,並將這些陣列儲存在一個列表中。另一個方法是分配較大的共享位元組陣列的片段,然後保留分配給緩衝區的片段的列表。就個人而言,我覺得片段的方式會好些,但是差別不大。
通過追加單獨的陣列或片段來擴充套件緩衝區的優點在於寫入過程中不需要複製資料。所有的資料可以直接從socket (Channel)複製到一個數組或片段中。
以這種方式擴充套件緩衝區的缺點是在於資料不是儲存在單獨且連續的陣列中。這將使得訊息的解析更困難,因為解析器需要同時查詢每個單獨陣列的結尾處和所有陣列的結尾處。由於你需要在寫入的資料中查詢訊息的結尾,所以該模型並不容易使用。
TLV編碼訊息
一些協議訊息格式是使用TLV格式(型別(Type)、長度(Length)、值(Value))編碼。這意味著當訊息到達時,訊息的總長度被儲存在訊息的開頭。這一方式你可以立即知道應該對整個訊息分配多大的記憶體。
TLV編碼使得記憶體管理變得更加容易。你可以立即知道要分配多大的記憶體給這個訊息。只有部分在結束時使用的緩衝區才會使得記憶體浪費。
TLV編碼的一個缺點是你要在訊息的所有資料到達之前就分配好這個訊息需要的所有記憶體。一些慢連線可能因此分配完你所有可用記憶體,從而使得你的伺服器無法響應。
此問題的解決方法是使用包含多個TLV欄位的訊息格式。因此,伺服器是為每個欄位分配記憶體而不是為整個訊息分配記憶體,並且是欄位到達之後再分配記憶體。然而,一個大訊息中的一個大欄位在你的記憶體管理有同樣的影響。
另外一個方案就是對於還未到達的資訊設定超時時間,例如10-15秒。當恰好有許多大訊息到達伺服器時,這個方案能夠使得你的伺服器可以恢復,但是仍然會造成伺服器一段時間無法響應。另外,惡意的DoS(Denial of Service拒絕服務)攻擊仍然可以分配完你伺服器的所有記憶體。
TLV編碼存在許多不同的形式。實際使用的位元組數、自定欄位的型別和長度都依賴於每一個TLV編碼。TLV編碼首先放置欄位的長度、然後是型別、然後是值(一個LTV編碼)。 雖然欄位的順序不同,但它仍然是TLV的一種。
TLV編碼使記憶體管理更容易這一事實,其實是HTTP 1.1是如此可怕的協議的原因之一。 這是他們試圖在HTTP 2.0中修復資料的問題之一,資料在LTV編碼幀中傳輸。 這也是為什麼我們使用TLV編碼的VStack.co project 設計了我們自己的網路協議。
寫部分資料
在非阻塞IO管道中寫資料仍然是一個挑戰。當你呼叫一個處於非阻塞式Channel物件的write(ByteBuffer)方法時,ByteBuffer寫入多少資料是無法保證的。write(ByteBuffer)方法會返回寫入的位元組數,因此可以跟蹤寫入的位元組數。這就是挑戰:跟蹤部分寫入的訊息,以便最終可以傳送一條訊息的所有位元組。
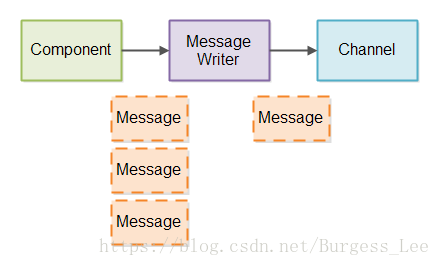
為了管理部分訊息寫入Channel,我們將建立一個訊息寫入器(Message Writer)。就像Message Reader一樣,每一個要寫入訊息的Channel我們都需要一個Message Writer。在每個Message Writer中,我們跟蹤正在寫入的訊息的位元組數。
如果達到的訊息量超過Message Writer可直接寫入Channel的訊息量,訊息就需要在Message Writer排隊。然後Message Writer儘快地將訊息寫入到Channel中。
下圖是部分訊息如何寫入的設計圖:
為了使Message Writer能夠儘快傳送資料,Message Writer需要能夠不時被呼叫,這樣就能傳送更多的訊息。
如果你有大量的連線,那你將需要大量的Message Writer例項。檢查Message Writer例項(如:一百萬個)看寫任何資料時是否緩慢。 首先,許多Message Writer例項都沒有任何訊息要傳送,我們並不想檢查那些Message Writer例項。其次,並不是所有的Channel例項都可以準備好寫入資料。 我們不想浪費時間嘗試將資料寫入無法接受任何資料的Channel。
為了檢查Channel是否準備好進行寫入,您可以使用Selector註冊Channel。然而我們並不想將所有的Channel例項註冊到Selector中去。想象一下,如果你有1,000,000個連線且其中大多是空閒的,並且所有的連線已經與Selector註冊。然後當你呼叫select()時,這些Channel例項的大部分將被寫入就緒(它們大都是空閒的,記得嗎?)然後你必須檢查所有這些連線的Message Writer,以檢視他們是否有任何資料要寫入。
為了避免檢查所有訊息的Message Writer例項和所有不可能被寫入任何資訊的Channel例項,我們使用這兩步的方法:
- 當一個訊息被寫入Message Writer,Message Writer向Selector註冊其相關Channel(如果尚未註冊)。
- 當你的伺服器有時間時,它檢查Selector以檢視那些註冊的Channel例項已準備好進行寫入。 對於每個寫就緒Channel,請求其關聯的Message Writer將資料寫入Channel。 如果Message Writer將其所有訊息寫入其Channel,則Channel將再次從Selector註冊。
這兩個小步驟確保了有訊息寫入的Channel實際上已經被Selector註冊了。
彙總、
正如你所見,一個非阻塞式伺服器需要時不時檢查輸入的訊息來判斷是否有任何的新的完整的訊息傳送過來。伺服器可能會在一個或多個完整訊息發來之前就檢查了多次。檢查一次是不夠的。
同樣,一個非阻塞式伺服器需要時不時檢查是否有任何資料需要寫入。如果有,伺服器需要檢查是否有任何相應的連線準備好將該資料寫入它們。只有在第一次排隊訊息時才檢查是不夠的,因為訊息可能被部分寫入。
所有這些非阻塞伺服器最終都需要定期執行的三個“管道”(pipelines)::
- 讀取管道(The read pipeline),用於檢查是否有新資料從開放連線進來的。
- 處理管道(The process pipeline),用於所有任何完整訊息。
- 寫入管道(The write pipeline),用於檢查是否可以將任何傳出的訊息寫入任何開啟的連線。
這三條管道在迴圈中重複執行。你可能可以稍微優化執行。例如,如果沒有排隊的訊息可以跳過寫入管道。 或者,如果我們沒有收到新的,完整的訊息,也許您可以跳過流程管道。
以下是說明完整伺服器迴圈的圖:
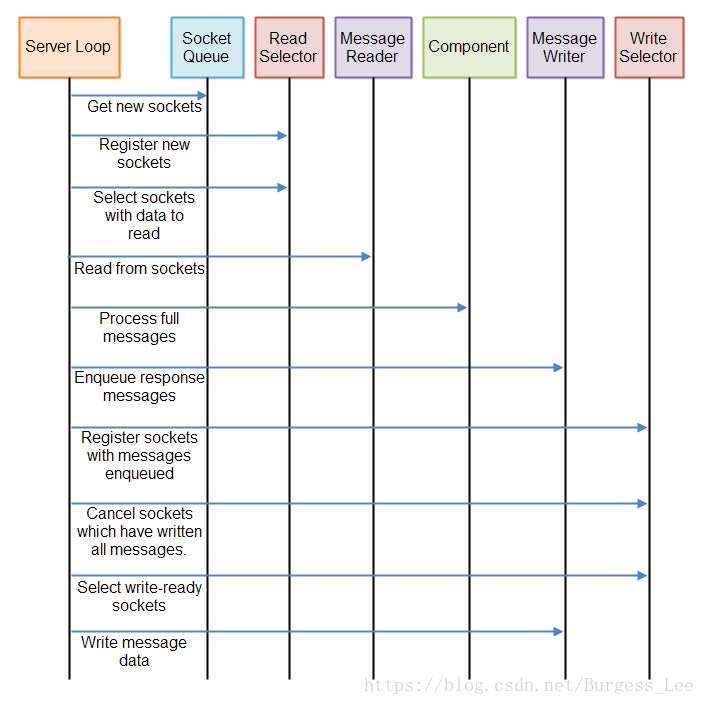
也許看到正在執行的程式碼可能會幫助你瞭解如何實現這一點。
伺服器執行緒模型
GitHub資源庫裡面的非阻塞式伺服器實現使用了兩個執行緒的執行緒模式。第一個執行緒用來接收來自ServerSocketChannel的傳入連線。第二個執行緒處理接受的連線,意思是讀取訊息,處理訊息並將響應寫回連線。這兩個執行緒模型的圖解如下:
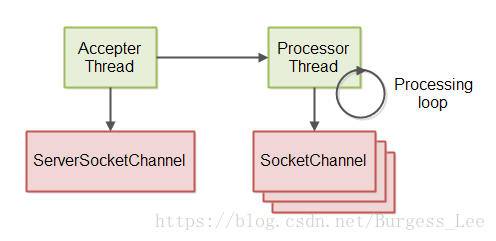
上一節中說到的伺服器迴圈處理是由處理執行緒(Processor Thread)執行。
此章節主要對非阻塞伺服器的實現過程進行的圖文講解。主要有兩個元件:訊息讀取器和訊息寫入器,分別針對兩個元件的實現給出自己的想法和設計,並提供有相應的倉庫地址。雖然有些地方看的不是很透徹,但是基本能瞭解作者的思路,詳細實現過程請自行下載。