
Python下的多執行緒處理
########多執行緒#########
## 執行緒的概念與多執行緒的引入
一個標準的執行緒由執行緒ID,當前指令指標(PC),暫存器集合和堆疊組成。另外,執行緒是程序中的一個實體,一個程序裡面必然會有一個主執行緒,是被系統獨立排程和分派的基本單位,執行緒自己不擁有系統資源,只擁有一點兒在執行中必不可少的資源,但它可與同屬一個程序的其它執行緒共享程序所擁有的全部資源。
多執行緒,是指從軟體或者硬體上實現多個執行緒併發執行的技術。具有多執行緒能力的計算機因有硬體支援而能夠在同一時間執行多於一個執行緒,進而提升整體處理效能。
## python中多執行緒的操作
## 建立執行緒
# 1. 管理執行緒的模組: _thread, threading # 2. _thread建立多執行緒: _thread.start_new_thread(執行緒需要執行的任務,(任務需要的引數, 元組資料型別 )) # 3. threading建立多執行緒第一種方式:例項化一個物件(Thread) t1 = threading.Thread(target=任務函式名, args=(x1,x2), name='threadName') # 4. 啟動執行緒: t.start()
""" 建立執行緒的模組 _thread模組 threading模組(常用) """ import threading import time def job(): time.sleep(1) print("正在執行的任務") # 啟用的執行緒個數 print("當前執行緒的個數:", threading.active_count()) # 列印當前執行緒的詳細資訊 print("當前執行緒的資訊:", threading.current_thread()) if __name__ == "__main__": # 執行函式 job() # 建立執行緒 並開始執行執行緒 t1 = threading.Thread(target=job, name="Job1", args=()) ## 可見Thread是一個類,需要修改一些預設引數 t2 = threading.Thread(target=job, name="Job2", args=()) # 使用start方法開始程序 t1.start() t2.start()

## 多執行緒與join方法
- join方法: 在使用多執行緒時,會等使用該方法的待執行緒結束之後,再執行其他執行緒,作用就是阻塞正在呼叫的其它執行緒。
import threading import time def readBook(name): time.sleep(1) print("正在讀%s" % name) def music(name): time.sleep(1) print("正在唱%s" % name) if __name__ == "__main__": t1 = threading.Thread(target=readBook, name=readBook, args=("python36",)) t2 = threading.Thread(target=music, name=(music), args=("雙截棍",)) t1.start() t2.start() # 在不使用join方法時直接執行程式,可見主執行緒先執行,t1,t2併發執行 # 主程式 print(time.ctime())

使用join方法:
import threading
import time
def readBook(name):
time.sleep(1)
print("正在讀%s" % name)
def music(name):
time.sleep(1)
print("正在唱%s" % name)
if __name__ == "__main__":
t1 = threading.Thread(target=readBook, name=readBook, args=("python36",))
t2 = threading.Thread(target=music, name=(music), args=("雙截棍",))
t1.start()
t2.start()
# 使用join方法
t1.join()
t2.join()
# 主程式
print(time.ctime())
## 守護執行緒set_daemon
# 當主執行緒執行結束, 讓沒有執行的執行緒強制結束;set_daemon
import threading
import time
# 任務1:
def music(name):
for i in range(2):
time.sleep(1)
print("正在聽音樂%s" %(name))
# 任務2:
def code(name):
for i in range(2):
time.sleep(2)
print("正在編寫程式碼%s" %(name))
if __name__ == '__main__':
start_time = time.time()
# music("中國夢")
# code("爬蟲")
t1 = threading.Thread(target=music, args=("中國夢",))
t2 = threading.Thread(target=code, args=("爬蟲", ))
# 將t1執行緒生命為守護執行緒, 如果設定為True, 子執行緒啟動, 當主執行緒執行結束, 子執行緒也結束
# 設定setDaemon必須在啟動執行緒之前進行設定;
t1.setDaemon(True)
t2.setDaemon(True)
t1.start()
t2.start()
print(time.time() - start_time)

由此可見:執行結果中不會顯示子執行緒的資訊,因為t1,t2均被設定為守護執行緒
## 多執行緒應用下的批量管理主機
pass
等待後續補充內容
## 多執行緒下的獲取IP地理位置
import json
import threading
from urllib.request import urlopen
import time
def job(ip):
"""獲取指定ip對應的地理位置"""
url = "http://ip.taobao.com/service/getIpInfo.php?ip=%s" % ip
# 根據url獲取網頁的內容, 並且解碼為utf-8格式, 識別中文;
text = urlopen(url).read().decode("utf-8")
# 將獲取的字串型別轉換為字典, 方便處理
d = json.loads(text)['data']
country = d['country']
city = d['city']
print("%s:" % ip, country, city)
def many_thread():
start_time = time.time()
threads = []
ips = ['172.25.254.40', '8.8.8.8',
'172.25.254.40', '8.8.8.8',
'172.25.254.40', '8.8.8.8']
for ip in ips:
t = threading.Thread(target=job, args=(ip,))
threads.append(t)
t.start()
[thread.join() for thread in threads]
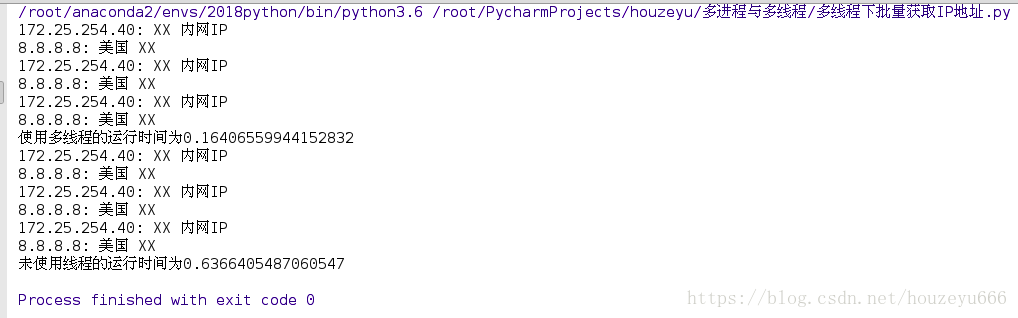
print("使用多執行緒的執行時間為%s" % (time.time() - start_time))
def no_thread():
start_time = time.time()
ips = ['172.25.254.40', '8.8.8.8',
'172.25.254.40', '8.8.8.8',
'172.25.254.40', '8.8.8.8']
for ip in ips:
job(ip)
print("未使用執行緒的執行時間為%s" % (time.time() - start_time))
if __name__ == "__main__":
many_thread()
no_thread()
## 建立執行緒的第二種方法(繼承)
## 類的繼承來實現多執行緒
import threading
class Job(threading.Thread):
# 重寫構造方法
def __init__(self, jobname):
super(Job, self).__init__()
self.jobname = jobname
# 將多執行緒需要執行的任務重寫到run方法中;
def run(self):
print("this is a job")
t1 = Job(jobname="new job")
t1.start()

## 利用類的繼承實現多執行緒獲取IP資訊
import threading
import json
import time
from urllib.error import HTTPError
from urllib.request import urlopen
class IPthread(threading.Thread):
def __init__(self, jobname, ip):
super(IPthread, self).__init__()
self.jobname = jobname
self.ip = ip
def run(self):
try:
# 需要有一個引數, 傳ip;
url = "http://ip.taobao.com/service/getIpInfo.php?ip=%s" % (self.ip)
# 根據url獲取網頁的內容, 並且解碼為utf-8格式, 識別中文;
text = urlopen(url).read().decode('utf-8')
except HTTPError as e:
print("Error: %s獲取地理位置網路錯誤" % (self.ip))
else:
d = json.loads(text)["data"]
country = d['country']
city = d['city']
print("%s" % (self.ip), country, city)
def use_thread():
start_time = time.time()
threads = []
ips = ['172.25.254.40', '8.8.8.8',
'172.25.254.40', '8.8.8.8',
'172.25.254.40', '8.8.8.8']
for ip in ips:
t = IPthread(jobname="爬蟲", ip=ip)
threads.append(t)
t.start()
[thread.join() for thread in threads]
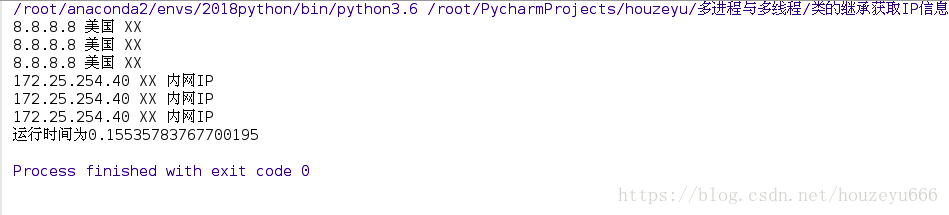
print("執行時間為%s" % (time.time() - start_time))
if __name__ == "__main__":
use_thread()
## 執行緒同步之執行緒鎖
# 多個執行緒對同一個資料進行修改時, 肯能出現不可預料的情況,在執行時由於多個執行緒併發進行,在傳遞資料時會出現資料傳輸錯誤的情況,所以我們在執行時需要加入執行緒所來保證資料的正常傳輸,保證不同執行緒之間不會產生資料干擾
import threading
def add(lock):
# 操作變數之前進行加鎖
lock.acquire()
global money
for i in range(10000000):
money +=1
#操作變數完成後進行解鎖
lock.release()
def reduce(lock):
# 操作變數之前進行加鎖
lock.acquire()
global money
for i in range(10000000):
money -=1
#操作變數完成後進行解鎖
lock.release()
if __name__ == '__main__':
money = 0
# 例項化一個鎖物件
lock = threading.Lock()
t1 = threading.Thread(target=add, args=(lock, ))
t2 = threading.Thread(target=reduce, args=(lock, ))
t1.start()
t2.start()
# 等待所有子執行緒執行結束
t1.join()
t2.join()
print("最終金額:%s" %money)執行結果: 最終金額:0 # 不會產生資料干擾導致錯誤
## GIL全域性直譯器鎖的概念
# python使用多執行緒 , 是個好主意麼? 為什麼? - GIL(全域性直譯器鎖) - python直譯器預設每次只允許一個執行緒執行 執行過程: 1). 設定GIL 2). 切換到執行緒去執行對應的任務; 3). 執行中切換執行緒條件 - 執行完了 - time.sleep() - 獲取其他資訊才能繼續執行, eg: 從網路上獲取網頁資訊等; 3. 把執行緒設定為睡眠狀態 4. 解鎖GIL 5.再次重複執行上述內容; # python直譯器:Cpython直譯器, Jpython直譯器, p-python直譯器
# 方法的選擇: Python並不支援真正意義上的多執行緒。Python中提供了多執行緒包,但是如果你想通過多執行緒提高程式碼的速度, 使用多執行緒包並不是個好主意。Python中有一個被稱為Global Interpreter Lock(GIL)的東西, 它會確保任何時候你的多個執行緒中,只有一個被執行。執行緒的執行速度非常之快,會讓你誤以為執行緒是並行執行的, 但是實際上都是輪流執行。經過GIL這一道關卡處理,會增加執行的開銷。這意味著,如果你想提高程式碼的執行速度, 使用threading包並不是一個很好的方法。 # I/O密集型操作: 多執行緒操作 # CPU/計算密集型:多程序操作
import threading
from 多程序與多執行緒._timeit import mytime
def job(li):
sum(li)
@mytime
def use_thread():
li = range(1,10000)
for i in range(5):
t = threading.Thread(target=job, args=(li, ))
t.start()
@mytime
def use_no_thread():
li = range(1, 10000)
for i in range(5):
job(li)
if __name__ == "__main__":
use_thread()
use_no_thread()## 列隊與多執行緒
# 1). 理論上多執行緒執行任務, 會產生一些資料, 為其他程式執行作鋪墊; # 2). 多執行緒是不能返回任務執行結果的, 因此需要一個容器來儲存多執行緒產生的資料 # 3). 這個容器如何選擇? list(棧, 佇列), tuple(x), set(x), dict(x), 此處選擇佇列來實現
import threading
from queue import Queue
from 多程序與多執行緒._timeit import mytime
def job(l, queue):
# 將任務的結果儲存到佇列中;
queue.put(sum(l))
@mytime
def use_thread():
# 例項化一個佇列, 用來儲存每個執行緒執行的結果;
q = Queue()
threads = []
li = [[1, 5, 7, 3, 6, 2], [5, 23, 4, 6], [7, 8, 93, 2], [1, 2, 3, 4]]
for l in li:
t = threading.Thread(target=job, args=(l, q))
threads.append(t)
t.start()
[thread.join() for thread in threads]
# 從佇列裡面拿出所有的執行結果
result = [q.get() for _ in range(len(li))]
print(result)
if __name__ == "__main__":
use_thread()
## 多執行緒方式實現生產者與消費者模型
# 需求: 給定200個ip地址, 可能開放埠為80, 443, 7001, 7002, 8000, 8080 以http://ip:port形式訪問頁面以判斷是否正常訪問.
1). 構建所有的url地址;===儲存到一個數據結構中 2). 依次判斷url址是否可以成功訪問
import threading
from queue import Queue
from urllib.request import urlopen
def create_data():
with open("ips.txt", "w") as f:
for i in range(200):
f.write("172.25.254.%d\n" % (i + 1))
create_data()
def create_url():
portlist = [80, 443, 7001, 7002, 8000, 8080]
with open("ips.txt") as f:
ips = [ip.strip() for ip in f]
urls = ["http://%s:%s" % (ip, port) for ip in ips for port in portlist]
return urls
class Producer(threading.Thread):
def __init__(self, queue):
super(Producer, self).__init__()
self.queue = queue
def run(self):
portlist = [80, 443, 7001, 7002, 8000, 8080]
with open("ips.txt") as f:
ips = [ip.strip() for ip in f]
# 每生產一個url地址, 就將生產的資料放到佇列裡面;
for ip in ips:
for port in portlist:
url = "http://%s:%s" % (ip, port)
self.queue.put(url)
class Consumer(threading.Thread):
def __init__(self, queue):
super(Consumer, self).__init__()
self.queue = queue
def run(self):
try:
url = self.queue.get()
urlObj = urlopen(url)
except Exception as e:
print("%s unknown url" % url)
else:
print("%s is ok" % url)
if __name__ == "__main__":
# 例項化一個佇列
queue = Queue()
# 一個執行緒物件,生產者
p = Producer(queue)
p.start()
# 消費者啟動多個執行緒(啟動30個)
for i in range(30):
c = Consumer(queue)
c.start()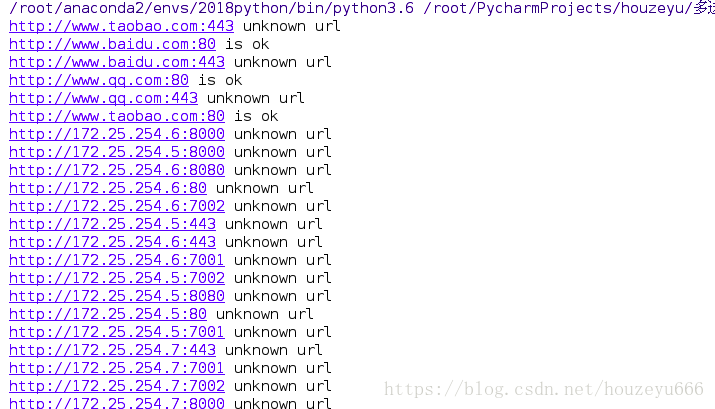
## ThreadPool 執行緒池
# 注意: python3.2版本以後才可以使用; from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import ThreadPoolExecutor
import time
"""
THreadPoolExecutor類的部分原始碼:
class ThreadPoolExecutor(_base.Executor):
# Used to assign unique thread names when thread_name_prefix is not supplied.
_counter = itertools.count().__next__
def __init__(self, max_workers=None, thread_name_prefix=''):
...
def submit(self, fn, *args, **kwargs):
...
"""
def Job():
print("this is a job")
return "hello"
if __name__ == "__main__":
# 例項化物件, 執行緒池包含10個執行緒來處理任務;
pool = ThreadPoolExecutor(max_workers=10)
# 往執行緒池裡面扔需要執行的任務, 返回一個物件,( _base.Future例項化出來的)
f1 = pool.submit(Job)
f2 = pool.submit(Job)
# 判斷任務是否執行結束
print(f1.done())
time.sleep(1)
print(f2.done())
# 獲取任務執行的結果
print(f1.result())
print(f2.result())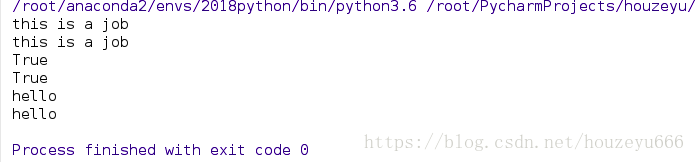
## 執行緒池與map函式
from urllib.error import HTTPError
from urllib.request import urlopen
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import as_completed
import time
URLS = ['http://httpbin.org', 'http://example.com/',
'https://api.github.com/'] * 10
def get_page(url, timeout=3):
try:
content = urlopen(url).read()
return {'url':url, 'len':len(content)}
except HTTPError as e:
return {'url':url, 'len':0}
# 方法1: submit提交任務
# start_time = time.time()
# pool = ThreadPoolExecutor(max_workers=20)
# futuresObj = [pool.submit(get_page, url) for url in URLS]
#
# # 注意: 傳遞的時包含futures物件的序列, as_complete, 返回已經執行完任務的future物件,
# # 直到所有的future對應的任務執行完成, 迴圈結束;
# # for finish_fs in as_completed(futuresObj):
# # print(finish_fs.result() )
#
# for future in futuresObj:
# print(future.result())
#
# print("執行時間:%s" %(time.time()-start_time))
#
# 方法2:通過map方式執行
pool = ThreadPoolExecutor(max_workers=20)
for res in pool.map(get_page, URLS):
print(res)
## 應用練習
需求: 使用生產者消費者模型, 多執行緒爬取指定個url網頁資訊,並多執行緒寫入mysql資料庫中; 要求如下: - 理論上url地址資訊通過其他程式獲取, 此處從一個檔案urls.txt中讀取; - 如果url地址訪問不成功, bytesCount儲存為0; - 資料庫儲存的表頭要求: id(唯一標識碼), url, bytesCount - 獲取url中位元組數最多的10個url(自行查詢相關的SQL語句);
# 附加: 對比多程序和多執行緒的速度;
部分程式碼如下:
# 建立一些指定的網頁資訊
import threading
from queue import Queue
from urllib.request import urlopen
import pymysql
def create_web():
with open("urls.txt", "a+") as f:
f.write("www.taobao.com\n")
f.write("www.baidu.com\n")
f.write("www.qq.com\n")
f.write("172.25.254.40\n")
for i in range(6):
f.write("172.25.254.%d\n" % (i + 1))
# 建立生產者類
class Producer(threading.Thread):
def __init__(self, queue):
super(Producer, self).__init__()
self.queue = queue
def run(self):
portlist = [80]
with open("urls.txt") as f:
ips = [ip.strip() for ip in f]
for ip in ips:
for port in portlist:
url = "http://%s:%s" % (ip, port)
self.queue.put(url)
class Consumer(threading.Thread):
def __init__(self, queue):
super(Consumer, self).__init__()
self.queue = queue
self.bytesCount = 1
def run(self):
try:
url = self.queue.get()
urlObj = urlopen(url)
except Exception as e:
print("%s is error" % url)
self.bytesCount -= 1
return self.bytesCount
else:
print("%s is ok" % url)
return self.bytesCount
if __name__ == "__main__":
# 例項化一個佇列
queue = Queue()
create_web()
# 建立一個生產者模型
p = Producer(queue)
p.start()
p.join()
# 建立消費者模型, 10個執行緒
threads = []
for i in range(10):
t = Consumer(queue)
threads.append(t)
t.start()
[thread.join() for thread in threads]